 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD-OPSD: On-Policy Self-Distillation for Continuously Tuning Step-Distilled Diffusion Models
May 06, 2026The landscape of high-performance image generation models is currently shifting from the inefficient multi-step ones to the efficient few-step counterparts (e.g, Z-Image-Turbo and FLUX.2-klein). However, these models present significant challenges for directly continuous supervised fine-tuning. For example, applying the commonly used fine-tuning technique would compromises their inherent few-step inference capability. To address this, we propose D-OPSD, a novel training paradigm for step-distilled diffusion models that enables on-policy learning during supervised fine-tuning. We first find that the modern diffusion model where the LLM/VLM serves as the encoder can inherit its encoder's in-context capabilities. This enables us to make the training as an on-policy self-distillation process. Specifically, during training, we make the model acts as both the teacher and the student with different contexts, where the student is conditioned only on the text feature, while the teacher is conditioned on the multimodal feature of both the text prompt and the target image. Training minimizes the two predicted distributions over the student's own roll-outs. By optimized on the model's own trajectory and under it's own supervision, D-OPSD enables the model to learn new concept, style, etc. without sacrificing the original few-step capacity.
Distribution Matching Distillation Meets Reinforcement Learning
Nov 19, 2025Distribution Matching Distillation (DMD) distills a pre-trained multi-step diffusion model to a few-step one to improve inference efficiency. However, the performance of the latter is often capped by the former. To circumvent this dilemma, we propose DMDR, a novel framework that combines Reinforcement Learning (RL) techniques into the distillation process. We show that for the RL of the few-step generator, the DMD loss itself is a more effective regularization compared to the traditional ones. In turn, RL can help to guide the mode coverage process in DMD more effectively. These allow us to unlock the capacity of the few-step generator by conducting distillation and RL simultaneously. Meanwhile, we design the dynamic distribution guidance and dynamic renoise sampling training strategies to improve the initial distillation process. The experiments demonstrate that DMDR can achieve leading visual quality, prompt coherence among few-step methods, and even exhibit performance that exceeds the multi-step teacher.
Lumina-mGPT 2.0: Stand-Alone AutoRegressive Image Modeling
Jul 23, 2025



We present Lumina-mGPT 2.0, a stand-alone, decoder-only autoregressive model that revisits and revitalizes the autoregressive paradigm for high-quality image generation and beyond. Unlike existing approaches that rely on pretrained components or hybrid architectures, Lumina-mGPT 2.0 is trained entirely from scratch, enabling unrestricted architectural design and licensing freedom. It achieves generation quality on par with state-of-the-art diffusion models such as DALL-E 3 and SANA, while preserving the inherent flexibility and compositionality of autoregressive modeling. Our unified tokenization scheme allows the model to seamlessly handle a wide spectrum of tasks-including subject-driven generation, image editing, controllable synthesis, and dense prediction-within a single generative framework. To further boost usability, we incorporate efficient decoding strategies like inference-time scaling and speculative Jacobi sampling to improve quality and speed, respectively. Extensive evaluations on standard text-to-image benchmarks (e.g., GenEval, DPG) demonstrate that Lumina-mGPT 2.0 not only matches but in some cases surpasses diffusion-based models. Moreover, we confirm its multi-task capabilities on the Graph200K benchmark, with the native Lumina-mGPT 2.0 performing exceptionally well. These results position Lumina-mGPT 2.0 as a strong, flexible foundation model for unified multimodal generation. We have released our training details, code, and models at https://github.com/Alpha-VLLM/Lumina-mGPT-2.0.
OmniCaptioner: One Captioner to Rule Them All
Apr 09, 2025We propose OmniCaptioner, a versatile visual captioning framework for generating fine-grained textual descriptions across a wide variety of visual domains. Unlike prior methods limited to specific image types (e.g., natural images or geometric visuals), our framework provides a unified solution for captioning natural images, visual text (e.g., posters, UIs, textbooks), and structured visuals (e.g., documents, tables, charts). By converting low-level pixel information into semantically rich textual representations, our framework bridges the gap between visual and textual modalities. Our results highlight three key advantages: (i) Enhanced Visual Reasoning with LLMs, where long-context captions of visual modalities empower LLMs, particularly the DeepSeek-R1 series, to reason effectively in multimodal scenarios; (ii) Improved Image Generation, where detailed captions improve tasks like text-to-image generation and image transformation; and (iii) Efficient Supervised Fine-Tuning (SFT), which enables faster convergence with less data. We believe the versatility and adaptability of OmniCaptioner can offer a new perspective for bridging the gap between language and visual modalities.
Lumina-Image 2.0: A Unified and Efficient Image Generative Framework
Mar 27, 2025



