 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldMark: A Unified Benchmark Suite for Interactive Video World Models
Apr 23, 2026Interactive video generation models such as Genie, YUME, HY-World, and Matrix-Game are advancing rapidly, yet every model is evaluated on its own benchmark with private scenes and trajectories, making fair cross-model comparison impossible. Existing public benchmarks offer useful metrics such as trajectory error, aesthetic scores, and VLM-based judgments, but none supplies the standardized test conditions -- identical scenes, identical action sequences, and a unified control interface -- needed to make those metrics comparable across models with heterogeneous inputs. We introduce WorldMark, the first benchmark that provides such a common playing field for interactive Image-to-Video world models. WorldMark contributes: (1) a unified action-mapping layer that translates a shared WASD-style action vocabulary into each model's native control format, enabling apples-to-apples comparison across six major models on identical scenes and trajectories; (2) a hierarchical test suite of 500 evaluation cases covering first- and third-person viewpoints, photorealistic and stylized scenes, and three difficulty tiers from Easy to Hard spanning 20-60s; and (3) a modular evaluation toolkit for Visual Quality, Control Alignment, and World Consistency, designed so that researchers can reuse our standardized inputs while plugging in their own metrics as the field evolves. We will release all data, evaluation code, and model outputs to facilitate future research. Beyond offline metrics, we launch World Model Arena (warena.ai), an online platform where anyone can pit leading world models against each other in side-by-side battles and watch the live leaderboard.
Yume-1.5: A Text-Controlled Interactive World Generation Model
Dec 26, 2025Recent approaches have demonstrated the promise of using diffusion models to generate interactive and explorable worlds. However, most of these methods face critical challenges such as excessively large parameter sizes, reliance on lengthy inference steps, and rapidly growing historical context, which severely limit real-time performance and lack text-controlled generation capabilities. To address these challenges, we propose \method, a novel framework designed to generate realistic, interactive, and continuous worlds from a single image or text prompt. \method achieves this through a carefully designed framework that supports keyboard-based exploration of the generated worlds. The framework comprises three core components: (1) a long-video generation framework integrating unified context compression with linear attention; (2) a real-time streaming acceleration strategy powered by bidirectional attention distillation and an enhanced text embedding scheme; (3) a text-controlled method for generating world events. We have provided the codebase in the supplementary material.
SVBench: Evaluation of Video Generation Models on Social Reasoning
Dec 25, 2025Recent text-to-video generation models exhibit remarkable progress in visual realism, motion fidelity, and text-video alignment, yet they remain fundamentally limited in their ability to generate socially coherent behavior. Unlike humans, who effortlessly infer intentions, beliefs, emotions, and social norms from brief visual cues, current models tend to render literal scenes without capturing the underlying causal or psychological logic. To systematically evaluate this gap, we introduce the first benchmark for social reasoning in video generation. Grounded in findings from developmental and social psychology, our benchmark organizes thirty classic social cognition paradigms into seven core dimensions, including mental-state inference, goal-directed action, joint attention, social coordination, prosocial behavior, social norms, and multi-agent strategy. To operationalize these paradigms, we develop a fully training-free agent-based pipeline that (i) distills the reasoning mechanism of each experiment, (ii) synthesizes diverse video-ready scenarios, (iii) enforces conceptual neutrality and difficulty control through cue-based critique, and (iv) evaluates generated videos using a high-capacity VLM judge across five interpretable dimensions of social reasoning. Using this framework, we conduct the first large-scale study across seven state-of-the-art video generation systems. Our results reveal substantial performance gaps: while modern models excel in surface-level plausibility, they systematically fail in intention recognition, belief reasoning, joint attention, and prosocial inference.
