 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge34 Examples of LLM Applications in Materials Science and Chemistry: Towards Automation, Assistants, Agents, and Accelerated Scientific Discovery
May 05, 2025
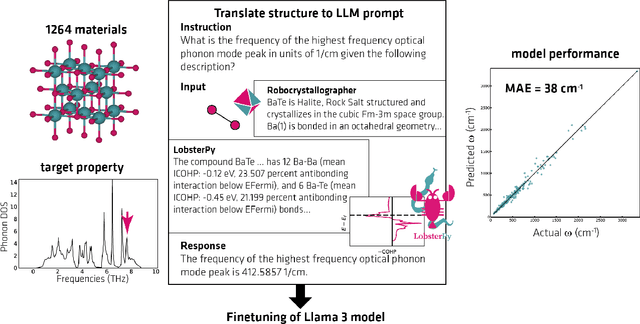
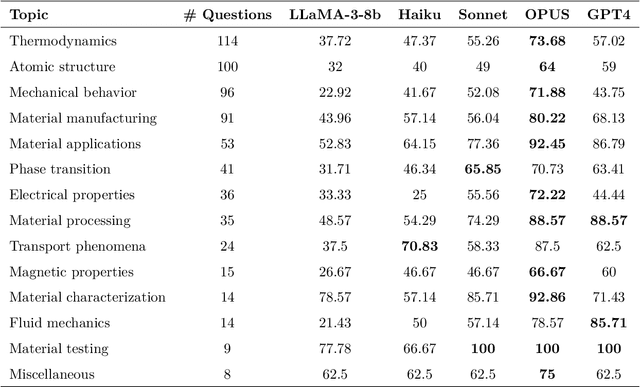
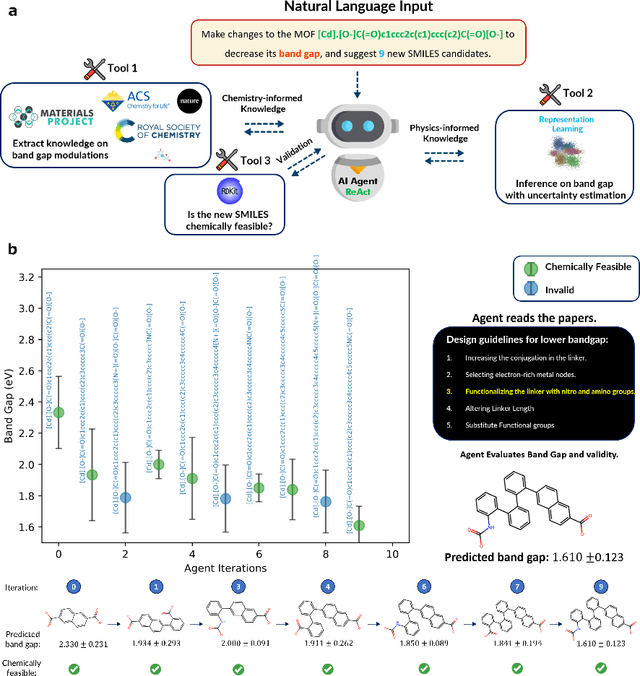
Large Language Models (LLMs) are reshaping many aspects of materials science and chemistry research, enabling advances in molecular property prediction, materials design, scientific automation, knowledge extraction, and more. Recent developments demonstrate that the latest class of models are able to integrate structured and unstructured data, assist in hypothesis generation, and streamline research workflows. To explore the frontier of LLM capabilities across the research lifecycle, we review applications of LLMs through 34 total projects developed during the second annual Large Language Model Hackathon for Applications in Materials Science and Chemistry, a global hybrid event. These projects spanned seven key research areas: (1) molecular and material property prediction, (2) molecular and material design, (3) automation and novel interfaces, (4) scientific communication and education, (5) research data management and automation, (6) hypothesis generation and evaluation, and (7) knowledge extraction and reasoning from the scientific literature. Collectively, these applications illustrate how LLMs serve as versatile predictive models, platforms for rapid prototyping of domain-specific tools, and much more. In particular, improvements in both open source and proprietary LLM performance through the addition of reasoning, additional training data, and new techniques have expanded effectiveness, particularly in low-data environments and interdisciplinary research. As LLMs continue to improve, their integration into scientific workflows presents both new opportunities and new challenges, requiring ongoing exploration, continued refinement, and further research to address reliability, interpretability, and reproducibility.
