 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundational Large Language Models for Materials Research
Dec 12, 2024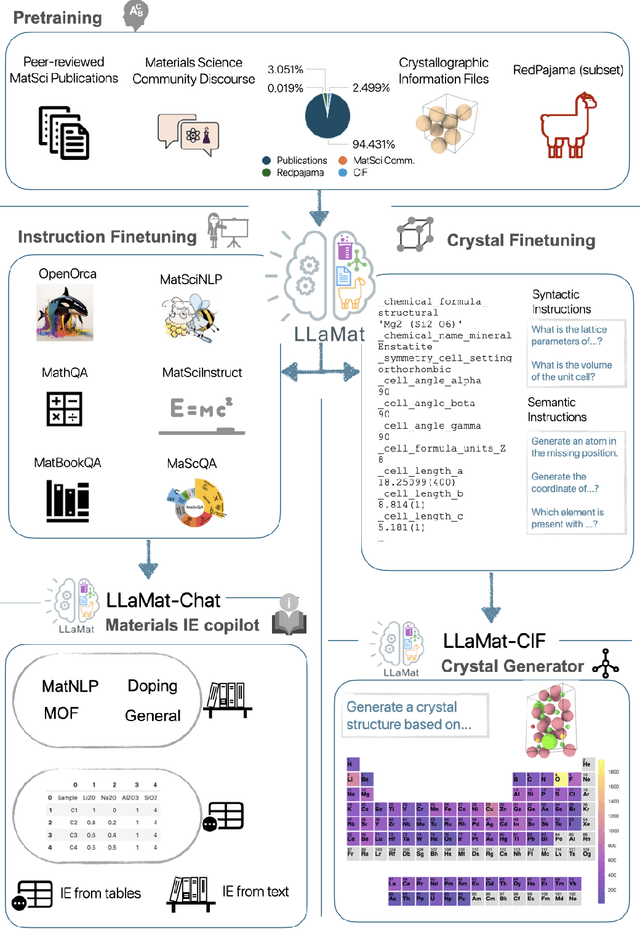
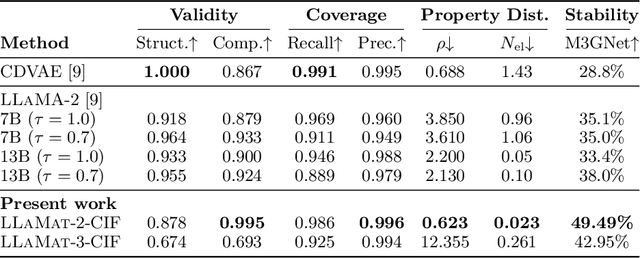
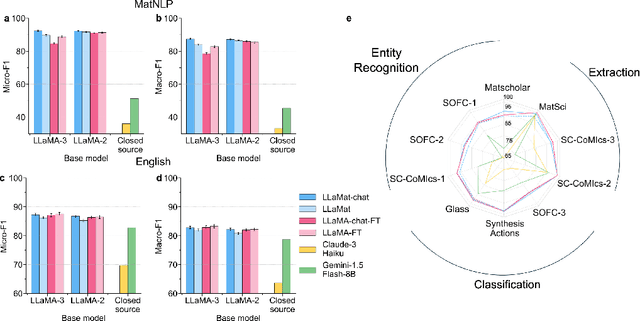
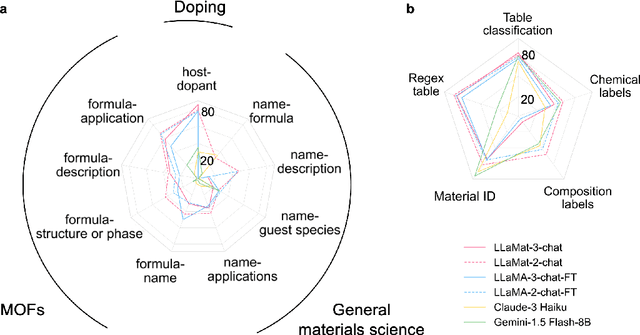
Materials discovery and development are critical for addressing global challenges. Yet, the exponential growth in materials science literature comprising vast amounts of textual data has created significant bottlenecks in knowledge extraction, synthesis, and scientific reasoning. Large Language Models (LLMs) offer unprecedented opportunities to accelerate materials research through automated analysis and prediction. Still, their effective deployment requires domain-specific adaptation for understanding and solving domain-relevant tasks. Here, we present LLaMat, a family of foundational models for materials science developed through continued pretraining of LLaMA models on an extensive corpus of materials literature and crystallographic data. Through systematic evaluation, we demonstrate that LLaMat excels in materials-specific NLP and structured information extraction while maintaining general linguistic capabilities. The specialized LLaMat-CIF variant demonstrates unprecedented capabilities in crystal structure generation, predicting stable crystals with high coverage across the periodic table. Intriguingly, despite LLaMA-3's superior performance in comparison to LLaMA-2, we observe that LLaMat-2 demonstrates unexpectedly enhanced domain-specific performance across diverse materials science tasks, including structured information extraction from text and tables, more particularly in crystal structure generation, a potential adaptation rigidity in overtrained LLMs. Altogether, the present work demonstrates the effectiveness of domain adaptation towards developing practically deployable LLM copilots for materials research. Beyond materials science, our findings reveal important considerations for domain adaptation of LLMs, such as model selection, training methodology, and domain-specific performance, which may influence the development of specialized scientific AI systems.
