 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-Operations-Oriented Inference Optimization Techniques for Large Models
Jun 18, 2026Large model inference optimization serves as a key foundation for supporting the scalable, low-cost, and highly stable operation of large model services. Centered on token-oriented inference optimization technology, this paper proposes for the first time a four-layer technical architecture consisting of Multi-model Fusion, Model Optimization, Compute-Model Fusion, and Compute-Network-Model Fusion. It systematically reviews the key technologies and current industry status across these four levels and analyzes the application value of related technologies in real-world business scenarios. This paper provides a practical technical path for reducing token production costs, improving token service efficiency, ensuring the stability of token supply, and driving the transition of large model services from being merely callable to being operable.
$Ψ$-Bench: Evaluating Persona-Sensitive Influencing in Persuasive Dialogues
Jun 01, 2026Personalization is a crucial capability of modern language agents. However, current research primarily positions personalized agents as passive responders to user preferences, limiting their ability to interact with users and provide suggestions or guidance proactively. To systematically evaluate such proactive personalization in realistic interactions, we propose $Ψ$-Bench, a benchmark for assessing LLMs' ability to influence realistic users through conversation. We design three real-world interaction scenarios that involve persuasion in $Ψ$-Bench, and endow simulated clients with personal characteristics through explicit user profiles derived from dialogue histories. We evaluate 10 frontier LLMs on $Ψ$-Bench and find that while most models can produce coherent and reasonable arguments, even state-of-the-art models still leave considerable room for improvement in persuasion. We also find that providing access to client profiles yields an average performance gain of 18.24\%, highlighting the importance of user-specific information for effective persuasion. Overall, our work highlights persona-sensitive influencing as a challenging yet practical direction for evaluating and developing more proactive personalized LLM agents. Codes are available at: https://github.com/Hanpx20/Psi-Bench.
Adversarial Trust Poisoning in Vehicular Collaborative Perception
May 21, 2026Collaborative perception (CP) enables connected and autonomous vehicles to share sensor data and jointly reason about their environment. To defend against adversaries that fabricate or manipulate shared data, existing systems employ cross-vehicle inconsistency detection and trust estimation, penalizing vehicles whose observations conflict with the majority. In this work, we show that these defenses themselves introduce a new attack surface. We present TrustFlip, a novel attack that weaponizes consistency-based defenses to poison the trust assigned to benign vehicles. Instead of injecting false data into the collaboration pipeline, it deploys physical adversarial objects that are genuine but induce inconsistent observations among benign vehicles. The resulting inconsistencies are misattributed by the defense to the targeted vehicle, causing its trust score to degrade and eventually leading to its downweighting or exclusion from collaboration. Consequently, the system loses reliable sensing contributors, degrading perception capability and potentially inducing safety-critical failures. We evaluate TrustFlip across multiple collaborative perception architectures and defense mechanisms. Our results show that state-of-the-art defenses can be significantly affected: the attack removes the targeted benign vehicle from collaboration in up to 87.7% of scenarios and drops Average Precision (AP) by up to 13%. As an initial mitigation, we introduce TrustReflect, a lightweight self-reflection mechanism that marks disputed regions as uncertain and excludes them from trust evaluation, reducing the attack success rate by 35-100%.
From Knowledge to Action: Outcomes of the 2025 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
May 04, 2026Large language models (LLMs) are rapidly changing how researchers in materials science and chemistry discover, organize, and act on scientific knowledge. This paper analyzes a broad set of community-developed LLM applications in an effort to identify emerging patterns in how these systems can be used across the scientific research lifecycle. We organize the projects into two complementary categories: Knowledge Infrastructure, systems that structure, retrieve, synthesize, and validate scientific information; and Action Systems, systems that execute, coordinate, or automate scientific work across computational and experimental environments. The submissions reveal a shift from single-purpose LLM tools toward integrated, multi-agent workflows that combine retrieval, reasoning, tool use, and domain-specific validation. Prominent themes include retrieval-augmented generation as grounding infrastructure, persistent structured knowledge representations, multimodal and multilingual scientific inputs, and early progress toward laboratory-integrated closed-loop systems. Together, these results suggest that LLMs are evolving from general-purpose assistants into composable infrastructure for scientific reasoning and action. This work provides a community snapshot of that transition and a practical taxonomy for understanding emerging LLM-enabled workflows in materials science and chemistry.
