 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirectAudioEdit: Inversion-Free Text-Guided Audio Editing via Diffusion Prediction Contrast
Jun 05, 2026Text-guided audio editing aims to modify the language-specified acoustic content while preserving edit-irrelevant source components. Existing training-free methods typically rely on inversion-based editing. While inversion-free editing is appealing as it decreases computational overhead and reconstruction errors, it remains largely unexplored for audio editing. The key challenge is to construct a source-to-target editing path through diffusion denoising dynamics. In this paper, we introduce DirectAudioEdit, the first attempt to develop a training-free and inversion-free method for audio editing. Experiments on music and event-level benchmarks across two backbones show that DirectAudioEdit reduces macro-averaged FAD and KL by 15.9% and 15.8% compared with DDPM inversion, while achieving up to 64.5% editing speedup.
EfficientGraph-RAG: Structured Retrieval-State Management for Cross-Task Retrieval-Augmented Generation
May 25, 2026Retrieval-augmented generation (RAG) has become the standard way to ground large language models in external knowledge, but many systems still organize evidence as flat chunks and retrieve it through largely unstructured search. This weak structure becomes a bottleneck for complex retrieval: the system must decide where to search, how to move from coarse topics to entity-relation evidence, which evidence has been verified, and which intermediate artifacts can be reused. We define these intermediate variables as a retrieval state and study RAG as structured state management. EfficientGraph-RAG makes this state explicit through three coupled mechanisms: TAM defines a typed hierarchical state space over evidence, MARS updates and verifies the state through role-specialized agents, and SMP stores reusable state under hierarchy-aware access control. Using one shared framework configuration, EfficientGraph-RAG ranks first on the reported answer-quality metrics averaged over the three evaluated LongBench retrieval-style subsets, matches the strongest agentic baseline on HotpotQA EM while reducing large-model token usage by $3.51\times$, and provides a low-token DocVQA result among retrieval-organizing cross-modal methods. Component analysis shows role-specific mechanisms: MARS is the main answer-quality driver, TAM supplies the typed traversal state and Adaptive Routing signal, and SMP enables corpus-dependent reuse, with cross-query cache hit rates ranging from 3.77% to 23.18%.
On the Emotion Understanding of Synthesized Speech
Mar 17, 2026Emotion is a core paralinguistic feature in voice interaction. It is widely believed that emotion understanding models learn fundamental representations that transfer to synthesized speech, making emotion understanding results a plausible reward or evaluation metric for assessing emotional expressiveness in speech synthesis. In this work, we critically examine this assumption by systematically evaluating Speech Emotion Recognition (SER) on synthesized speech across datasets, discriminative and generative SER models, and diverse synthesis models. We find that current SER models can not generalize to synthesized speech, largely because speech token prediction during synthesis induces a representation mismatch between synthesized and human speech. Moreover, generative Speech Language Models (SLMs) tend to infer emotion from textual semantics while ignoring paralinguistic cues. Overall, our findings suggest that existing SER models often exploit non-robust shortcuts rather than capturing fundamental features, and paralinguistic understanding in SLMs remains challenging.
Consensus-Aligned Neuron Efficient Fine-Tuning Large Language Models for Multi-Domain Machine Translation
Feb 05, 2026Multi-domain machine translation (MDMT) aims to build a unified model capable of translating content across diverse domains. Despite the impressive machine translation capabilities demonstrated by large language models (LLMs), domain adaptation still remains a challenge for LLMs. Existing MDMT methods such as in-context learning and parameter-efficient fine-tuning often suffer from domain shift, parameter interference and limited generalization. In this work, we propose a neuron-efficient fine-tuning framework for MDMT that identifies and updates consensus-aligned neurons within LLMs. These neurons are selected by maximizing the mutual information between neuron behavior and domain features, enabling LLMs to capture both generalizable translation patterns and domain-specific nuances. Our method then fine-tunes LLMs guided by these neurons, effectively mitigating parameter interference and domain-specific overfitting. Comprehensive experiments on three LLMs across ten German-English and Chinese-English translation domains evidence that our method consistently outperforms strong PEFT baselines on both seen and unseen domains, achieving state-of-the-art performance.
