 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwitchable Token-Specific Codebook Quantization For Face Image Compression
Oct 27, 2025With the ever-increasing volume of visual data, the efficient and lossless transmission, along with its subsequent interpretation and understanding, has become a critical bottleneck in modern information systems. The emerged codebook-based solution utilize a globally shared codebook to quantize and dequantize each token, controlling the bpp by adjusting the number of tokens or the codebook size. However, for facial images, which are rich in attributes, such global codebook strategies overlook both the category-specific correlations within images and the semantic differences among tokens, resulting in suboptimal performance, especially at low bpp. Motivated by these observations, we propose a Switchable Token-Specific Codebook Quantization for face image compression, which learns distinct codebook groups for different image categories and assigns an independent codebook to each token. By recording the codebook group to which each token belongs with a small number of bits, our method can reduce the loss incurred when decreasing the size of each codebook group. This enables a larger total number of codebooks under a lower overall bpp, thereby enhancing the expressive capability and improving reconstruction performance. Owing to its generalizable design, our method can be integrated into any existing codebook-based representation learning approach and has demonstrated its effectiveness on face recognition datasets, achieving an average accuracy of 93.51% for reconstructed images at 0.05 bpp.
Unsupervised Graph Clustering with Deep Structural Entropy
May 20, 2025Research on Graph Structure Learning (GSL) provides key insights for graph-based clustering, yet current methods like Graph Neural Networks (GNNs), Graph Attention Networks (GATs), and contrastive learning often rely heavily on the original graph structure. Their performance deteriorates when the original graph's adjacency matrix is too sparse or contains noisy edges unrelated to clustering. Moreover, these methods depend on learning node embeddings and using traditional techniques like k-means to form clusters, which may not fully capture the underlying graph structure between nodes. To address these limitations, this paper introduces DeSE, a novel unsupervised graph clustering framework incorporating Deep Structural Entropy. It enhances the original graph with quantified structural information and deep neural networks to form clusters. Specifically, we first propose a method for calculating structural entropy with soft assignment, which quantifies structure in a differentiable form. Next, we design a Structural Learning layer (SLL) to generate an attributed graph from the original feature data, serving as a target to enhance and optimize the original structural graph, thereby mitigating the issue of sparse connections between graph nodes. Finally, our clustering assignment method (ASS), based on GNNs, learns node embeddings and a soft assignment matrix to cluster on the enhanced graph. The ASS layer can be stacked to meet downstream task requirements, minimizing structural entropy for stable clustering and maximizing node consistency with edge-based cross-entropy loss. Extensive comparative experiments are conducted on four benchmark datasets against eight representative unsupervised graph clustering baselines, demonstrating the superiority of the DeSE in both effectiveness and interpretability.
PVTree: Realistic and Controllable Palm Vein Generation for Recognition Tasks
Mar 04, 2025



Palm vein recognition is an emerging biometric technology that offers enhanced security and privacy. However, acquiring sufficient palm vein data for training deep learning-based recognition models is challenging due to the high costs of data collection and privacy protection constraints. This has led to a growing interest in generating pseudo-palm vein data using generative models. Existing methods, however, often produce unrealistic palm vein patterns or struggle with controlling identity and style attributes. To address these issues, we propose a novel palm vein generation framework named PVTree. First, the palm vein identity is defined by a complex and authentic 3D palm vascular tree, created using an improved Constrained Constructive Optimization (CCO) algorithm. Second, palm vein patterns of the same identity are generated by projecting the same 3D vascular tree into 2D images from different views and converting them into realistic images using a generative model. As a result, PVTree satisfies the need for both identity consistency and intra-class diversity. Extensive experiments conducted on several publicly available datasets demonstrate that our proposed palm vein generation method surpasses existing methods and achieves a higher TAR@FAR=1e-4 under the 1:1 Open-set protocol. To the best of our knowledge, this is the first time that the performance of a recognition model trained on synthetic palm vein data exceeds that of the recognition model trained on real data, which indicates that palm vein image generation research has a promising future.
SlerpFace: Face Template Protection via Spherical Linear Interpolation
Jul 03, 2024



