 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal-Privacy Audit Workflow for Synthetic and Distilled Data in Dropout Support
Jun 14, 2026Synthetic and distilled student data are increasingly used to enable privacy-conscious learning analytics, yet their suitability for decision-facing institutional support remains uncertain. In dropout support, generated data must preserve not only predictive utility or distributional resemblance, but also the financial-status evidence used to guide advising, payment-plan assistance, and scholarship-related decisions. Method: This study introduces CaP-Eval, a decision-facing causal-privacy audit workflow for evaluating generated student data under a fixed estimand, timing-aware adjustment design, estimator set, and empirical privacy-governance screen. The workflow compares original, distilled, adversarial synthetic, statistical synthetic, and DPGNet privacy-oriented generated data on predictive utility, treatment-effect fidelity, robustness to alternative estimators, and local training-record proximity. Results: DPGNet and distilled data preserved the original financial-status treatment-effect structure more reliably than the adversarial and Gaussian Copula baselines. DPGNet preserved full direction and rank agreement across epsilon levels; epsilon = 10 produced the smallest non-original IPW and DML deviations, while epsilon = 1 and epsilon = 5 amplified several financial-status contrasts. Distilled data remained highly faithful but retained the strongest local training-record proximity signal. TabularGNet preserved qualitative directions with moderate attenuation, and Gaussian Copula compressed effect magnitudes. Conclusions: Predictive utility, privacy orientation, empirical disclosure signals, and causal fidelity diverged; generated student data require joint audits of direction, magnitude, overlap, and release-governance risk before decision use.
Skywork UniPic 2.0: Building Kontext Model with Online RL for Unified Multimodal Model
Sep 04, 2025

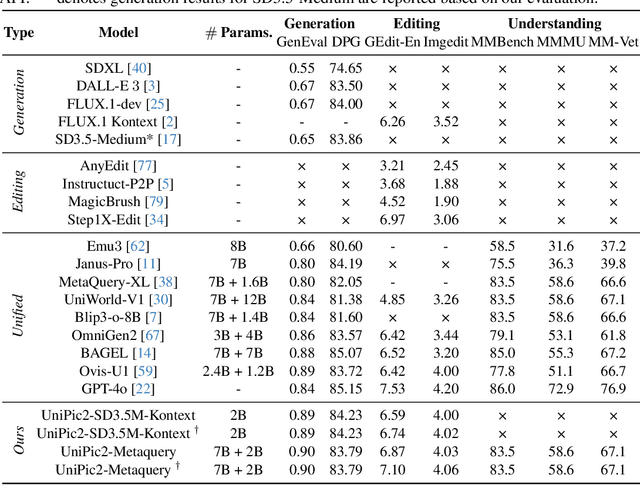
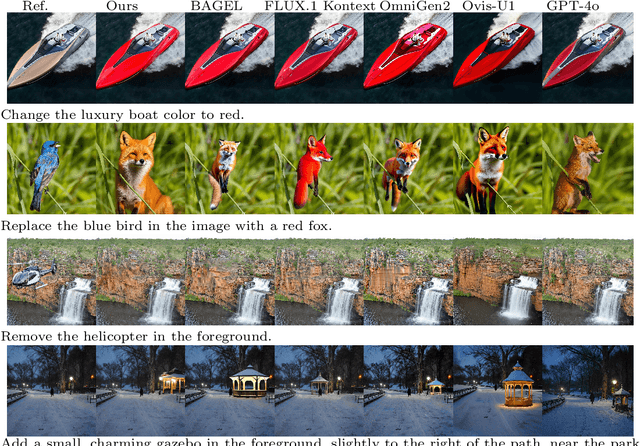
Recent advances in multimodal models have demonstrated impressive capabilities in unified image generation and editing. However, many prominent open-source models prioritize scaling model parameters over optimizing training strategies, limiting their efficiency and performance. In this work, we present UniPic2-SD3.5M-Kontext, a 2B-parameter DiT model based on SD3.5-Medium, which achieves state-of-the-art image generation and editing while extending seamlessly into a unified multimodal framework. Our approach begins with architectural modifications to SD3.5-Medium and large-scale pre-training on high-quality data, enabling joint text-to-image generation and editing capabilities. To enhance instruction following and editing consistency, we propose a novel Progressive Dual-Task Reinforcement strategy (PDTR), which effectively strengthens both tasks in a staged manner. We empirically validate that the reinforcement phases for different tasks are mutually beneficial and do not induce negative interference. After pre-training and reinforcement strategies, UniPic2-SD3.5M-Kontext demonstrates stronger image generation and editing capabilities than models with significantly larger generation parameters-including BAGEL (7B) and Flux-Kontext (12B). Furthermore, following the MetaQuery, we connect the UniPic2-SD3.5M-Kontext and Qwen2.5-VL-7B via a connector and perform joint training to launch a unified multimodal model UniPic2-Metaquery. UniPic2-Metaquery integrates understanding, generation, and editing, achieving top-tier performance across diverse tasks with a simple and scalable training paradigm. This consistently validates the effectiveness and generalizability of our proposed training paradigm, which we formalize as Skywork UniPic 2.0.