APR: Penalizing Structural Redundancy in Large Reasoning Models via Anchor-based Process Rewards
Jan 31, 2026Test-Time Scaling (TTS) has significantly enhanced the capabilities of Large Reasoning Models (LRMs) but introduces a critical side-effect known as Overthinking. We conduct a preliminary study to rethink this phenomenon from a fine-grained perspective. We observe that LRMs frequently conduct repetitive self-verification without revision even after obtaining the final answer during the reasoning process. We formally define this specific position where the answer first stabilizes as the Reasoning Anchor. By analyzing pre- and post-anchor reasoning behaviors, we uncover the structural redundancy fixed in LRMs: the meaningless repetitive verification after deriving the first complete answer, which we term the Answer-Stable Tail (AST). Motivated by this observation, we propose Anchor-based Process Reward (APR), a structure-aware reward shaping method that localizes the reasoning anchor and penalizes exclusively the post-anchor AST. Leveraging the policy optimization algorithm suitable for length penalties, our APR models achieved the performance-efficiency Pareto frontier at 1.5B and 7B scales averaged across five mathematical reasoning datasets while requiring significantly fewer computational resources for RL training.
Hyperspherical Graph Representation Learning via Adaptive Neighbor-Mean Alignment and Uniformity
Dec 30, 2025Graph representation learning (GRL) aims to encode structural and semantic dependencies of graph-structured data into low-dimensional embeddings. However, existing GRL methods often rely on surrogate contrastive objectives or mutual information maximization, which typically demand complex architectures, negative sampling strategies, and sensitive hyperparameter tuning. These design choices may induce over-smoothing, over-squashing, and training instability. In this work, we propose HyperGRL, a unified framework for hyperspherical graph representation learning via adaptive neighbor-mean alignment and sampling-free uniformity. HyperGRL embeds nodes on a unit hypersphere through two adversarially coupled objectives: neighbor-mean alignment and sampling-free uniformity. The alignment objective uses the mean representation of each node's local neighborhood to construct semantically grounded, stable targets that capture shared structural and feature patterns. The uniformity objective formulates dispersion via an L2-based hyperspherical regularization, encouraging globally uniform embedding distributions while preserving discriminative information. To further stabilize training, we introduce an entropy-guided adaptive balancing mechanism that dynamically regulates the interplay between alignment and uniformity without requiring manual tuning. Extensive experiments on node classification, node clustering, and link prediction demonstrate that HyperGRL delivers superior representation quality and generalization across diverse graph structures, achieving average improvements of 1.49%, 0.86%, and 0.74% over the strongest existing methods, respectively. These findings highlight the effectiveness of geometrically grounded, sampling-free contrastive objectives for graph representation learning.
Probing Preference Representations: A Multi-Dimensional Evaluation and Analysis Method for Reward Models
Nov 16, 2025Previous methods evaluate reward models by testing them on a fixed pairwise ranking test set, but they typically do not provide performance information on each preference dimension. In this work, we address the evaluation challenge of reward models by probing preference representations. To confirm the effectiveness of this evaluation method, we construct a Multi-dimensional Reward Model Benchmark (MRMBench), a collection of six probing tasks for different preference dimensions. We design it to favor and encourage reward models that better capture preferences across different dimensions. Furthermore, we introduce an analysis method, inference-time probing, which identifies the dimensions used during the reward prediction and enhances its interpretability. Through extensive experiments, we find that MRMBench strongly correlates with the alignment performance of large language models (LLMs), making it a reliable reference for developing advanced reward models. Our analysis of MRMBench evaluation results reveals that reward models often struggle to capture preferences across multiple dimensions, highlighting the potential of multi-objective optimization in reward modeling. Additionally, our findings show that the proposed inference-time probing method offers a reliable metric for assessing the confidence of reward predictions, which ultimately improves the alignment of LLMs.
MRO: Enhancing Reasoning in Diffusion Language Models via Multi-Reward Optimization
Oct 24, 2025


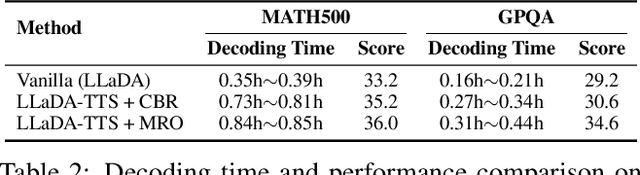
Recent advances in diffusion language models (DLMs) have presented a promising alternative to traditional autoregressive large language models (LLMs). However, DLMs still lag behind LLMs in reasoning performance, especially as the number of denoising steps decreases. Our analysis reveals that this shortcoming arises primarily from the independent generation of masked tokens across denoising steps, which fails to capture the token correlation. In this paper, we define two types of token correlation: intra-sequence correlation and inter-sequence correlation, and demonstrate that enhancing these correlations improves reasoning performance. To this end, we propose a Multi-Reward Optimization (MRO) approach, which encourages DLMs to consider the token correlation during the denoising process. More specifically, our MRO approach leverages test-time scaling, reject sampling, and reinforcement learning to directly optimize the token correlation with multiple elaborate rewards. Additionally, we introduce group step and importance sampling strategies to mitigate reward variance and enhance sampling efficiency. Through extensive experiments, we demonstrate that MRO not only improves reasoning performance but also achieves significant sampling speedups while maintaining high performance on reasoning benchmarks.