PreGenie: An Agentic Framework for High-quality Visual Presentation Generation
May 27, 2025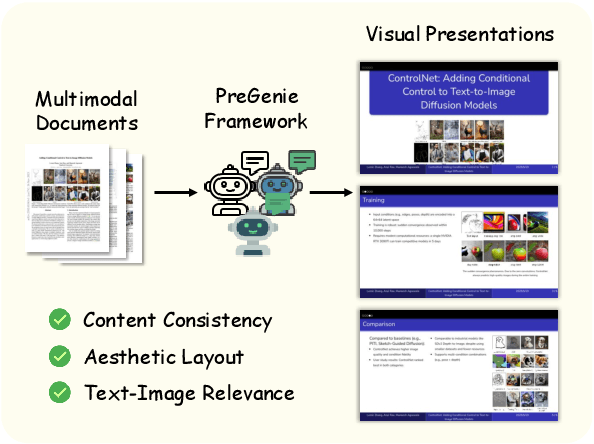



Visual presentations are vital for effective communication. Early attempts to automate their creation using deep learning often faced issues such as poorly organized layouts, inaccurate text summarization, and a lack of image understanding, leading to mismatched visuals and text. These limitations restrict their application in formal contexts like business and scientific research. To address these challenges, we propose PreGenie, an agentic and modular framework powered by multimodal large language models (MLLMs) for generating high-quality visual presentations. PreGenie is built on the Slidev presentation framework, where slides are rendered from Markdown code. It operates in two stages: (1) Analysis and Initial Generation, which summarizes multimodal input and generates initial code, and (2) Review and Re-generation, which iteratively reviews intermediate code and rendered slides to produce final, high-quality presentations. Each stage leverages multiple MLLMs that collaborate and share information. Comprehensive experiments demonstrate that PreGenie excels in multimodal understanding, outperforming existing models in both aesthetics and content consistency, while aligning more closely with human design preferences.
POSTA: A Go-to Framework for Customized Artistic Poster Generation
Mar 19, 2025


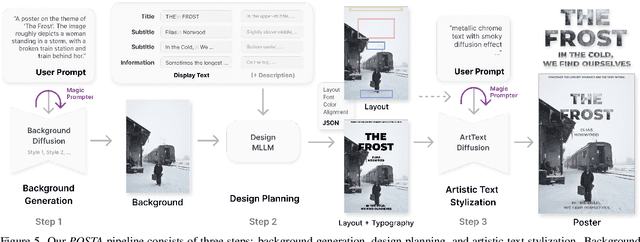
Poster design is a critical medium for visual communication. Prior work has explored automatic poster design using deep learning techniques, but these approaches lack text accuracy, user customization, and aesthetic appeal, limiting their applicability in artistic domains such as movies and exhibitions, where both clear content delivery and visual impact are essential. To address these limitations, we present POSTA: a modular framework powered by diffusion models and multimodal large language models (MLLMs) for customized artistic poster generation. The framework consists of three modules. Background Diffusion creates a themed background based on user input. Design MLLM then generates layout and typography elements that align with and complement the background style. Finally, to enhance the poster's aesthetic appeal, ArtText Diffusion applies additional stylization to key text elements. The final result is a visually cohesive and appealing poster, with a fully modular process that allows for complete customization. To train our models, we develop the PosterArt dataset, comprising high-quality artistic posters annotated with layout, typography, and pixel-level stylized text segmentation. Our comprehensive experimental analysis demonstrates POSTA's exceptional controllability and design diversity, outperforming existing models in both text accuracy and aesthetic quality.
Long-Video Audio Synthesis with Multi-Agent Collaboration
Mar 17, 2025Video-to-audio synthesis, which generates synchronized audio for visual content, critically enhances viewer immersion and narrative coherence in film and interactive media. However, video-to-audio dubbing for long-form content remains an unsolved challenge due to dynamic semantic shifts, temporal misalignment, and the absence of dedicated datasets. While existing methods excel in short videos, they falter in long scenarios (e.g., movies) due to fragmented synthesis and inadequate cross-scene consistency. We propose LVAS-Agent, a novel multi-agent framework that emulates professional dubbing workflows through collaborative role specialization. Our approach decomposes long-video synthesis into four steps including scene segmentation, script generation, sound design and audio synthesis. Central innovations include a discussion-correction mechanism for scene/script refinement and a generation-retrieval loop for temporal-semantic alignment. To enable systematic evaluation, we introduce LVAS-Bench, the first benchmark with 207 professionally curated long videos spanning diverse scenarios. Experiments demonstrate superior audio-visual alignment over baseline methods. Project page: https://lvas-agent.github.io
Reflection of Episodes: Learning to Play Game from Expert and Self Experiences
Feb 19, 2025

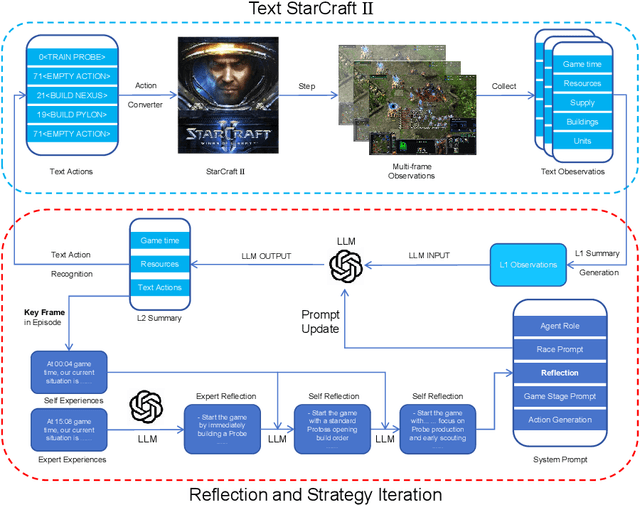

StarCraft II is a complex and dynamic real-time strategy (RTS) game environment, which is very suitable for artificial intelligence and reinforcement learning research. To address the problem of Large Language Model(LLM) learning in complex environments through self-reflection, we propose a Reflection of Episodes(ROE) framework based on expert experience and self-experience. This framework first obtains key information in the game through a keyframe selection method, then makes decisions based on expert experience and self-experience. After a game is completed, it reflects on the previous experience to obtain new self-experience. Finally, in the experiment, our method beat the robot under the Very Hard difficulty in TextStarCraft II. We analyze the data of the LLM in the process of the game in detail, verified its effectiveness.
