 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeError Analysis of Bayesian Inverse Problems with Generative Priors
Jan 24, 2026Data-driven methods for the solution of inverse problems have become widely popular in recent years thanks to the rise of machine learning techniques. A popular approach concerns the training of a generative model on additional data to learn a bespoke prior for the problem at hand. In this article we present an analysis for such problems by presenting quantitative error bounds for minimum Wasserstein-2 generative models for the prior. We show that under some assumptions, the error in the posterior due to the generative prior will inherit the same rate as the prior with respect to the Wasserstein-1 distance. We further present numerical experiments that verify that aspects of our error analysis manifests in some benchmarks followed by an elliptic PDE inverse problem where a generative prior is used to model a non-stationary field.
BabyVision: Visual Reasoning Beyond Language
Jan 10, 2026While humans develop core visual skills long before acquiring language, contemporary Multimodal LLMs (MLLMs) still rely heavily on linguistic priors to compensate for their fragile visual understanding. We uncovered a crucial fact: state-of-the-art MLLMs consistently fail on basic visual tasks that humans, even 3-year-olds, can solve effortlessly. To systematically investigate this gap, we introduce BabyVision, a benchmark designed to assess core visual abilities independent of linguistic knowledge for MLLMs. BabyVision spans a wide range of tasks, with 388 items divided into 22 subclasses across four key categories. Empirical results and human evaluation reveal that leading MLLMs perform significantly below human baselines. Gemini3-Pro-Preview scores 49.7, lagging behind 6-year-old humans and falling well behind the average adult score of 94.1. These results show despite excelling in knowledge-heavy evaluations, current MLLMs still lack fundamental visual primitives. Progress in BabyVision represents a step toward human-level visual perception and reasoning capabilities. We also explore solving visual reasoning with generation models by proposing BabyVision-Gen and automatic evaluation toolkit. Our code and benchmark data are released at https://github.com/UniPat-AI/BabyVision for reproduction.
Exploring MLLM-Diffusion Information Transfer with MetaCanvas
Dec 12, 2025Multimodal learning has rapidly advanced visual understanding, largely via multimodal large language models (MLLMs) that use powerful LLMs as cognitive cores. In visual generation, however, these powerful core models are typically reduced to global text encoders for diffusion models, leaving most of their reasoning and planning ability unused. This creates a gap: current multimodal LLMs can parse complex layouts, attributes, and knowledge-intensive scenes, yet struggle to generate images or videos with equally precise and structured control. We propose MetaCanvas, a lightweight framework that lets MLLMs reason and plan directly in spatial and spatiotemporal latent spaces and interface tightly with diffusion generators. We empirically implement MetaCanvas on three different diffusion backbones and evaluate it across six tasks, including text-to-image generation, text/image-to-video generation, image/video editing, and in-context video generation, each requiring precise layouts, robust attribute binding, and reasoning-intensive control. MetaCanvas consistently outperforms global-conditioning baselines, suggesting that treating MLLMs as latent-space planners is a promising direction for narrowing the gap between multimodal understanding and generation.
WorldLens: Full-Spectrum Evaluations of Driving World Models in Real World
Dec 11, 2025Generative world models are reshaping embodied AI, enabling agents to synthesize realistic 4D driving environments that look convincing but often fail physically or behaviorally. Despite rapid progress, the field still lacks a unified way to assess whether generated worlds preserve geometry, obey physics, or support reliable control. We introduce WorldLens, a full-spectrum benchmark evaluating how well a model builds, understands, and behaves within its generated world. It spans five aspects -- Generation, Reconstruction, Action-Following, Downstream Task, and Human Preference -- jointly covering visual realism, geometric consistency, physical plausibility, and functional reliability. Across these dimensions, no existing world model excels universally: those with strong textures often violate physics, while geometry-stable ones lack behavioral fidelity. To align objective metrics with human judgment, we further construct WorldLens-26K, a large-scale dataset of human-annotated videos with numerical scores and textual rationales, and develop WorldLens-Agent, an evaluation model distilled from these annotations to enable scalable, explainable scoring. Together, the benchmark, dataset, and agent form a unified ecosystem for measuring world fidelity -- standardizing how future models are judged not only by how real they look, but by how real they behave.