Cut2Next: Generating Next Shot via In-Context Tuning
Aug 12, 2025Effective multi-shot generation demands purposeful, film-like transitions and strict cinematic continuity. Current methods, however, often prioritize basic visual consistency, neglecting crucial editing patterns (e.g., shot/reverse shot, cutaways) that drive narrative flow for compelling storytelling. This yields outputs that may be visually coherent but lack narrative sophistication and true cinematic integrity. To bridge this, we introduce Next Shot Generation (NSG): synthesizing a subsequent, high-quality shot that critically conforms to professional editing patterns while upholding rigorous cinematic continuity. Our framework, Cut2Next, leverages a Diffusion Transformer (DiT). It employs in-context tuning guided by a novel Hierarchical Multi-Prompting strategy. This strategy uses Relational Prompts to define overall context and inter-shot editing styles. Individual Prompts then specify per-shot content and cinematographic attributes. Together, these guide Cut2Next to generate cinematically appropriate next shots. Architectural innovations, Context-Aware Condition Injection (CACI) and Hierarchical Attention Mask (HAM), further integrate these diverse signals without introducing new parameters. We construct RawCuts (large-scale) and CuratedCuts (refined) datasets, both with hierarchical prompts, and introduce CutBench for evaluation. Experiments show Cut2Next excels in visual consistency and text fidelity. Crucially, user studies reveal a strong preference for Cut2Next, particularly for its adherence to intended editing patterns and overall cinematic continuity, validating its ability to generate high-quality, narratively expressive, and cinematically coherent subsequent shots.
ShotBench: Expert-Level Cinematic Understanding in Vision-Language Models
Jun 26, 2025Cinematography, the fundamental visual language of film, is essential for conveying narrative, emotion, and aesthetic quality. While recent Vision-Language Models (VLMs) demonstrate strong general visual understanding, their proficiency in comprehending the nuanced cinematic grammar embedded within individual shots remains largely unexplored and lacks robust evaluation. This critical gap limits both fine-grained visual comprehension and the precision of AI-assisted video generation. To address this, we introduce \textbf{ShotBench}, a comprehensive benchmark specifically designed for cinematic language understanding. It features over 3.5k expert-annotated QA pairs from images and video clips, meticulously curated from over 200 acclaimed (predominantly Oscar-nominated) films and spanning eight key cinematography dimensions. Our evaluation of 24 leading VLMs on ShotBench reveals their substantial limitations: even the top-performing model achieves less than 60\% average accuracy, particularly struggling with fine-grained visual cues and complex spatial reasoning. To catalyze advancement in this domain, we construct \textbf{ShotQA}, a large-scale multimodal dataset comprising approximately 70k cinematic QA pairs. Leveraging ShotQA, we develop \textbf{ShotVL} through supervised fine-tuning and Group Relative Policy Optimization. ShotVL significantly outperforms all existing open-source and proprietary models on ShotBench, establishing new \textbf{state-of-the-art} performance. We open-source our models, data, and code to foster rapid progress in this crucial area of AI-driven cinematic understanding and generation.