Enhanced Polarization Locking in VCSELs
Apr 02, 2026While optical injection locking (OIL) of vertical-cavity surface-emitting lasers (VCSELs) has been widely studied in the past, the polarization dynamics of OIL have received far less attention. Recent studies suggest that polarization locking via OIL could enable novel computational applications such as polarization-encoded Ising computers. However, the inherent polarization preference and limited polarization switchability of VCSELs hinder their use for such purposes. To address these challenges, we fabricate VCSELs with tailored oxide aperture designs and combine these with bias current tuning to study the overall impact on polarization locking. Experimental results demonstrate that this approach reduces the required injection power (to as low as 3.6 μW) and expands the locking range. To investigate the impact of the approach, the spin-flip model (SFM) is used to analyze the effects of amplitude anisotropy and bias current on polarization locking, demonstrating strong coherence with experimental results.
LSGQuant: Layer-Sensitivity Guided Quantization for One-Step Diffusion Real-World Video Super-Resolution
Feb 03, 2026One-Step Diffusion Models have demonstrated promising capability and fast inference in video super-resolution (VSR) for real-world. Nevertheless, the substantial model size and high computational cost of Diffusion Transformers (DiTs) limit downstream applications. While low-bit quantization is a common approach for model compression, the effectiveness of quantized models is challenged by the high dynamic range of input latent and diverse layer behaviors. To deal with these challenges, we introduce LSGQuant, a layer-sensitivity guided quantizing approach for one-step diffusion-based real-world VSR. Our method incorporates a Dynamic Range Adaptive Quantizer (DRAQ) to fit video token activations. Furthermore, we estimate layer sensitivity and implement a Variance-Oriented Layer Training Strategy (VOLTS) by analyzing layer-wise statistics in calibration. We also introduce Quantization-Aware Optimization (QAO) to jointly refine the quantized branch and a retained high-precision branch. Extensive experiments demonstrate that our method has nearly performance to origin model with full-precision and significantly exceeds existing quantization techniques. Code is available at: https://github.com/zhengchen1999/LSGQuant.
Context-Aware Dynamic Chunking for Streaming Tibetan Speech Recognition
Nov 12, 2025In this work, we propose a streaming speech recognition framework for Amdo Tibetan, built upon a hybrid CTC/Atten-tion architecture with a context-aware dynamic chunking mechanism. The proposed strategy adaptively adjusts chunk widths based on encoding states, enabling flexible receptive fields, cross-chunk information exchange, and robust adaptation to varying speaking rates, thereby alleviating the context truncation problem of fixed-chunk methods. To further capture the linguistic characteristics of Tibetan, we construct a lexicon grounded in its orthographic principles, providing linguistically motivated modeling units. During decoding, an external language model is integrated to enhance semantic consistency and improve recognition of long sentences. Experimental results show that the proposed framework achieves a word error rate (WER) of 6.23% on the test set, yielding a 48.15% relative improvement over the fixed-chunk baseline, while significantly reducing recognition latency and maintaining performance close to global decoding.
Tibetan Language and AI: A Comprehensive Survey of Resources, Methods and Challenges
Oct 22, 2025Tibetan, one of the major low-resource languages in Asia, presents unique linguistic and sociocultural characteristics that pose both challenges and opportunities for AI research. Despite increasing interest in developing AI systems for underrepresented languages, Tibetan has received limited attention due to a lack of accessible data resources, standardized benchmarks, and dedicated tools. This paper provides a comprehensive survey of the current state of Tibetan AI in the AI domain, covering textual and speech data resources, NLP tasks, machine translation, speech recognition, and recent developments in LLMs. We systematically categorize existing datasets and tools, evaluate methods used across different tasks, and compare performance where possible. We also identify persistent bottlenecks such as data sparsity, orthographic variation, and the lack of unified evaluation metrics. Additionally, we discuss the potential of cross-lingual transfer, multi-modal learning, and community-driven resource creation. This survey aims to serve as a foundational reference for future work on Tibetan AI research and encourages collaborative efforts to build an inclusive and sustainable AI ecosystem for low-resource languages.
Listening, Imagining \& Refining: A Heuristic Optimized ASR Correction Framework with LLMs
Sep 18, 2025Automatic Speech Recognition (ASR) systems remain prone to errors that affect downstream applications. In this paper, we propose LIR-ASR, a heuristic optimized iterative correction framework using LLMs, inspired by human auditory perception. LIR-ASR applies a "Listening-Imagining-Refining" strategy, generating phonetic variants and refining them in context. A heuristic optimization with finite state machine (FSM) is introduced to prevent the correction process from being trapped in local optima and rule-based constraints help maintain semantic fidelity. Experiments on both English and Chinese ASR outputs show that LIR-ASR achieves average reductions in CER/WER of up to 1.5 percentage points compared to baselines, demonstrating substantial accuracy gains in transcription.