Probing the limitations of multimodal language models for chemistry and materials research
Nov 25, 2024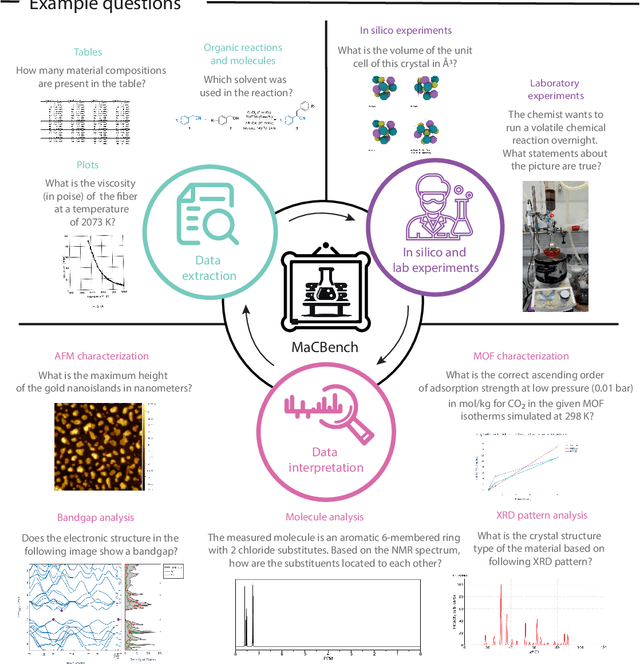
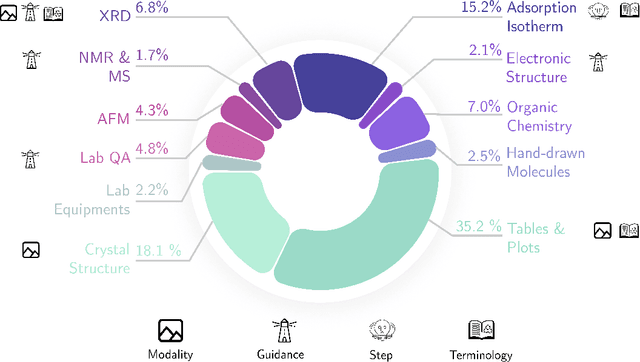
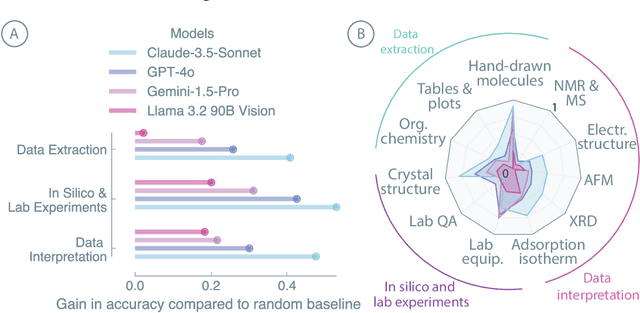
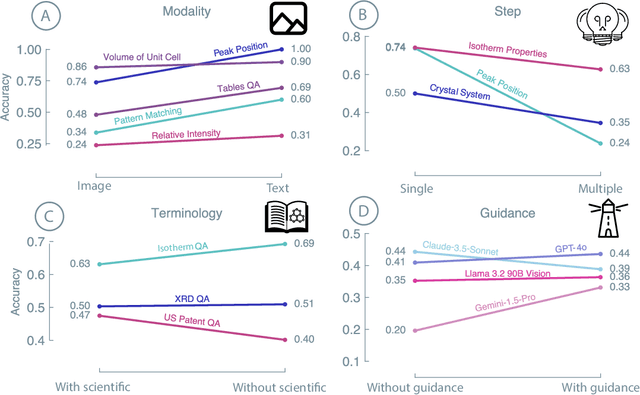
Recent advancements in artificial intelligence have sparked interest in scientific assistants that could support researchers across the full spectrum of scientific workflows, from literature review to experimental design and data analysis. A key capability for such systems is the ability to process and reason about scientific information in both visual and textual forms - from interpreting spectroscopic data to understanding laboratory setups. Here, we introduce MaCBench, a comprehensive benchmark for evaluating how vision-language models handle real-world chemistry and materials science tasks across three core aspects: data extraction, experimental understanding, and results interpretation. Through a systematic evaluation of leading models, we find that while these systems show promising capabilities in basic perception tasks - achieving near-perfect performance in equipment identification and standardized data extraction - they exhibit fundamental limitations in spatial reasoning, cross-modal information synthesis, and multi-step logical inference. Our insights have important implications beyond chemistry and materials science, suggesting that developing reliable multimodal AI scientific assistants may require advances in curating suitable training data and approaches to training those models.