We introduce Lumina-Image 2.0, an advanced text-to-image generation framework that achieves significant progress compared to previous work, Lumina-Next. Lumina-Image 2.0 is built upon two key principles: (1) Unification - it adopts a unified architecture (Unified Next-DiT) that treats text and image tokens as a joint sequence, enabling natural cross-modal interactions and allowing seamless task expansion. Besides, since high-quality captioners can provide semantically well-aligned text-image training pairs, we introduce a unified captioning system, Unified Captioner (UniCap), specifically designed for T2I generation tasks. UniCap excels at generating comprehensive and accurate captions, accelerating convergence and enhancing prompt adherence. (2) Efficiency - to improve the efficiency of our proposed model, we develop multi-stage progressive training strategies and introduce inference acceleration techniques without compromising image quality. Extensive evaluations on academic benchmarks and public text-to-image arenas show that Lumina-Image 2.0 delivers strong performances even with only 2.6B parameters, highlighting its scalability and design efficiency. We have released our training details, code, and models at https://github.com/Alpha-VLLM/Lumina-Image-2.0.
LeX-Art: Rethinking Text Generation via Scalable High-Quality Data Synthesis
Mar 27, 2025We introduce LeX-Art, a comprehensive suite for high-quality text-image synthesis that systematically bridges the gap between prompt expressiveness and text rendering fidelity. Our approach follows a data-centric paradigm, constructing a high-quality data synthesis pipeline based on Deepseek-R1 to curate LeX-10K, a dataset of 10K high-resolution, aesthetically refined 1024$\times$1024 images. Beyond dataset construction, we develop LeX-Enhancer, a robust prompt enrichment model, and train two text-to-image models, LeX-FLUX and LeX-Lumina, achieving state-of-the-art text rendering performance. To systematically evaluate visual text generation, we introduce LeX-Bench, a benchmark that assesses fidelity, aesthetics, and alignment, complemented by Pairwise Normalized Edit Distance (PNED), a novel metric for robust text accuracy evaluation. Experiments demonstrate significant improvements, with LeX-Lumina achieving a 79.81% PNED gain on CreateBench, and LeX-FLUX outperforming baselines in color (+3.18%), positional (+4.45%), and font accuracy (+3.81%). Our codes, models, datasets, and demo are publicly available.
Lumina-Video: Efficient and Flexible Video Generation with Multi-scale Next-DiT
Feb 10, 2025Recent advancements have established Diffusion Transformers (DiTs) as a dominant framework in generative modeling. Building on this success, Lumina-Next achieves exceptional performance in the generation of photorealistic images with Next-DiT. However, its potential for video generation remains largely untapped, with significant challenges in modeling the spatiotemporal complexity inherent to video data. To address this, we introduce Lumina-Video, a framework that leverages the strengths of Next-DiT while introducing tailored solutions for video synthesis. Lumina-Video incorporates a Multi-scale Next-DiT architecture, which jointly learns multiple patchifications to enhance both efficiency and flexibility. By incorporating the motion score as an explicit condition, Lumina-Video also enables direct control of generated videos' dynamic degree. Combined with a progressive training scheme with increasingly higher resolution and FPS, and a multi-source training scheme with mixed natural and synthetic data, Lumina-Video achieves remarkable aesthetic quality and motion smoothness at high training and inference efficiency. We additionally propose Lumina-V2A, a video-to-audio model based on Next-DiT, to create synchronized sounds for generated videos. Codes are released at https://www.github.com/Alpha-VLLM/Lumina-Video.
I-Max: Maximize the Resolution Potential of Pre-trained Rectified Flow Transformers with Projected Flow
Oct 10, 2024

