 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral purpose models for the chemical sciences
Jul 10, 2025



Data-driven techniques have a large potential to transform and accelerate the chemical sciences. However, chemical sciences also pose the unique challenge of very diverse, small, fuzzy datasets that are difficult to leverage in conventional machine learning approaches completely. A new class of models, general-purpose models (GPMs) such as large language models, have shown the ability to solve tasks they have not been directly trained on, and to flexibly operate with low amounts of data in different formats. In this review, we discuss fundamental building principles of GPMs and review recent applications of those models in the chemical sciences across the entire scientific process. While many of these applications are still in the prototype phase, we expect that the increasing interest in GPMs will make many of them mature in the coming years.
Lessons from the trenches on evaluating machine-learning systems in materials science
Mar 13, 2025Measurements are fundamental to knowledge creation in science, enabling consistent sharing of findings and serving as the foundation for scientific discovery. As machine learning systems increasingly transform scientific fields, the question of how to effectively evaluate these systems becomes crucial for ensuring reliable progress. In this review, we examine the current state and future directions of evaluation frameworks for machine learning in science. We organize the review around a broadly applicable framework for evaluating machine learning systems through the lens of statistical measurement theory, using materials science as our primary context for examples and case studies. We identify key challenges common across machine learning evaluation such as construct validity, data quality issues, metric design limitations, and benchmark maintenance problems that can lead to phantom progress when evaluation frameworks fail to capture real-world performance needs. By examining both traditional benchmarks and emerging evaluation approaches, we demonstrate how evaluation choices fundamentally shape not only our measurements but also research priorities and scientific progress. These findings reveal the critical need for transparency in evaluation design and reporting, leading us to propose evaluation cards as a structured approach to documenting measurement choices and limitations. Our work highlights the importance of developing a more diverse toolbox of evaluation techniques for machine learning in materials science, while offering insights that can inform evaluation practices in other scientific domains where similar challenges exist.
Probing the limitations of multimodal language models for chemistry and materials research
Nov 25, 2024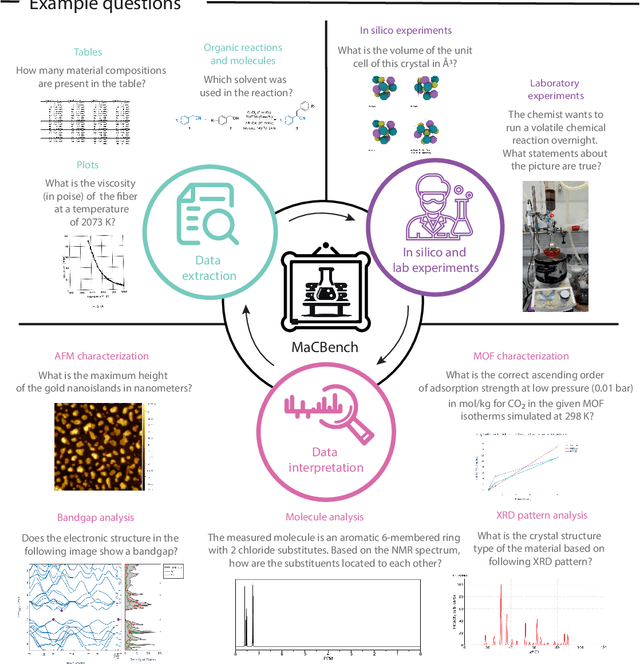
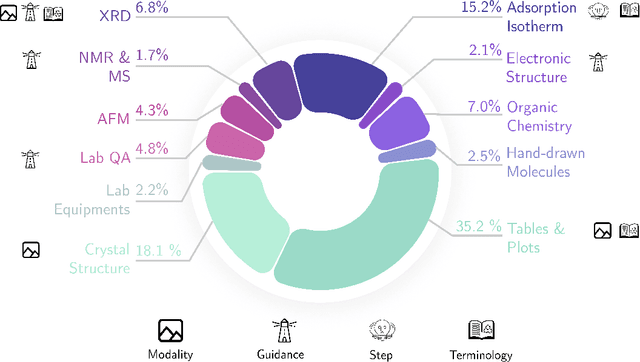
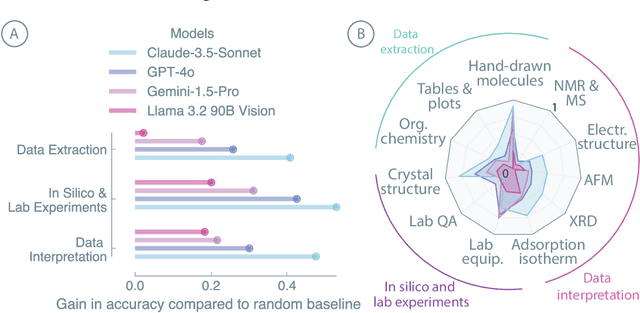
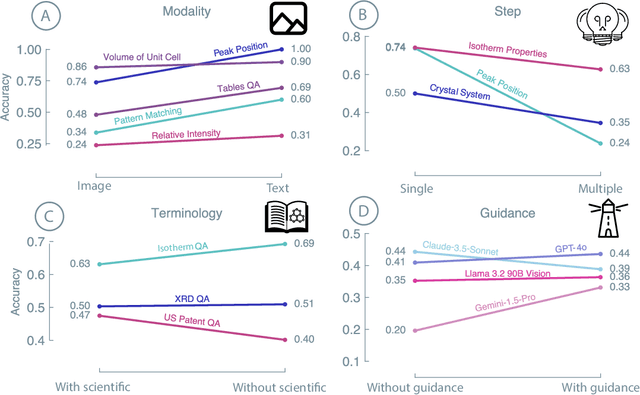
Recent advancements in artificial intelligence have sparked interest in scientific assistants that could support researchers across the full spectrum of scientific workflows, from literature review to experimental design and data analysis. A key capability for such systems is the ability to process and reason about scientific information in both visual and textual forms - from interpreting spectroscopic data to understanding laboratory setups. Here, we introduce MaCBench, a comprehensive benchmark for evaluating how vision-language models handle real-world chemistry and materials science tasks across three core aspects: data extraction, experimental understanding, and results interpretation. Through a systematic evaluation of leading models, we find that while these systems show promising capabilities in basic perception tasks - achieving near-perfect performance in equipment identification and standardized data extraction - they exhibit fundamental limitations in spatial reasoning, cross-modal information synthesis, and multi-step logical inference. Our insights have important implications beyond chemistry and materials science, suggesting that developing reliable multimodal AI scientific assistants may require advances in curating suitable training data and approaches to training those models.
Reflections from the 2024 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
Nov 20, 2024