Kernel Learning Assisted Synthesis Condition Exploration for Ternary Spinel
Mar 25, 2025



Machine learning and high-throughput experimentation have greatly accelerated the discovery of mixed metal oxide catalysts by leveraging their compositional flexibility. However, the lack of established synthesis routes for solid-state materials remains a significant challenge in inorganic chemistry. An interpretable machine learning model is therefore essential, as it provides insights into the key factors governing phase formation. Here, we focus on the formation of single-phase Fe$_2$(ZnCo)O$_4$, synthesized via a high-throughput co-precipitation method. We combined a kernel classification model with a novel application of global SHAP analysis to pinpoint the experimental features most critical to single phase synthesizability by interpreting the contributions of each feature. Global SHAP analysis reveals that precursor and precipitating agent contributions to single-phase spinel formation align closely with established crystal growth theories. These results not only underscore the importance of interpretable machine learning in refining synthesis protocols but also establish a framework for data-informed experimental design in inorganic synthesis.
Reflections from the 2024 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
Nov 20, 2024



Here, we present the outcomes from the second Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry, which engaged participants across global hybrid locations, resulting in 34 team submissions. The submissions spanned seven key application areas and demonstrated the diverse utility of LLMs for applications in (1) molecular and material property prediction; (2) molecular and material design; (3) automation and novel interfaces; (4) scientific communication and education; (5) research data management and automation; (6) hypothesis generation and evaluation; and (7) knowledge extraction and reasoning from scientific literature. Each team submission is presented in a summary table with links to the code and as brief papers in the appendix. Beyond team results, we discuss the hackathon event and its hybrid format, which included physical hubs in Toronto, Montreal, San Francisco, Berlin, Lausanne, and Tokyo, alongside a global online hub to enable local and virtual collaboration. Overall, the event highlighted significant improvements in LLM capabilities since the previous year's hackathon, suggesting continued expansion of LLMs for applications in materials science and chemistry research. These outcomes demonstrate the dual utility of LLMs as both multipurpose models for diverse machine learning tasks and platforms for rapid prototyping custom applications in scientific research.
Agent-based Learning of Materials Datasets from Scientific Literature
Dec 18, 2023Advancements in machine learning and artificial intelligence are transforming materials discovery. Yet, the availability of structured experimental data remains a bottleneck. The vast corpus of scientific literature presents a valuable and rich resource of such data. However, manual dataset creation from these resources is challenging due to issues in maintaining quality and consistency, scalability limitations, and the risk of human error and bias. Therefore, in this work, we develop a chemist AI agent, powered by large language models (LLMs), to overcome these challenges by autonomously creating structured datasets from natural language text, ranging from sentences and paragraphs to extensive scientific research articles. Our chemist AI agent, Eunomia, can plan and execute actions by leveraging the existing knowledge from decades of scientific research articles, scientists, the Internet and other tools altogether. We benchmark the performance of our approach in three different information extraction tasks with various levels of complexity, including solid-state impurity doping, metal-organic framework (MOF) chemical formula, and property relations. Our results demonstrate that our zero-shot agent, with the appropriate tools, is capable of attaining performance that is either superior or comparable to the state-of-the-art fine-tuned materials information extraction methods. This approach simplifies compilation of machine learning-ready datasets for various materials discovery applications, and significantly ease the accessibility of advanced natural language processing tools for novice users in natural language. The methodology in this work is developed as an open-source software on https://github.com/AI4ChemS/Eunomia.