 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoSem-WAM: Geometry- and Semantic-Aware World Action Models
Jun 02, 2026Recent World Action Models (WAMs) have demonstrated impressive capabilities in embodied decision-making. However, whether their effectiveness stems from explicit future imagination during inference or representation learning induced by predictive training remains an open question. Emerging evidence suggests the primary advantage lies in learning robust latent representations rather than generating future observations at test time. Nevertheless, existing WAMs mainly rely on RGB-based future prediction, which provides limited structural and spatial understanding of complex environments. To address this, we propose a structured world modeling framework that enhances latent representations through geometric and semantic supervision. Alongside future RGB prediction, our model introduces two auxiliary prediction branches for future geometry and semantic representations, enabling it to jointly capture scene dynamics, spatial geometry, and semantic context within a unified latent space. Crucially, our approach preserves efficient inference by avoiding explicit future rollout or video generation at test time. Extensive experiments show that incorporating structured world supervision consistently improves action prediction accuracy, scene understanding, and robustness under challenging embodied scenarios, highlighting its potential for advancing scalable and efficient WAMs.
IAF-Net: Illumination-Adaptive Fusion for Low-Light Urban Road Segmentation
May 29, 2026Semantic road segmentation is important for autonomous driving, but existing methods suffer severe performance degradation under low-light conditions. Many existing multi-modal fusion methods do not explicitly adapt to illumination-dependent changes in modality reliability, which can propagate degraded RGB features into the fused representation at night. We propose IAF-Net (Illumination-Adaptive Fusion Network), an end-to-end framework with illumination-adaptive fusion for robust road segmentation across different lighting conditions. It dynamically adjusts fusion weights of RGB and geometric features via the core Illumination-Adaptive Fusion (IAF) module, and enhances low-light feature selection with a brightness-modulated attention decoder. We also construct two dedicated datasets: nuScenes Nighttime Road Segmentation (nuScenes-NRS) and CARLA Multi-Weather Road Segmentation (CARLA-MWRS). Experiments on nuScenes-NRS show state-of-the-art overall performance among the compared methods, while CARLA-MWRS further validates robustness across adverse weather conditions. Ablation studies on a 40% training subset further highlight the importance of the IAF module, which provides the largest individual gain of 0.70% in MaxF.
LiteViLNet: Lightweight Vision-LiDAR Fusion Network for Efficient Road Segmentation
May 20, 2026Road segmentation is a fundamental perception task for autonomous driving and intelligent robotic systems, requiring both high accuracy and real-time inference, especially for deployment on resource-constrained edge devices. Existing multi-modal road segmentation methods often rely on heavy transformer-based encoders to achieve state-of-the-art performance, but their enormous computational cost prohibits real-time deployment on embedded platforms. To address this dilemma, we propose \textbf{LiteViLNet}, a lightweight multi-modal network that fuses RGB texture information and LiDAR geometric information for efficient road segmentation. Specifically, we design a dual-stream lightweight encoder and depth-wise separable convolutions to extract hierarchical features from both modalities with minimal parameters. We further propose a Multi-Scale Feature Fusion Module (MSFM) to facilitate cross-modal interaction at different levels, and a large-kernel-bridge module to capture long-range dependencies with linear complexity. Extensive experiments on the KITTI Road dataset and real-world applications demonstrate that LiteViLNet achieves a promising balance between accuracy and efficiency. Notably, with only 14.04M parameters, our model attains a 96.36\% MaxF score, ranking the best among all CNN-based methods and being comparable to larger transformer-based models, and runs at 163.79 FPS in model-only inference on RTX 4060 Ti (22.18 FPS on Jetson Orin NX). It outperforms numerous heavy-weight methods in inference speed while maintaining highly competitive accuracy, fully validating the potential of LiteViLNet for real-time embedded deployment in autonomous driving and intelligent robotics.