Simulating the Visual World with Artificial Intelligence: A Roadmap
Nov 11, 2025The landscape of video generation is shifting, from a focus on generating visually appealing clips to building virtual environments that support interaction and maintain physical plausibility. These developments point toward the emergence of video foundation models that function not only as visual generators but also as implicit world models, models that simulate the physical dynamics, agent-environment interactions, and task planning that govern real or imagined worlds. This survey provides a systematic overview of this evolution, conceptualizing modern video foundation models as the combination of two core components: an implicit world model and a video renderer. The world model encodes structured knowledge about the world, including physical laws, interaction dynamics, and agent behavior. It serves as a latent simulation engine that enables coherent visual reasoning, long-term temporal consistency, and goal-driven planning. The video renderer transforms this latent simulation into realistic visual observations, effectively producing videos as a "window" into the simulated world. We trace the progression of video generation through four generations, in which the core capabilities advance step by step, ultimately culminating in a world model, built upon a video generation model, that embodies intrinsic physical plausibility, real-time multimodal interaction, and planning capabilities spanning multiple spatiotemporal scales. For each generation, we define its core characteristics, highlight representative works, and examine their application domains such as robotics, autonomous driving, and interactive gaming. Finally, we discuss open challenges and design principles for next-generation world models, including the role of agent intelligence in shaping and evaluating these systems. An up-to-date list of related works is maintained at this link.
The Quest for Generalizable Motion Generation: Data, Model, and Evaluation
Oct 30, 2025Despite recent advances in 3D human motion generation (MoGen) on standard benchmarks, existing models still face a fundamental bottleneck in their generalization capability. In contrast, adjacent generative fields, most notably video generation (ViGen), have demonstrated remarkable generalization in modeling human behaviors, highlighting transferable insights that MoGen can leverage. Motivated by this observation, we present a comprehensive framework that systematically transfers knowledge from ViGen to MoGen across three key pillars: data, modeling, and evaluation. First, we introduce ViMoGen-228K, a large-scale dataset comprising 228,000 high-quality motion samples that integrates high-fidelity optical MoCap data with semantically annotated motions from web videos and synthesized samples generated by state-of-the-art ViGen models. The dataset includes both text-motion pairs and text-video-motion triplets, substantially expanding semantic diversity. Second, we propose ViMoGen, a flow-matching-based diffusion transformer that unifies priors from MoCap data and ViGen models through gated multimodal conditioning. To enhance efficiency, we further develop ViMoGen-light, a distilled variant that eliminates video generation dependencies while preserving strong generalization. Finally, we present MBench, a hierarchical benchmark designed for fine-grained evaluation across motion quality, prompt fidelity, and generalization ability. Extensive experiments show that our framework significantly outperforms existing approaches in both automatic and human evaluations. The code, data, and benchmark will be made publicly available.
RealDPO: Real or Not Real, that is the Preference
Oct 16, 2025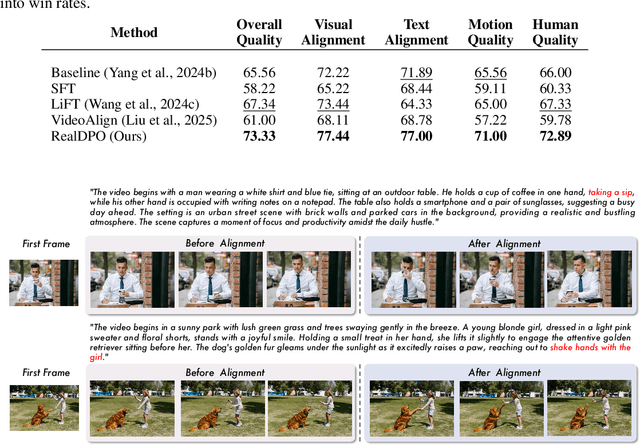

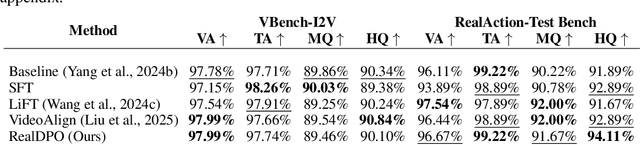
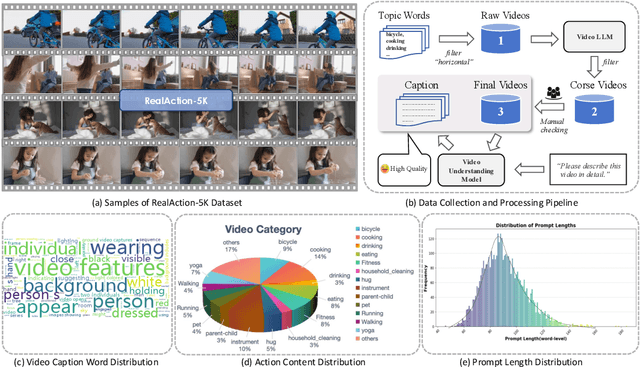
Video generative models have recently achieved notable advancements in synthesis quality. However, generating complex motions remains a critical challenge, as existing models often struggle to produce natural, smooth, and contextually consistent movements. This gap between generated and real-world motions limits their practical applicability. To address this issue, we introduce RealDPO, a novel alignment paradigm that leverages real-world data as positive samples for preference learning, enabling more accurate motion synthesis. Unlike traditional supervised fine-tuning (SFT), which offers limited corrective feedback, RealDPO employs Direct Preference Optimization (DPO) with a tailored loss function to enhance motion realism. By contrasting real-world videos with erroneous model outputs, RealDPO enables iterative self-correction, progressively refining motion quality. To support post-training in complex motion synthesis, we propose RealAction-5K, a curated dataset of high-quality videos capturing human daily activities with rich and precise motion details. Extensive experiments demonstrate that RealDPO significantly improves video quality, text alignment, and motion realism compared to state-of-the-art models and existing preference optimization techniques.