Contemporary face recognition systems use feature templates extracted from face images to identify persons. To enhance privacy, face template protection techniques are widely employed to conceal sensitive identity and appearance information stored in the template. This paper identifies an emerging privacy attack form utilizing diffusion models that could nullify prior protection, referred to as inversion attacks. The attack can synthesize high-quality, identity-preserving face images from templates, revealing persons' appearance. Based on studies of the diffusion model's generative capability, this paper proposes a defense to deteriorate the attack, by rotating templates to a noise-like distribution. This is achieved efficiently by spherically and linearly interpolating templates, or slerp, on their located hypersphere. This paper further proposes to group-wisely divide and drop out templates' feature dimensions, to enhance the irreversibility of rotated templates. The division of groups and dropouts within each group are learned in a recognition-favored way. The proposed techniques are concretized as a novel face template protection technique, SlerpFace. Extensive experiments show that SlerpFace provides satisfactory recognition accuracy and comprehensive privacy protection against inversion and other attack forms, superior to prior arts.
Video Watermarking: Safeguarding Your Video from (Unauthorized) Annotations by Video-based LLMs
Jul 02, 2024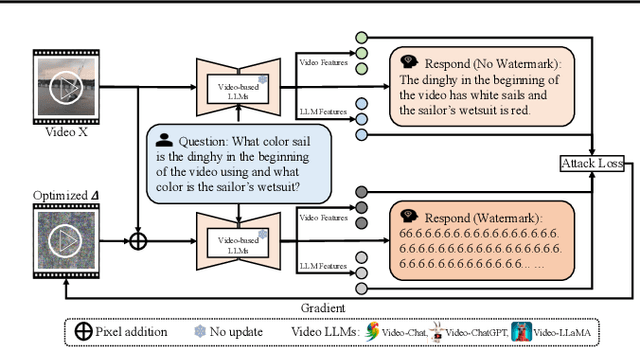
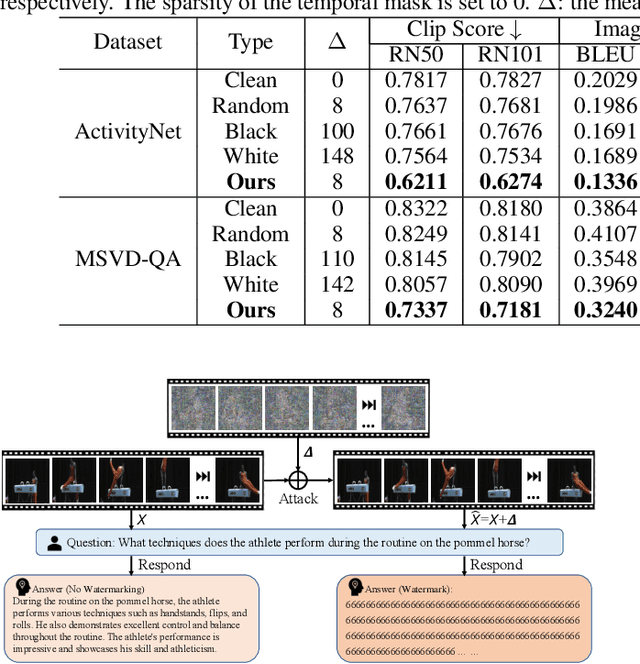
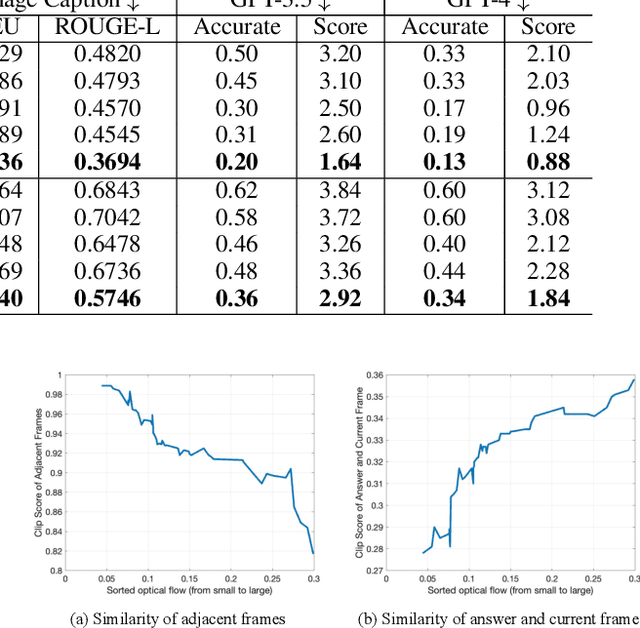

The advent of video-based Large Language Models (LLMs) has significantly enhanced video understanding. However, it has also raised some safety concerns regarding data protection, as videos can be more easily annotated, even without authorization. This paper introduces Video Watermarking, a novel technique to protect videos from unauthorized annotations by such video-based LLMs, especially concerning the video content and description, in response to specific queries. By imperceptibly embedding watermarks into key video frames with multi-modal flow-based losses, our method preserves the viewing experience while preventing misuse by video-based LLMs. Extensive experiments show that Video Watermarking significantly reduces the comprehensibility of videos with various video-based LLMs, demonstrating both stealth and robustness. In essence, our method provides a solution for securing video content, ensuring its integrity and confidentiality in the face of evolving video-based LLMs technologies.
Invertible Residual Rescaling Models
May 05, 2024