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Mar 27, 2025Video generation has advanced significantly, evolving from producing unrealistic outputs to generating videos that appear visually convincing and temporally coherent. To evaluate these video generative models, benchmarks such as VBench have been developed to assess their faithfulness, measuring factors like per-frame aesthetics, temporal consistency, and basic prompt adherence. However, these aspects mainly represent superficial faithfulness, which focus on whether the video appears visually convincing rather than whether it adheres to real-world principles. While recent models perform increasingly well on these metrics, they still struggle to generate videos that are not just visually plausible but fundamentally realistic. To achieve real "world models" through video generation, the next frontier lies in intrinsic faithfulness to ensure that generated videos adhere to physical laws, commonsense reasoning, anatomical correctness, and compositional integrity. Achieving this level of realism is essential for applications such as AI-assisted filmmaking and simulated world modeling. To bridge this gap, we introduce VBench-2.0, a next-generation benchmark designed to automatically evaluate video generative models for their intrinsic faithfulness. VBench-2.0 assesses five key dimensions: Human Fidelity, Controllability, Creativity, Physics, and Commonsense, each further broken down into fine-grained capabilities. Tailored for individual dimensions, our evaluation framework integrates generalists such as state-of-the-art VLMs and LLMs, and specialists, including anomaly detection methods proposed for video generation. We conduct extensive annotations to ensure alignment with human judgment. By pushing beyond superficial faithfulness toward intrinsic faithfulness, VBench-2.0 aims to set a new standard for the next generation of video generative models in pursuit of intrinsic faithfulness.
Vchitect-2.0: Parallel Transformer for Scaling Up Video Diffusion Models
Jan 14, 2025
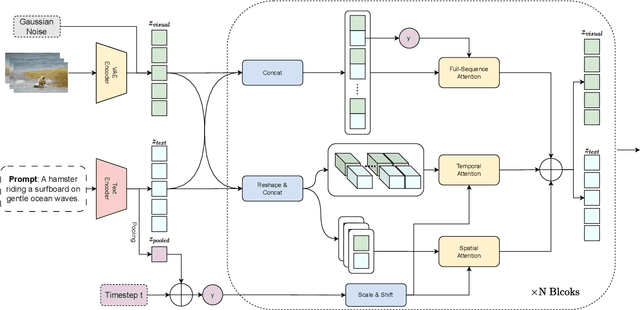
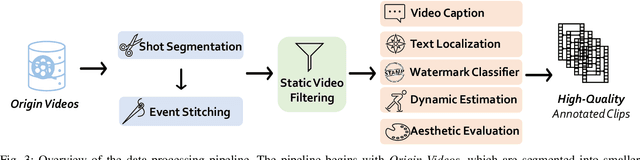
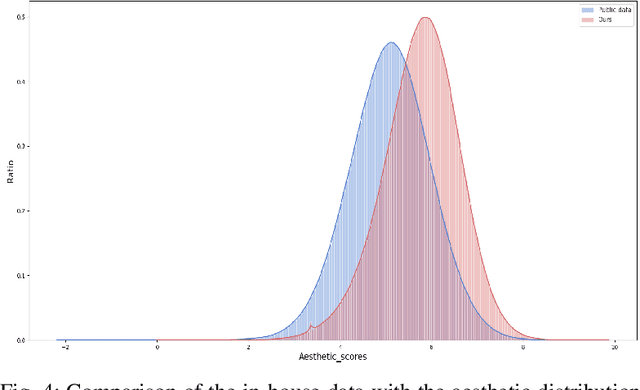
We present Vchitect-2.0, a parallel transformer architecture designed to scale up video diffusion models for large-scale text-to-video generation. The overall Vchitect-2.0 system has several key designs. (1) By introducing a novel Multimodal Diffusion Block, our approach achieves consistent alignment between text descriptions and generated video frames, while maintaining temporal coherence across sequences. (2) To overcome memory and computational bottlenecks, we propose a Memory-efficient Training framework that incorporates hybrid parallelism and other memory reduction techniques, enabling efficient training of long video sequences on distributed systems. (3) Additionally, our enhanced data processing pipeline ensures the creation of Vchitect T2V DataVerse, a high-quality million-scale training dataset through rigorous annotation and aesthetic evaluation. Extensive benchmarking demonstrates that Vchitect-2.0 outperforms existing methods in video quality, training efficiency, and scalability, serving as a suitable base for high-fidelity video generation.
