 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOutcome Accuracy is Not Enough: Aligning the Reasoning Process of Reward Models
Feb 04, 2026Generative Reward Models (GenRMs) and LLM-as-a-Judge exhibit deceptive alignment by producing correct judgments for incorrect reasons, as they are trained and evaluated to prioritize Outcome Accuracy, which undermines their ability to generalize during RLHF. We introduce Rationale Consistency, a fine-grained metric that quantifies the alignment between the model's reasoning process and human judgment. Our evaluation of frontier models reveals that rationale consistency effectively discriminates among state-of-the-art models and detects deceptive alignment, while outcome accuracy falls short in both respects. To mitigate this gap, we introduce a hybrid signal that combines rationale consistency with outcome accuracy for GenRM training. Our training method achieves state-of-the-art performance on RM-Bench (87.1%) and JudgeBench (82%), surpassing outcome-only baselines by an average of 5%. Using RM during RLHF, our method effectively improves performance as demonstrated on Arena Hard v2, notably yielding a 7% improvement in creative writing tasks. Further analysis confirms that our method escapes the deceptive alignment trap, effectively reversing the decline in rationale consistency observed in outcome-only training.
CSR-Bench: A Benchmark for Evaluating the Cross-modal Safety and Reliability of MLLMs
Feb 03, 2026Multimodal large language models (MLLMs) enable interaction over both text and images, but their safety behavior can be driven by unimodal shortcuts instead of true joint intent understanding. We introduce CSR-Bench, a benchmark for evaluating cross-modal reliability through four stress-testing interaction patterns spanning Safety, Over-rejection, Bias, and Hallucination, covering 61 fine-grained types. Each instance is constructed to require integrated image-text interpretation, and we additionally provide paired text-only controls to diagnose modality-induced behavior shifts. We evaluate 16 state-of-the-art MLLMs and observe systematic cross-modal alignment gaps. Models show weak safety awareness, strong language dominance under interference, and consistent performance degradation from text-only controls to multimodal inputs. We also observe a clear trade-off between reducing over-rejection and maintaining safe, non-discriminatory behavior, suggesting that some apparent safety gains may come from refusal-oriented heuristics rather than robust intent understanding. WARNING: This paper contains unsafe contents.
Scalable Spatio-Temporal SE(3) Diffusion for Long-Horizon Protein Dynamics
Feb 02, 2026Molecular dynamics (MD) simulations remain the gold standard for studying protein dynamics, but their computational cost limits access to biologically relevant timescales. Recent generative models have shown promise in accelerating simulations, yet they struggle with long-horizon generation due to architectural constraints, error accumulation, and inadequate modeling of spatio-temporal dynamics. We present STAR-MD (Spatio-Temporal Autoregressive Rollout for Molecular Dynamics), a scalable SE(3)-equivariant diffusion model that generates physically plausible protein trajectories over microsecond timescales. Our key innovation is a causal diffusion transformer with joint spatio-temporal attention that efficiently captures complex space-time dependencies while avoiding the memory bottlenecks of existing methods. On the standard ATLAS benchmark, STAR-MD achieves state-of-the-art performance across all metrics--substantially improving conformational coverage, structural validity, and dynamic fidelity compared to previous methods. STAR-MD successfully extrapolates to generate stable microsecond-scale trajectories where baseline methods fail catastrophically, maintaining high structural quality throughout the extended rollout. Our comprehensive evaluation reveals severe limitations in current models for long-horizon generation, while demonstrating that STAR-MD's joint spatio-temporal modeling enables robust dynamics simulation at biologically relevant timescales, paving the way for accelerated exploration of protein function.
AgentIF-OneDay: A Task-level Instruction-Following Benchmark for General AI Agents in Daily Scenarios
Jan 28, 2026The capacity of AI agents to effectively handle tasks of increasing duration and complexity continues to grow, demonstrating exceptional performance in coding, deep research, and complex problem-solving evaluations. However, in daily scenarios, the perception of these advanced AI capabilities among general users remains limited. We argue that current evaluations prioritize increasing task difficulty without sufficiently addressing the diversity of agentic tasks necessary to cover the daily work, life, and learning activities of a broad demographic. To address this, we propose AgentIF-OneDay, aimed at determining whether general users can utilize natural language instructions and AI agents to complete a diverse array of daily tasks. These tasks require not only solving problems through dialogue but also understanding various attachment types and delivering tangible file-based results. The benchmark is structured around three user-centric categories: Open Workflow Execution, which assesses adherence to explicit and complex workflows; Latent Instruction, which requires agents to infer implicit instructions from attachments; and Iterative Refinement, which involves modifying or expanding upon ongoing work. We employ instance-level rubrics and a refined evaluation pipeline that aligns LLM-based verification with human judgment, achieving an 80.1% agreement rate using Gemini-3-Pro. AgentIF-OneDay comprises 104 tasks covering 767 scoring points. We benchmarked four leading general AI agents and found that agent products built based on APIs and ChatGPT agents based on agent RL remain in the first tier simultaneously. Leading LLM APIs and open-source models have internalized agentic capabilities, enabling AI application teams to develop cutting-edge Agent products.
