 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Evaluation of Visual Processing Should Be Human-Centered, Not Metric-Centered
Feb 28, 2026This position paper argues that the evaluation of modern visual processing systems should no longer be driven primarily by single-metric image quality assessment benchmarks, particularly in the era of generative and perception-oriented methods. Image restoration exemplifies this divergence: while objective IQA metrics enable reproducible, scalable evaluation, they have increasingly drifted apart from human perception and user preferences. We contend that this mismatch risks constraining innovation and misguiding research progress across visual processing tasks. Rather than rejecting metrics altogether, this paper calls for a rebalancing of evaluation paradigms, advocating a more human-centered, context-aware, and fine-grained approach to assessing the visual models' outcomes.
Harnessing Diffusion-Yielded Score Priors for Image Restoration
Jul 28, 2025Deep image restoration models aim to learn a mapping from degraded image space to natural image space. However, they face several critical challenges: removing degradation, generating realistic details, and ensuring pixel-level consistency. Over time, three major classes of methods have emerged, including MSE-based, GAN-based, and diffusion-based methods. However, they fail to achieve a good balance between restoration quality, fidelity, and speed. We propose a novel method, HYPIR, to address these challenges. Our solution pipeline is straightforward: it involves initializing the image restoration model with a pre-trained diffusion model and then fine-tuning it with adversarial training. This approach does not rely on diffusion loss, iterative sampling, or additional adapters. We theoretically demonstrate that initializing adversarial training from a pre-trained diffusion model positions the initial restoration model very close to the natural image distribution. Consequently, this initialization improves numerical stability, avoids mode collapse, and substantially accelerates the convergence of adversarial training. Moreover, HYPIR inherits the capabilities of diffusion models with rich user control, enabling text-guided restoration and adjustable texture richness. Requiring only a single forward pass, it achieves faster convergence and inference speed than diffusion-based methods. Extensive experiments show that HYPIR outperforms previous state-of-the-art methods, achieving efficient and high-quality image restoration.
VEnhancer: Generative Space-Time Enhancement for Video Generation
Jul 10, 2024



We present VEnhancer, a generative space-time enhancement framework that improves the existing text-to-video results by adding more details in spatial domain and synthetic detailed motion in temporal domain. Given a generated low-quality video, our approach can increase its spatial and temporal resolution simultaneously with arbitrary up-sampling space and time scales through a unified video diffusion model. Furthermore, VEnhancer effectively removes generated spatial artifacts and temporal flickering of generated videos. To achieve this, basing on a pretrained video diffusion model, we train a video ControlNet and inject it to the diffusion model as a condition on low frame-rate and low-resolution videos. To effectively train this video ControlNet, we design space-time data augmentation as well as video-aware conditioning. Benefiting from the above designs, VEnhancer yields to be stable during training and shares an elegant end-to-end training manner. Extensive experiments show that VEnhancer surpasses existing state-of-the-art video super-resolution and space-time super-resolution methods in enhancing AI-generated videos. Moreover, with VEnhancer, exisiting open-source state-of-the-art text-to-video method, VideoCrafter-2, reaches the top one in video generation benchmark -- VBench.
Towards Real-world Video Face Restoration: A New Benchmark
Apr 30, 2024



Blind face restoration (BFR) on images has significantly progressed over the last several years, while real-world video face restoration (VFR), which is more challenging for more complex face motions such as moving gaze directions and facial orientations involved, remains unsolved. Typical BFR methods are evaluated on privately synthesized datasets or self-collected real-world low-quality face images, which are limited in their coverage of real-world video frames. In this work, we introduced new real-world datasets named FOS with a taxonomy of "Full, Occluded, and Side" faces from mainly video frames to study the applicability of current methods on videos. Compared with existing test datasets, FOS datasets cover more diverse degradations and involve face samples from more complex scenarios, which helps to revisit current face restoration approaches more comprehensively. Given the established datasets, we benchmarked both the state-of-the-art BFR methods and the video super resolution (VSR) methods to comprehensively study current approaches, identifying their potential and limitations in VFR tasks. In addition, we studied the effectiveness of the commonly used image quality assessment (IQA) metrics and face IQA (FIQA) metrics by leveraging a subjective user study. With extensive experimental results and detailed analysis provided, we gained insights from the successes and failures of both current BFR and VSR methods. These results also pose challenges to current face restoration approaches, which we hope stimulate future advances in VFR research.
DiffBIR: Towards Blind Image Restoration with Generative Diffusion Prior
Aug 29, 2023

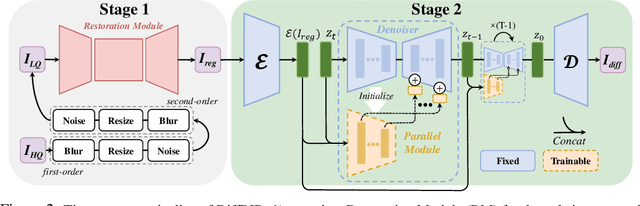
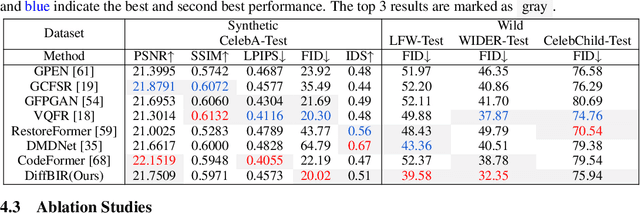
We present DiffBIR, which leverages pretrained text-to-image diffusion models for blind image restoration problem. Our framework adopts a two-stage pipeline. In the first stage, we pretrain a restoration module across diversified degradations to improve generalization capability in real-world scenarios. The second stage leverages the generative ability of latent diffusion models, to achieve realistic image restoration. Specifically, we introduce an injective modulation sub-network -- LAControlNet for finetuning, while the pre-trained Stable Diffusion is to maintain its generative ability. Finally, we introduce a controllable module that allows users to balance quality and fidelity by introducing the latent image guidance in the denoising process during inference. Extensive experiments have demonstrated its superiority over state-of-the-art approaches for both blind image super-resolution and blind face restoration tasks on synthetic and real-world datasets. The code is available at https://github.com/XPixelGroup/DiffBIR.