A Comprehensive Evaluation on Quantization Techniques for Large Language Models
Jul 23, 2025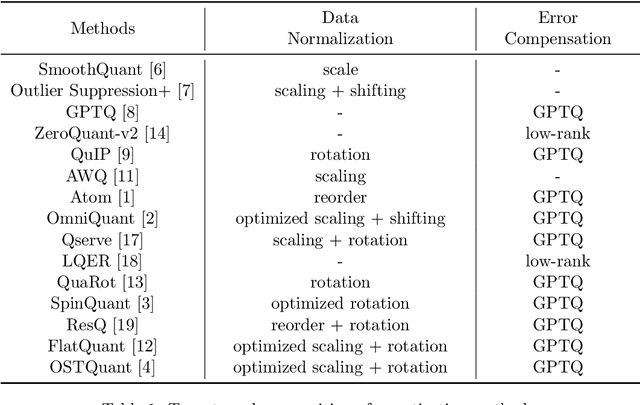
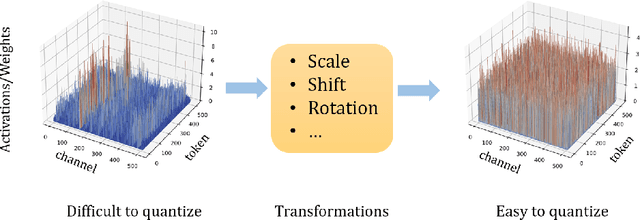
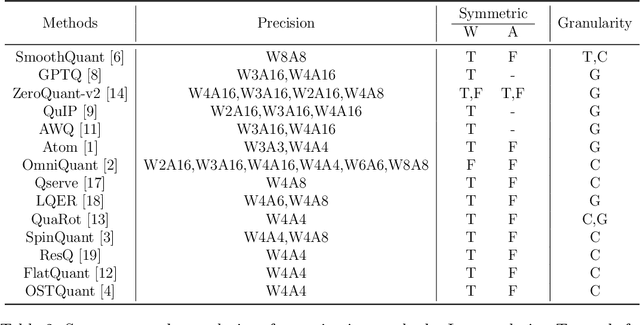
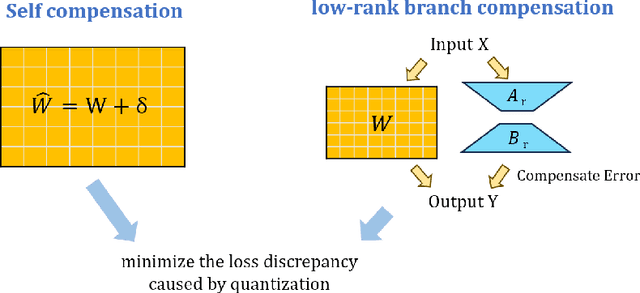
For large language models (LLMs), post-training quantization (PTQ) can significantly reduce memory footprint and computational overhead. Model quantization is a rapidly evolving research field. Though many papers have reported breakthrough performance, they may not conduct experiments on the same ground since one quantization method usually contains multiple components. In addition, analyzing the theoretical connections among existing methods is crucial for in-depth understanding. To bridge these gaps, we conduct an extensive review of state-of-the-art methods and perform comprehensive evaluations on the same ground to ensure fair comparisons. To our knowledge, this fair and extensive investigation remains critically important yet underexplored. To better understand the theoretical connections, we decouple the published quantization methods into two steps: pre-quantization transformation and quantization error mitigation. We define the former as a preprocessing step applied before quantization to reduce the impact of outliers, making the data distribution flatter and more suitable for quantization. Quantization error mitigation involves techniques that offset the errors introduced during quantization, thereby enhancing model performance. We evaluate and analyze the impact of different components of quantization methods. Additionally, we analyze and evaluate the latest MXFP4 data format and its performance. Our experimental results demonstrate that optimized rotation and scaling yield the best performance for pre-quantization transformation, and combining low-rank compensation with GPTQ occasionally outperforms using GPTQ alone for quantization error mitigation. Furthermore, we explore the potential of the latest MXFP4 quantization and reveal that the optimal pre-quantization transformation strategy for INT4 does not generalize well to MXFP4, inspiring further investigation.