SITP: A High-Reliability Semantic Information Transport Protocol Without Retransmission for Semantic Communication
Dec 10, 2025With the evolution of 6G networks, modern communication systems are facing unprecedented demands for high reliability and low latency. However, conventional transport protocols are designed for bit-level reliability, failing to meet the semantic robustness requirements. To address this limitation, this paper proposes a novel Semantic Information Transport Protocol (SITP), which achieves TCP-level reliability and UDP level latency by verifying only packet headers while retaining potentially corrupted payloads for semantic decoding. Building upon SITP, a cross-layer analytical model is established to quantify packet-loss probability across the physical, data-link, network, transport, and application layers. The model provides a unified probabilistic formulation linking signal noise rate (SNR) and packet-loss rate, offering theoretical foundation into end-to-end semantic transmission. Furthermore, a cross-image feature interleaving mechanism is developed to mitigate consecutive burst losses by redistributing semantic features across multiple correlated images, thereby enhancing robustness in burst-fade channels. Extensive experiments show that SITP offers lower latency than TCP with comparable reliability at low SNRs, while matching UDP-level latency and delivering superior reconstruction quality. In addition, the proposed cross-image semantic interleaving mechanism further demonstrates its effectiveness in mitigating degradation caused by bursty packet losses.
STEP: Success-Rate-Aware Trajectory-Efficient Policy Optimization
Nov 17, 2025Multi-turn interaction remains challenging for online reinforcement learning. A common solution is trajectory-level optimization, which treats each trajectory as a single training sample. However, this approach can be inefficient and yield misleading learning signals: it applies uniform sampling across tasks regardless of difficulty, penalizes correct intermediate actions in failed trajectories, and incurs high sample-collection costs. To address these issues, we propose STEP (Success-rate-aware Trajectory-Efficient Policy optimization), a framework that dynamically allocates sampling based on per-task success rates and performs step-level optimization. STEP maintains a smoothed success-rate record to guide adaptive trajectory resampling, allocating more effort to harder tasks. It then computes success-rate-weighted advantages and decomposes trajectories into step-level samples. Finally, it applies a step-level GRPO augmentation to refine updates for low-success tasks. Experiments on OSWorld and AndroidWorld show that STEP substantially improves sample efficiency and training stability over trajectory-level GRPO, converging faster and generalizing better under the same sampling budget.
Estranged Predictions: Measuring Semantic Category Disruption with Masked Language Modelling
Nov 11, 2025This paper examines how science fiction destabilises ontological categories by measuring conceptual permeability across the terms human, animal, and machine using masked language modelling (MLM). Drawing on corpora of science fiction (Gollancz SF Masterworks) and general fiction (NovelTM), we operationalise Darko Suvin's theory of estrangement as computationally measurable deviation in token prediction, using RoBERTa to generate lexical substitutes for masked referents and classifying them via Gemini. We quantify conceptual slippage through three metrics: retention rate, replacement rate, and entropy, mapping the stability or disruption of category boundaries across genres. Our findings reveal that science fiction exhibits heightened conceptual permeability, particularly around machine referents, which show significant cross-category substitution and dispersion. Human terms, by contrast, maintain semantic coherence and often anchor substitutional hierarchies. These patterns suggest a genre-specific restructuring within anthropocentric logics. We argue that estrangement in science fiction operates as a controlled perturbation of semantic norms, detectable through probabilistic modelling, and that MLMs, when used critically, serve as interpretive instruments capable of surfacing genre-conditioned ontological assumptions. This study contributes to the methodological repertoire of computational literary studies and offers new insights into the linguistic infrastructure of science fiction.