AttenA+: Rectifying Action Inequality in Robotic Foundation Models
May 13, 2026Existing robotic foundation models, while powerful, are predicated on an implicit assumption of temporal homogeneity: treating all actions as equally informative during optimization. This "flat" training paradigm, inherited from language modeling, remains indifferent to the underlying physical hierarchy of manipulation. In reality, robot trajectories are fundamentally heterogeneous, where low-velocity segments often dictate task success through precision-demanding interactions, while high-velocity motions serve as error-tolerant transitions. Such a misalignment between uniform loss weighting and physical criticality fundamentally limits the performance of current Vision-Language-Action (VLA) models and World-Action Models (WAM) in complex, long-horizon tasks. To rectify this, we introduce AttenA+, an architecture-agnostic framework that prioritizes kinematically critical segments via velocity-driven action attention. By reweighting the training objective based on the inverse velocity field, AttenA+ naturally aligns the model's learning capacity with the physical demands of manipulation. As a plug-and-play enhancement, AttenA+ can be integrated into existing backbones without structural modifications or additional parameters. Extensive experiments demonstrate that AttenA+ significantly elevates the ceilings of current state-of-the-art models. Specifically, it improves OpenVLA-OFT to 98.6% (+1.5%) on the Libero benchmark and pushes FastWAM to 92.4% (+0.6%) on RoboTwin 2.0. Real-world validation on a Franka manipulator further showcases its robustness and cross-task generalization. Our work suggests that mining the intrinsic structural priors of action sequences offers a highly efficient, physics-aware complement to standard scaling laws, paving a new path for general-purpose robotic control.
Structured Observation Language for Efficient and Generalizable Vision-Language Navigation
Mar 29, 2026Vision-Language Navigation (VLN) requires an embodied agent to navigate complex environments by following natural language instructions, which typically demands tight fusion of visual and language modalities. Existing VLN methods often convert raw images into visual tokens or implicit features, requiring large-scale visual pre-training and suffering from poor generalization under environmental variations (e.g., lighting, texture). To address these issues, we propose SOL-Nav (Structured Observation Language for Navigation), a novel framework that translates egocentric visual observations into compact structured language descriptions for efficient and generalizable navigation. Specifically, we divide RGB-D images into a N*N grid, extract representative semantic, color, and depth information for each grid cell to form structured text, and concatenate this with the language instruction as pure language input to a pre-trained language model (PLM). Experimental results on standard VLN benchmarks (R2R, RxR) and real-world deployments demonstrate that SOL-Nav significantly reduces the model size and training data dependency, fully leverages the reasoning and representation capabilities of PLMs, and achieves strong generalization to unseen environments.
Annotation-Free Detection of Drivable Areas and Curbs Leveraging LiDAR Point Cloud Maps
Mar 29, 2026Drivable areas and curbs are critical traffic elements for autonomous driving, forming essential components of the vehicle visual perception system and ensuring driving safety. Deep neural networks (DNNs) have significantly improved perception performance for drivable area and curb detection, but most DNN-based methods rely on large manually labeled datasets, which are costly, time-consuming, and expert-dependent, limiting their real-world application. Thus, we developed an automated training data generation module. Our previous work generated training labels using single-frame LiDAR and RGB data, suffering from occlusion and distant point cloud sparsity. In this paper, we propose a novel map-based automatic data labeler (MADL) module, combining LiDAR mapping/localization with curb detection to automatically generate training data for both tasks. MADL avoids occlusion and point cloud sparsity issues via LiDAR mapping, creating accurate large-scale datasets for DNN training. In addition, we construct a data review agent to filter the data generated by the MADL module, eliminating low-quality samples. Experiments on the KITTI, KITTI-CARLA and 3D-Curb datasets show that MADL achieves impressive performance compared to manual labeling, and outperforms traditional and state-of-the-art self-supervised methods in robustness and accuracy.