VChain: Chain-of-Visual-Thought for Reasoning in Video Generation
Oct 06, 2025Recent video generation models can produce smooth and visually appealing clips, but they often struggle to synthesize complex dynamics with a coherent chain of consequences. Accurately modeling visual outcomes and state transitions over time remains a core challenge. In contrast, large language and multimodal models (e.g., GPT-4o) exhibit strong visual state reasoning and future prediction capabilities. To bridge these strengths, we introduce VChain, a novel inference-time chain-of-visual-thought framework that injects visual reasoning signals from multimodal models into video generation. Specifically, VChain contains a dedicated pipeline that leverages large multimodal models to generate a sparse set of critical keyframes as snapshots, which are then used to guide the sparse inference-time tuning of a pre-trained video generator only at these key moments. Our approach is tuning-efficient, introduces minimal overhead and avoids dense supervision. Extensive experiments on complex, multi-step scenarios show that VChain significantly enhances the quality of generated videos.
Cut2Next: Generating Next Shot via In-Context Tuning
Aug 12, 2025Effective multi-shot generation demands purposeful, film-like transitions and strict cinematic continuity. Current methods, however, often prioritize basic visual consistency, neglecting crucial editing patterns (e.g., shot/reverse shot, cutaways) that drive narrative flow for compelling storytelling. This yields outputs that may be visually coherent but lack narrative sophistication and true cinematic integrity. To bridge this, we introduce Next Shot Generation (NSG): synthesizing a subsequent, high-quality shot that critically conforms to professional editing patterns while upholding rigorous cinematic continuity. Our framework, Cut2Next, leverages a Diffusion Transformer (DiT). It employs in-context tuning guided by a novel Hierarchical Multi-Prompting strategy. This strategy uses Relational Prompts to define overall context and inter-shot editing styles. Individual Prompts then specify per-shot content and cinematographic attributes. Together, these guide Cut2Next to generate cinematically appropriate next shots. Architectural innovations, Context-Aware Condition Injection (CACI) and Hierarchical Attention Mask (HAM), further integrate these diverse signals without introducing new parameters. We construct RawCuts (large-scale) and CuratedCuts (refined) datasets, both with hierarchical prompts, and introduce CutBench for evaluation. Experiments show Cut2Next excels in visual consistency and text fidelity. Crucially, user studies reveal a strong preference for Cut2Next, particularly for its adherence to intended editing patterns and overall cinematic continuity, validating its ability to generate high-quality, narratively expressive, and cinematically coherent subsequent shots.
MAViS: A Multi-Agent Framework for Long-Sequence Video Storytelling
Aug 11, 2025Despite recent advances, long-sequence video generation frameworks still suffer from significant limitations: poor assistive capability, suboptimal visual quality, and limited expressiveness. To mitigate these limitations, we propose MAViS, an end-to-end multi-agent collaborative framework for long-sequence video storytelling. MAViS orchestrates specialized agents across multiple stages, including script writing, shot designing, character modeling, keyframe generation, video animation, and audio generation. In each stage, agents operate under the 3E Principle -- Explore, Examine, and Enhance -- to ensure the completeness of intermediate outputs. Considering the capability limitations of current generative models, we propose the Script Writing Guidelines to optimize compatibility between scripts and generative tools. Experimental results demonstrate that MAViS achieves state-of-the-art performance in assistive capability, visual quality, and video expressiveness. Its modular framework further enables scalability with diverse generative models and tools. With just a brief user prompt, MAViS is capable of producing high-quality, expressive long-sequence video storytelling, enriching inspirations and creativity for users. To the best of our knowledge, MAViS is the only framework that provides multimodal design output -- videos with narratives and background music.