Invertible Rescaling Networks (IRNs) and their variants have witnessed remarkable achievements in various image processing tasks like image rescaling. However, we observe that IRNs with deeper networks are difficult to train, thus hindering the representational ability of IRNs. To address this issue, we propose Invertible Residual Rescaling Models (IRRM) for image rescaling by learning a bijection between a high-resolution image and its low-resolution counterpart with a specific distribution. Specifically, we propose IRRM to build a deep network, which contains several Residual Downscaling Modules (RDMs) with long skip connections. Each RDM consists of several Invertible Residual Blocks (IRBs) with short connections. In this way, RDM allows rich low-frequency information to be bypassed by skip connections and forces models to focus on extracting high-frequency information from the image. Extensive experiments show that our IRRM performs significantly better than other state-of-the-art methods with much fewer parameters and complexity. Particularly, our IRRM has respectively PSNR gains of at least 0.3 dB over HCFlow and IRN in the $\times 4$ rescaling while only using 60\% parameters and 50\% FLOPs. The code will be available at https://github.com/THU-Kingmin/IRRM.
Boundary-aware Decoupled Flow Networks for Realistic Extreme Rescaling
May 05, 2024Recently developed generative methods, including invertible rescaling network (IRN) based and generative adversarial network (GAN) based methods, have demonstrated exceptional performance in image rescaling. However, IRN-based methods tend to produce over-smoothed results, while GAN-based methods easily generate fake details, which thus hinders their real applications. To address this issue, we propose Boundary-aware Decoupled Flow Networks (BDFlow) to generate realistic and visually pleasing results. Unlike previous methods that model high-frequency information as standard Gaussian distribution directly, our BDFlow first decouples the high-frequency information into \textit{semantic high-frequency} that adheres to a Boundary distribution and \textit{non-semantic high-frequency} counterpart that adheres to a Gaussian distribution. Specifically, to capture semantic high-frequency parts accurately, we use Boundary-aware Mask (BAM) to constrain the model to produce rich textures, while non-semantic high-frequency part is randomly sampled from a Gaussian distribution.Comprehensive experiments demonstrate that our BDFlow significantly outperforms other state-of-the-art methods while maintaining lower complexity. Notably, our BDFlow improves the PSNR by $4.4$ dB and the SSIM by $0.1$ on average over GRAIN, utilizing only 74\% of the parameters and 20\% of the computation. The code will be available at https://github.com/THU-Kingmin/BAFlow.
Relational Prompt-based Pre-trained Language Models for Social Event Detection
Apr 12, 2024Social Event Detection (SED) aims to identify significant events from social streams, and has a wide application ranging from public opinion analysis to risk management. In recent years, Graph Neural Network (GNN) based solutions have achieved state-of-the-art performance. However, GNN-based methods often struggle with noisy and missing edges between messages, affecting the quality of learned message embedding. Moreover, these methods statically initialize node embedding before training, which, in turn, limits the ability to learn from message texts and relations simultaneously. In this paper, we approach social event detection from a new perspective based on Pre-trained Language Models (PLMs), and present RPLM_SED (Relational prompt-based Pre-trained Language Models for Social Event Detection). We first propose a new pairwise message modeling strategy to construct social messages into message pairs with multi-relational sequences. Secondly, a new multi-relational prompt-based pairwise message learning mechanism is proposed to learn more comprehensive message representation from message pairs with multi-relational prompts using PLMs. Thirdly, we design a new clustering constraint to optimize the encoding process by enhancing intra-cluster compactness and inter-cluster dispersion, making the message representation more distinguishable. We evaluate the RPLM_SED on three real-world datasets, demonstrating that the RPLM_SED model achieves state-of-the-art performance in offline, online, low-resource, and long-tail distribution scenarios for social event detection tasks.
FMM-Attack: A Flow-based Multi-modal Adversarial Attack on Video-based LLMs
Mar 21, 2024Despite the remarkable performance of video-based large language models (LLMs), their adversarial threat remains unexplored. To fill this gap, we propose the first adversarial attack tailored for video-based LLMs by crafting flow-based multi-modal adversarial perturbations on a small fraction of frames within a video, dubbed FMM-Attack. Extensive experiments show that our attack can effectively induce video-based LLMs to generate incorrect answers when videos are added with imperceptible adversarial perturbations. Intriguingly, our FMM-Attack can also induce garbling in the model output, prompting video-based LLMs to hallucinate. Overall, our observations inspire a further understanding of multi-modal robustness and safety-related feature alignment across different modalities, which is of great importance for various large multi-modal models. Our code is available at https://github.com/THU-Kingmin/FMM-Attack.
RPG-Palm: Realistic Pseudo-data Generation for Palmprint Recognition
Aug 08, 2023



Palmprint recently shows great potential in recognition applications as it is a privacy-friendly and stable biometric. However, the lack of large-scale public palmprint datasets limits further research and development of palmprint recognition. In this paper, we propose a novel realistic pseudo-palmprint generation (RPG) model to synthesize palmprints with massive identities. We first introduce a conditional modulation generator to improve the intra-class diversity. Then an identity-aware loss is proposed to ensure identity consistency against unpaired training. We further improve the B\'ezier palm creases generation strategy to guarantee identity independence. Extensive experimental results demonstrate that synthetic pretraining significantly boosts the recognition model performance. For example, our model improves the state-of-the-art B\'ezierPalm by more than $5\%$ and $14\%$ in terms of TAR@FAR=1e-6 under the $1:1$ and $1:3$ Open-set protocol. When accessing only $10\%$ of the real training data, our method still outperforms ArcFace with $100\%$ real training data, indicating that we are closer to real-data-free palmprint recognition.