Here, we present the outcomes from the second Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry, which engaged participants across global hybrid locations, resulting in 34 team submissions. The submissions spanned seven key application areas and demonstrated the diverse utility of LLMs for applications in (1) molecular and material property prediction; (2) molecular and material design; (3) automation and novel interfaces; (4) scientific communication and education; (5) research data management and automation; (6) hypothesis generation and evaluation; and (7) knowledge extraction and reasoning from scientific literature. Each team submission is presented in a summary table with links to the code and as brief papers in the appendix. Beyond team results, we discuss the hackathon event and its hybrid format, which included physical hubs in Toronto, Montreal, San Francisco, Berlin, Lausanne, and Tokyo, alongside a global online hub to enable local and virtual collaboration. Overall, the event highlighted significant improvements in LLM capabilities since the previous year's hackathon, suggesting continued expansion of LLMs for applications in materials science and chemistry research. These outcomes demonstrate the dual utility of LLMs as both multipurpose models for diverse machine learning tasks and platforms for rapid prototyping custom applications in scientific research.
From Text to Insight: Large Language Models for Materials Science Data Extraction
Jul 23, 2024



The vast majority of materials science knowledge exists in unstructured natural language, yet structured data is crucial for innovative and systematic materials design. Traditionally, the field has relied on manual curation and partial automation for data extraction for specific use cases. The advent of large language models (LLMs) represents a significant shift, potentially enabling efficient extraction of structured, actionable data from unstructured text by non-experts. While applying LLMs to materials science data extraction presents unique challenges, domain knowledge offers opportunities to guide and validate LLM outputs. This review provides a comprehensive overview of LLM-based structured data extraction in materials science, synthesizing current knowledge and outlining future directions. We address the lack of standardized guidelines and present frameworks for leveraging the synergy between LLMs and materials science expertise. This work serves as a foundational resource for researchers aiming to harness LLMs for data-driven materials research. The insights presented here could significantly enhance how researchers across disciplines access and utilize scientific information, potentially accelerating the development of novel materials for critical societal needs.