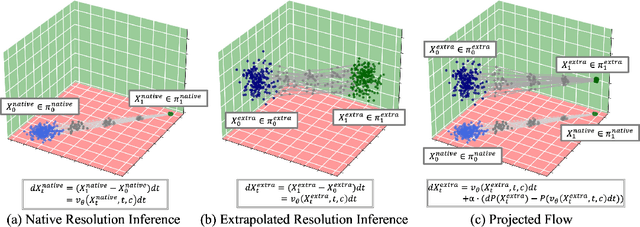
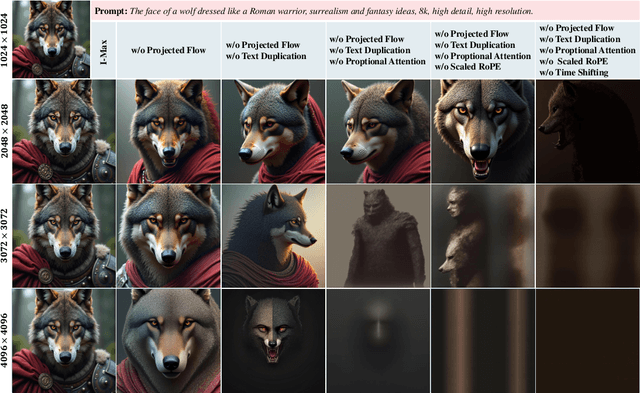
Rectified Flow Transformers (RFTs) offer superior training and inference efficiency, making them likely the most viable direction for scaling up diffusion models. However, progress in generation resolution has been relatively slow due to data quality and training costs. Tuning-free resolution extrapolation presents an alternative, but current methods often reduce generative stability, limiting practical application. In this paper, we review existing resolution extrapolation methods and introduce the I-Max framework to maximize the resolution potential of Text-to-Image RFTs. I-Max features: (i) a novel Projected Flow strategy for stable extrapolation and (ii) an advanced inference toolkit for generalizing model knowledge to higher resolutions. Experiments with Lumina-Next-2K and Flux.1-dev demonstrate I-Max's ability to enhance stability in resolution extrapolation and show that it can bring image detail emergence and artifact correction, confirming the practical value of tuning-free resolution extrapolation.
Lumina-mGPT: Illuminate Flexible Photorealistic Text-to-Image Generation with Multimodal Generative Pretraining
Aug 05, 2024



We present Lumina-mGPT, a family of multimodal autoregressive models capable of various vision and language tasks, particularly excelling in generating flexible photorealistic images from text descriptions. Unlike existing autoregressive image generation approaches, Lumina-mGPT employs a pretrained decoder-only transformer as a unified framework for modeling multimodal token sequences. Our key insight is that a simple decoder-only transformer with multimodal Generative PreTraining (mGPT), utilizing the next-token prediction objective on massive interleaved text-image sequences, can learn broad and general multimodal capabilities, thereby illuminating photorealistic text-to-image generation. Building on these pretrained models, we propose Flexible Progressive Supervised Finetuning (FP-SFT) on high-quality image-text pairs to fully unlock their potential for high-aesthetic image synthesis at any resolution while maintaining their general multimodal capabilities. Furthermore, we introduce Ominiponent Supervised Finetuning (Omni-SFT), transforming Lumina-mGPT into a foundation model that seamlessly achieves omnipotent task unification. The resulting model demonstrates versatile multimodal capabilities, including visual generation tasks like flexible text-to-image generation and controllable generation, visual recognition tasks like segmentation and depth estimation, and vision-language tasks like multiturn visual question answering. Additionally, we analyze the differences and similarities between diffusion-based and autoregressive methods in a direct comparison.
VEnhancer: Generative Space-Time Enhancement for Video Generation
Jul 10, 2024



We present VEnhancer, a generative space-time enhancement framework that improves the existing text-to-video results by adding more details in spatial domain and synthetic detailed motion in temporal domain. Given a generated low-quality video, our approach can increase its spatial and temporal resolution simultaneously with arbitrary up-sampling space and time scales through a unified video diffusion model. Furthermore, VEnhancer effectively removes generated spatial artifacts and temporal flickering of generated videos. To achieve this, basing on a pretrained video diffusion model, we train a video ControlNet and inject it to the diffusion model as a condition on low frame-rate and low-resolution videos. To effectively train this video ControlNet, we design space-time data augmentation as well as video-aware conditioning. Benefiting from the above designs, VEnhancer yields to be stable during training and shares an elegant end-to-end training manner. Extensive experiments show that VEnhancer surpasses existing state-of-the-art video super-resolution and space-time super-resolution methods in enhancing AI-generated videos. Moreover, with VEnhancer, exisiting open-source state-of-the-art text-to-video method, VideoCrafter-2, reaches the top one in video generation benchmark -- VBench.