Multilingual Generative Retrieval via Cross-lingual Semantic Compression
Oct 09, 2025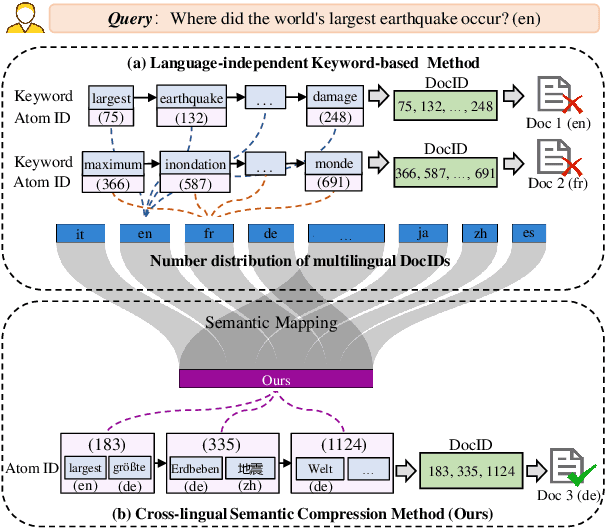
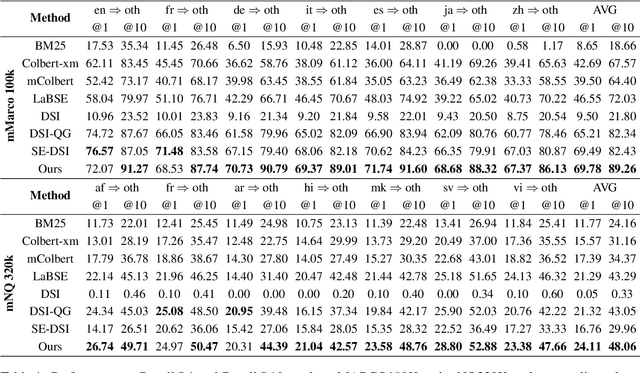
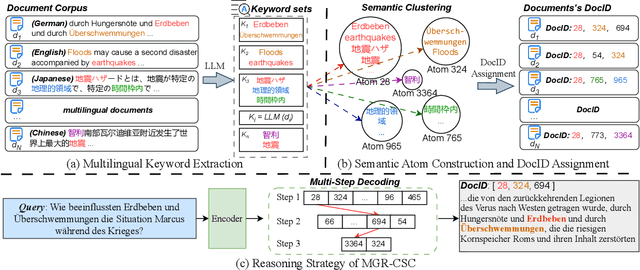

Generative Information Retrieval is an emerging retrieval paradigm that exhibits remarkable performance in monolingual scenarios.However, applying these methods to multilingual retrieval still encounters two primary challenges, cross-lingual identifier misalignment and identifier inflation. To address these limitations, we propose Multilingual Generative Retrieval via Cross-lingual Semantic Compression (MGR-CSC), a novel framework that unifies semantically equivalent multilingual keywords into shared atoms to align semantics and compresses the identifier space, and we propose a dynamic multi-step constrained decoding strategy during retrieval. MGR-CSC improves cross-lingual alignment by assigning consistent identifiers and enhances decoding efficiency by reducing redundancy. Experiments demonstrate that MGR-CSC achieves outstanding retrieval accuracy, improving by 6.83% on mMarco100k and 4.77% on mNQ320k, while reducing document identifiers length by 74.51% and 78.2%, respectively.
FLEXI: Benchmarking Full-duplex Human-LLM Speech Interaction
Sep 26, 2025Full-Duplex Speech-to-Speech Large Language Models (LLMs) are foundational to natural human-computer interaction, enabling real-time spoken dialogue systems. However, benchmarking and modeling these models remains a fundamental challenge. We introduce FLEXI, the first benchmark for full-duplex LLM-human spoken interaction that explicitly incorporates model interruption in emergency scenarios. FLEXI systematically evaluates the latency, quality, and conversational effectiveness of real-time dialogue through six diverse human-LLM interaction scenarios, revealing significant gaps between open source and commercial models in emergency awareness, turn terminating, and interaction latency. Finally, we suggest that next token-pair prediction offers a promising path toward achieving truly seamless and human-like full-duplex interaction.