MotionStone: Decoupled Motion Intensity Modulation with Diffusion Transformer for Image-to-Video Generation
Dec 08, 2024



The image-to-video (I2V) generation is conditioned on the static image, which has been enhanced recently by the motion intensity as an additional control signal. These motion-aware models are appealing to generate diverse motion patterns, yet there lacks a reliable motion estimator for training such models on large-scale video set in the wild. Traditional metrics, e.g., SSIM or optical flow, are hard to generalize to arbitrary videos, while, it is very tough for human annotators to label the abstract motion intensity neither. Furthermore, the motion intensity shall reveal both local object motion and global camera movement, which has not been studied before. This paper addresses the challenge with a new motion estimator, capable of measuring the decoupled motion intensities of objects and cameras in video. We leverage the contrastive learning on randomly paired videos and distinguish the video with greater motion intensity. Such a paradigm is friendly for annotation and easy to scale up to achieve stable performance on motion estimation. We then present a new I2V model, named MotionStone, developed with the decoupled motion estimator. Experimental results demonstrate the stability of the proposed motion estimator and the state-of-the-art performance of MotionStone on I2V generation. These advantages warrant the decoupled motion estimator to serve as a general plug-in enhancer for both data processing and video generation training.
Imagine360: Immersive 360 Video Generation from Perspective Anchor
Dec 04, 2024



$360^\circ$ videos offer a hyper-immersive experience that allows the viewers to explore a dynamic scene from full 360 degrees. To achieve more user-friendly and personalized content creation in $360^\circ$ video format, we seek to lift standard perspective videos into $360^\circ$ equirectangular videos. To this end, we introduce Imagine360, the first perspective-to-$360^\circ$ video generation framework that creates high-quality $360^\circ$ videos with rich and diverse motion patterns from video anchors. Imagine360 learns fine-grained spherical visual and motion patterns from limited $360^\circ$ video data with several key designs. 1) Firstly we adopt the dual-branch design, including a perspective and a panorama video denoising branch to provide local and global constraints for $360^\circ$ video generation, with motion module and spatial LoRA layers fine-tuned on extended web $360^\circ$ videos. 2) Additionally, an antipodal mask is devised to capture long-range motion dependencies, enhancing the reversed camera motion between antipodal pixels across hemispheres. 3) To handle diverse perspective video inputs, we propose elevation-aware designs that adapt to varying video masking due to changing elevations across frames. Extensive experiments show Imagine360 achieves superior graphics quality and motion coherence among state-of-the-art $360^\circ$ video generation methods. We believe Imagine360 holds promise for advancing personalized, immersive $360^\circ$ video creation.
VEnhancer: Generative Space-Time Enhancement for Video Generation
Jul 10, 2024



We present VEnhancer, a generative space-time enhancement framework that improves the existing text-to-video results by adding more details in spatial domain and synthetic detailed motion in temporal domain. Given a generated low-quality video, our approach can increase its spatial and temporal resolution simultaneously with arbitrary up-sampling space and time scales through a unified video diffusion model. Furthermore, VEnhancer effectively removes generated spatial artifacts and temporal flickering of generated videos. To achieve this, basing on a pretrained video diffusion model, we train a video ControlNet and inject it to the diffusion model as a condition on low frame-rate and low-resolution videos. To effectively train this video ControlNet, we design space-time data augmentation as well as video-aware conditioning. Benefiting from the above designs, VEnhancer yields to be stable during training and shares an elegant end-to-end training manner. Extensive experiments show that VEnhancer surpasses existing state-of-the-art video super-resolution and space-time super-resolution methods in enhancing AI-generated videos. Moreover, with VEnhancer, exisiting open-source state-of-the-art text-to-video method, VideoCrafter-2, reaches the top one in video generation benchmark -- VBench.
ResMaster: Mastering High-Resolution Image Generation via Structural and Fine-Grained Guidance
Jun 24, 2024



Diffusion models excel at producing high-quality images; however, scaling to higher resolutions, such as 4K, often results in over-smoothed content, structural distortions, and repetitive patterns. To this end, we introduce ResMaster, a novel, training-free method that empowers resolution-limited diffusion models to generate high-quality images beyond resolution restrictions. Specifically, ResMaster leverages a low-resolution reference image created by a pre-trained diffusion model to provide structural and fine-grained guidance for crafting high-resolution images on a patch-by-patch basis. To ensure a coherent global structure, ResMaster meticulously aligns the low-frequency components of high-resolution patches with the low-resolution reference at each denoising step. For fine-grained guidance, tailored image prompts based on the low-resolution reference and enriched textual prompts produced by a vision-language model are incorporated. This approach could significantly mitigate local pattern distortions and improve detail refinement. Extensive experiments validate that ResMaster sets a new benchmark for high-resolution image generation and demonstrates promising efficiency. The project page is https://shuweis.github.io/ResMaster .