Decoding Interpretable Logic Rules from Neural Networks
Jan 14, 2025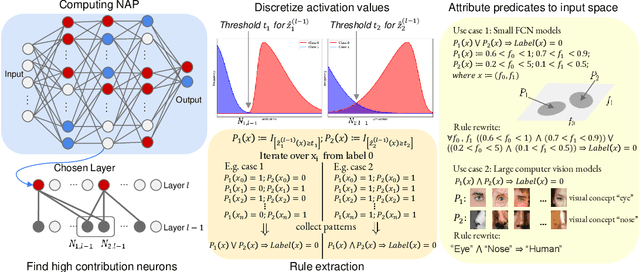
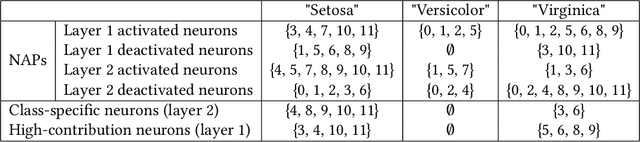
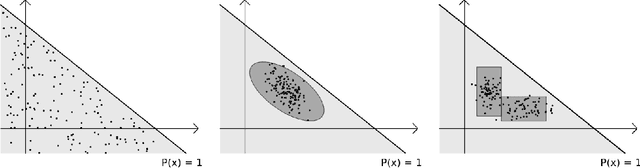
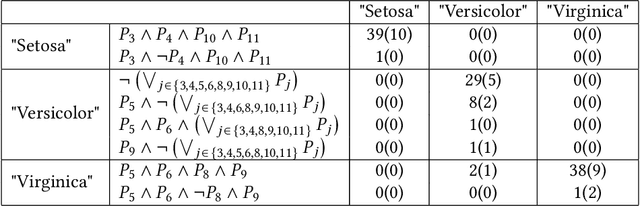
As deep neural networks continue to excel across various domains, their black-box nature has raised concerns about transparency and trust. In particular, interpretability has become increasingly essential for applications that demand high safety and knowledge rigor, such as drug discovery, autonomous driving, and genomics. However, progress in understanding even the simplest deep neural networks - such as fully connected networks - has been limited, despite their role as foundational elements in state-of-the-art models like ResNet and Transformer. In this paper, we address this challenge by introducing NeuroLogic, a novel approach for decoding interpretable logic rules from neural networks. NeuroLogic leverages neural activation patterns to capture the model's critical decision-making processes, translating them into logical rules represented by hidden predicates. Thanks to its flexible design in the grounding phase, NeuroLogic can be adapted to a wide range of neural networks. For simple fully connected neural networks, hidden predicates can be grounded in certain split patterns of original input features to derive decision-tree-like rules. For large, complex vision neural networks, NeuroLogic grounds hidden predicates into high-level visual concepts that are understandable to humans. Our empirical study demonstrates that NeuroLogic can extract global and interpretable rules from state-of-the-art models such as ResNet, a task at which existing work struggles. We believe NeuroLogic can help pave the way for understanding the black-box nature of neural networks.