LHPF: Look back the History and Plan for the Future in Autonomous Driving
Nov 26, 2024Decision-making and planning in autonomous driving critically reflect the safety of the system, making effective planning imperative. Current imitation learning-based planning algorithms often merge historical trajectories with present observations to predict future candidate paths. However, these algorithms typically assess the current and historical plans independently, leading to discontinuities in driving intentions and an accumulation of errors with each step in a discontinuous plan. To tackle this challenge, this paper introduces LHPF, an imitation learning planner that integrates historical planning information. Our approach employs a historical intention aggregation module that pools historical planning intentions, which are then combined with a spatial query vector to decode the final planning trajectory. Furthermore, we incorporate a comfort auxiliary task to enhance the human-like quality of the driving behavior. Extensive experiments using both real-world and synthetic data demonstrate that LHPF not only surpasses existing advanced learning-based planners in planning performance but also marks the first instance of a purely learning-based planner outperforming the expert. Additionally, the application of the historical intention aggregation module across various backbones highlights the considerable potential of the proposed method. The code will be made publicly available.
Task-Oriented Pre-Training for Drivable Area Detection
Sep 30, 2024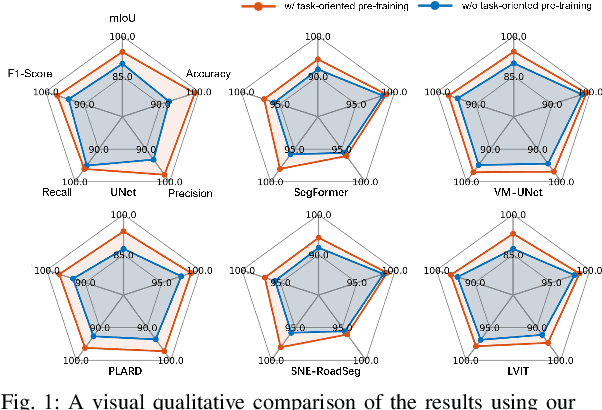
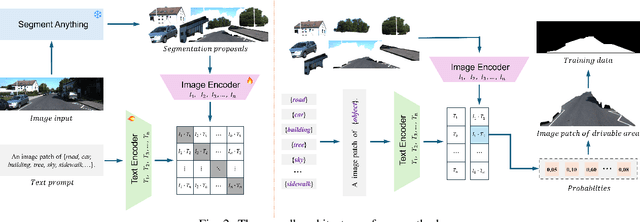


Pre-training techniques play a crucial role in deep learning, enhancing models' performance across a variety of tasks. By initially training on large datasets and subsequently fine-tuning on task-specific data, pre-training provides a solid foundation for models, improving generalization abilities and accelerating convergence rates. This approach has seen significant success in the fields of natural language processing and computer vision. However, traditional pre-training methods necessitate large datasets and substantial computational resources, and they can only learn shared features through prolonged training and struggle to capture deeper, task-specific features. In this paper, we propose a task-oriented pre-training method that begins with generating redundant segmentation proposals using the Segment Anything (SAM) model. We then introduce a Specific Category Enhancement Fine-tuning (SCEF) strategy for fine-tuning the Contrastive Language-Image Pre-training (CLIP) model to select proposals most closely related to the drivable area from those generated by SAM. This approach can generate a lot of coarse training data for pre-training models, which are further fine-tuned using manually annotated data, thereby improving model's performance. Comprehensive experiments conducted on the KITTI road dataset demonstrate that our task-oriented pre-training method achieves an all-around performance improvement compared to models without pre-training. Moreover, our pre-training method not only surpasses traditional pre-training approach but also achieves the best performance compared to state-of-the-art self-training methods.