Training a Perceptual Model for Evaluating Auditory Similarity in Music Adversarial Attack
Sep 05, 2025
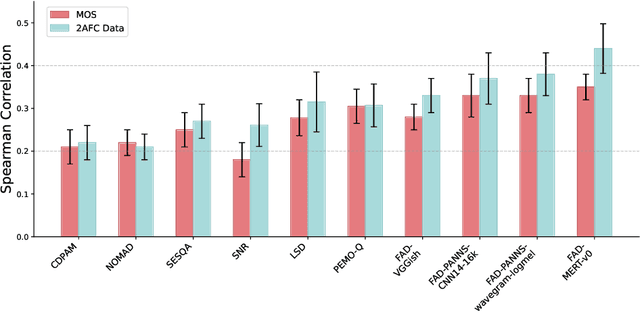
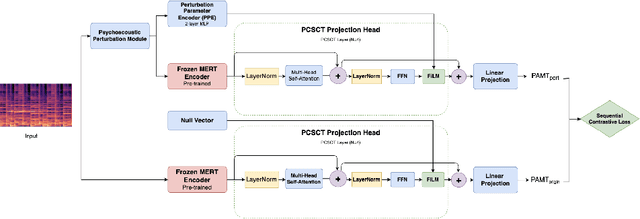
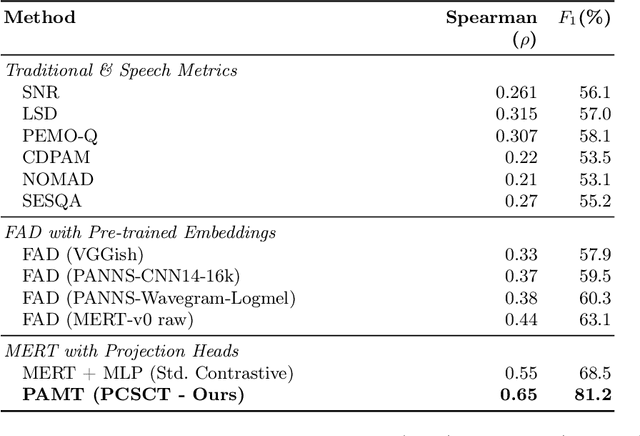
Music Information Retrieval (MIR) systems are highly vulnerable to adversarial attacks that are often imperceptible to humans, primarily due to a misalignment between model feature spaces and human auditory perception. Existing defenses and perceptual metrics frequently fail to adequately capture these auditory nuances, a limitation supported by our initial listening tests showing low correlation between common metrics and human judgments. To bridge this gap, we introduce Perceptually-Aligned MERT Transformer (PAMT), a novel framework for learning robust, perceptually-aligned music representations. Our core innovation lies in the psychoacoustically-conditioned sequential contrastive transformer, a lightweight projection head built atop a frozen MERT encoder. PAMT achieves a Spearman correlation coefficient of 0.65 with subjective scores, outperforming existing perceptual metrics. Our approach also achieves an average of 9.15\% improvement in robust accuracy on challenging MIR tasks, including Cover Song Identification and Music Genre Classification, under diverse perceptual adversarial attacks. This work pioneers architecturally-integrated psychoacoustic conditioning, yielding representations significantly more aligned with human perception and robust against music adversarial attacks.
MAIA: An Inpainting-Based Approach for Music Adversarial Attacks
Sep 05, 2025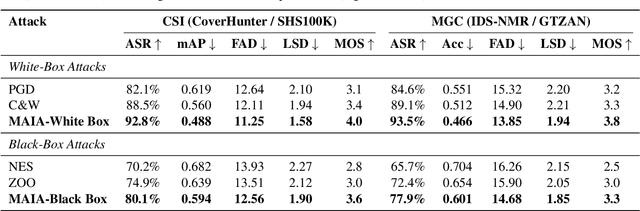
Music adversarial attacks have garnered significant interest in the field of Music Information Retrieval (MIR). In this paper, we present Music Adversarial Inpainting Attack (MAIA), a novel adversarial attack framework that supports both white-box and black-box attack scenarios. MAIA begins with an importance analysis to identify critical audio segments, which are then targeted for modification. Utilizing generative inpainting models, these segments are reconstructed with guidance from the output of the attacked model, ensuring subtle and effective adversarial perturbations. We evaluate MAIA on multiple MIR tasks, demonstrating high attack success rates in both white-box and black-box settings while maintaining minimal perceptual distortion. Additionally, subjective listening tests confirm the high audio fidelity of the adversarial samples. Our findings highlight vulnerabilities in current MIR systems and emphasize the need for more robust and secure models.
A Multidimensional AI-powered Framework for Analyzing Tourist Perception in Historic Urban Quarters: A Case Study in Shanghai
Sep 04, 2025



Historic urban quarters play a vital role in preserving cultural heritage while serving as vibrant spaces for tourism and everyday life. Understanding how tourists perceive these environments is essential for sustainable, human-centered urban planning. This study proposes a multidimensional AI-powered framework for analyzing tourist perception in historic urban quarters using multimodal data from social media. Applied to twelve historic quarters in central Shanghai, the framework integrates focal point extraction, color theme analysis, and sentiment mining. Visual focus areas are identified from tourist-shared photos using a fine-tuned semantic segmentation model. To assess aesthetic preferences, dominant colors are extracted using a clustering method, and their spatial distribution across quarters is analyzed. Color themes are further compared between social media photos and real-world street views, revealing notable shifts. This divergence highlights potential gaps between visual expectations and the built environment, reflecting both stylistic preferences and perceptual bias. Tourist reviews are evaluated through a hybrid sentiment analysis approach combining a rule-based method and a multi-task BERT model. Satisfaction is assessed across four dimensions: tourist activities, built environment, service facilities, and business formats. The results reveal spatial variations in aesthetic appeal and emotional response. Rather than focusing on a single technical innovation, this framework offers an integrated, data-driven approach to decoding tourist perception and contributes to informed decision-making in tourism, heritage conservation, and the design of aesthetically engaging public spaces.