VBench++: Comprehensive and Versatile Benchmark Suite for Video Generative Models
Nov 20, 2024



Video generation has witnessed significant advancements, yet evaluating these models remains a challenge. A comprehensive evaluation benchmark for video generation is indispensable for two reasons: 1) Existing metrics do not fully align with human perceptions; 2) An ideal evaluation system should provide insights to inform future developments of video generation. To this end, we present VBench, a comprehensive benchmark suite that dissects "video generation quality" into specific, hierarchical, and disentangled dimensions, each with tailored prompts and evaluation methods. VBench has several appealing properties: 1) Comprehensive Dimensions: VBench comprises 16 dimensions in video generation (e.g., subject identity inconsistency, motion smoothness, temporal flickering, and spatial relationship, etc). The evaluation metrics with fine-grained levels reveal individual models' strengths and weaknesses. 2) Human Alignment: We also provide a dataset of human preference annotations to validate our benchmarks' alignment with human perception, for each evaluation dimension respectively. 3) Valuable Insights: We look into current models' ability across various evaluation dimensions, and various content types. We also investigate the gaps between video and image generation models. 4) Versatile Benchmarking: VBench++ supports evaluating text-to-video and image-to-video. We introduce a high-quality Image Suite with an adaptive aspect ratio to enable fair evaluations across different image-to-video generation settings. Beyond assessing technical quality, VBench++ evaluates the trustworthiness of video generative models, providing a more holistic view of model performance. 5) Full Open-Sourcing: We fully open-source VBench++ and continually add new video generation models to our leaderboard to drive forward the field of video generation.
LLM-PySC2: Starcraft II learning environment for Large Language Models
Nov 08, 2024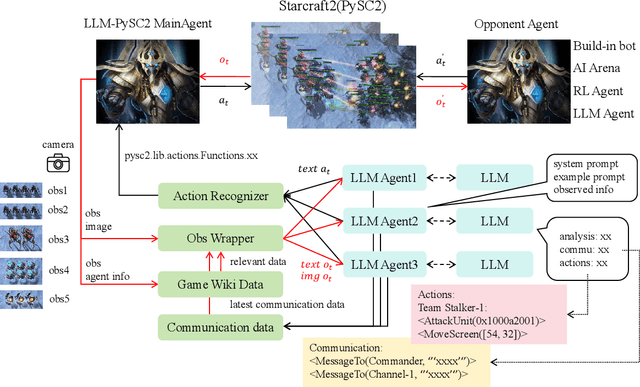
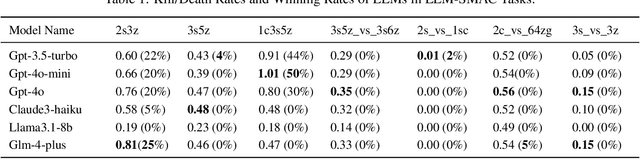
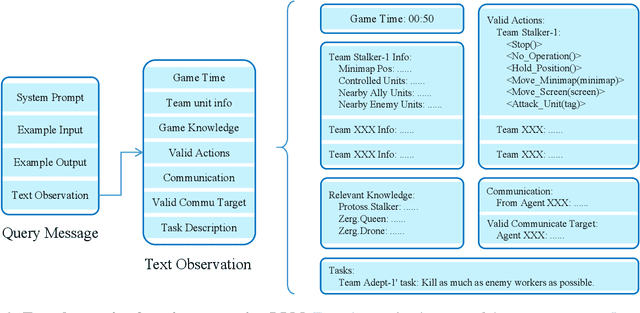

This paper introduces a new environment LLM-PySC2 (the Large Language Model StarCraft II Learning Environment), a platform derived from DeepMind's StarCraft II Learning Environment that serves to develop Large Language Models (LLMs) based decision-making methodologies. This environment is the first to offer the complete StarCraft II action space, multi-modal observation interfaces, and a structured game knowledge database, which are seamlessly connected with various LLMs to facilitate the research of LLMs-based decision-making. To further support multi-agent research, we developed an LLM collaborative framework that supports multi-agent concurrent queries and multi-agent communication. In our experiments, the LLM-PySC2 environment is adapted to be compatible with the StarCraft Multi-Agent Challenge (SMAC) task group and provided eight new scenarios focused on macro-decision abilities. We evaluated nine mainstream LLMs in the experiments, and results show that sufficient parameters are necessary for LLMs to make decisions, but improving reasoning ability does not directly lead to better decision-making outcomes. Our findings further indicate the importance of enabling large models to learn autonomously in the deployment environment through parameter training or train-free learning techniques. Ultimately, we expect that the LLM-PySC2 environment can promote research on learning methods for LLMs, helping LLM-based methods better adapt to task scenarios.