Annotation-Free Curb Detection Leveraging Altitude Difference Image
Sep 30, 2024
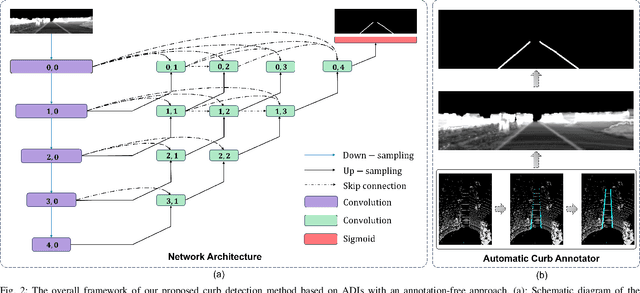

Road curbs are considered as one of the crucial and ubiquitous traffic features, which are essential for ensuring the safety of autonomous vehicles. Current methods for detecting curbs primarily rely on camera imagery or LiDAR point clouds. Image-based methods are vulnerable to fluctuations in lighting conditions and exhibit poor robustness, while methods based on point clouds circumvent the issues associated with lighting variations. However, it is the typical case that significant processing delays are encountered due to the voluminous amount of 3D points contained in each frame of the point cloud data. Furthermore, the inherently unstructured characteristics of point clouds poses challenges for integrating the latest deep learning advancements into point cloud data applications. To address these issues, this work proposes an annotation-free curb detection method leveraging Altitude Difference Image (ADI), which effectively mitigates the aforementioned challenges. Given that methods based on deep learning generally demand extensive, manually annotated datasets, which are both expensive and labor-intensive to create, we present an Automatic Curb Annotator (ACA) module. This module utilizes a deterministic curb detection algorithm to automatically generate a vast quantity of training data. Consequently, it facilitates the training of the curb detection model without necessitating any manual annotation of data. Finally, by incorporating a post-processing module, we manage to achieve state-of-the-art results on the KITTI 3D curb dataset with considerably reduced processing delays compared to existing methods, which underscores the effectiveness of our approach in curb detection tasks.
Erase, then Redraw: A Novel Data Augmentation Approach for Free Space Detection Using Diffusion Model
Sep 30, 2024
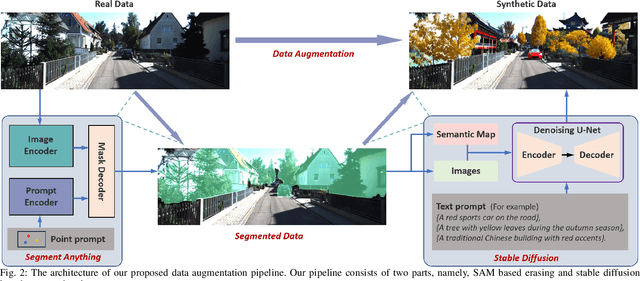
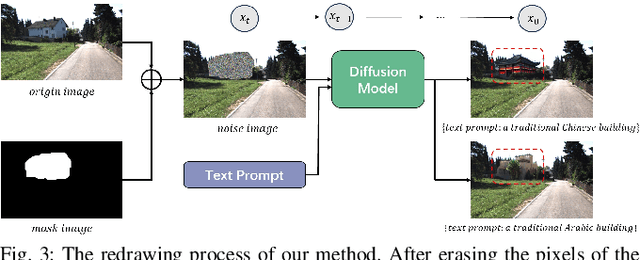

Data augmentation is one of the most common tools in deep learning, underpinning many recent advances including tasks such as classification, detection, and semantic segmentation. The standard approach to data augmentation involves simple transformations like rotation and flipping to generate new images. However, these new images often lack diversity along the main semantic dimensions within the data. Traditional data augmentation methods cannot alter high-level semantic attributes such as the presence of vehicles, trees, and buildings in a scene to enhance data diversity. In recent years, the rapid development of generative models has injected new vitality into the field of data augmentation. In this paper, we address the lack of diversity in data augmentation for road detection task by using a pre-trained text-to-image diffusion model to parameterize image-to-image transformations. Our method involves editing images using these diffusion models to change their semantics. In essence, we achieve this goal by erasing instances of real objects from the original dataset and generating new instances with similar semantics in the erased regions using the diffusion model, thereby expanding the original dataset. We evaluate our approach on the KITTI road dataset and achieve the best results compared to other data augmentation methods, which demonstrates the effectiveness of our proposed development.