 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePVTree: Realistic and Controllable Palm Vein Generation for Recognition Tasks
Mar 04, 2025Palm vein recognition is an emerging biometric technology that offers enhanced security and privacy. However, acquiring sufficient palm vein data for training deep learning-based recognition models is challenging due to the high costs of data collection and privacy protection constraints. This has led to a growing interest in generating pseudo-palm vein data using generative models. Existing methods, however, often produce unrealistic palm vein patterns or struggle with controlling identity and style attributes. To address these issues, we propose a novel palm vein generation framework named PVTree. First, the palm vein identity is defined by a complex and authentic 3D palm vascular tree, created using an improved Constrained Constructive Optimization (CCO) algorithm. Second, palm vein patterns of the same identity are generated by projecting the same 3D vascular tree into 2D images from different views and converting them into realistic images using a generative model. As a result, PVTree satisfies the need for both identity consistency and intra-class diversity. Extensive experiments conducted on several publicly available datasets demonstrate that our proposed palm vein generation method surpasses existing methods and achieves a higher TAR@FAR=1e-4 under the 1:1 Open-set protocol. To the best of our knowledge, this is the first time that the performance of a recognition model trained on synthetic palm vein data exceeds that of the recognition model trained on real data, which indicates that palm vein image generation research has a promising future.
Energy Attack: On Transferring Adversarial Examples
Sep 09, 2021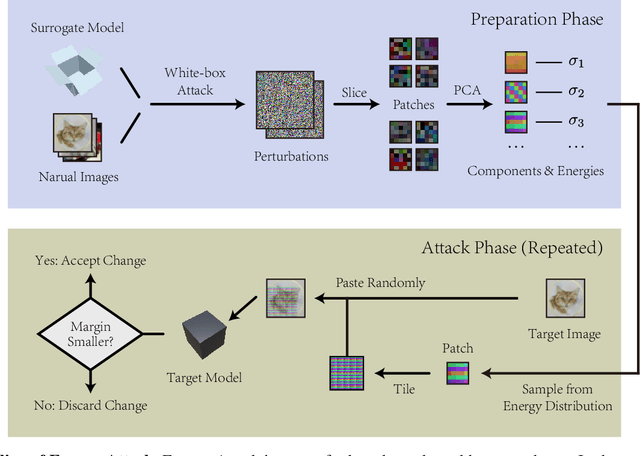

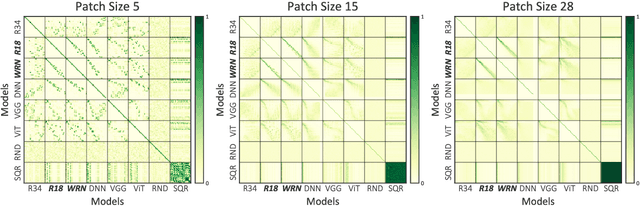
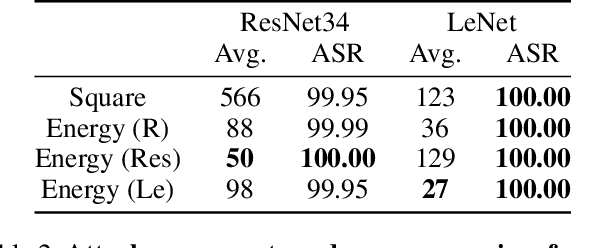
In this work we propose Energy Attack, a transfer-based black-box $L_\infty$-adversarial attack. The attack is parameter-free and does not require gradient approximation. In particular, we first obtain white-box adversarial perturbations of a surrogate model and divide these perturbations into small patches. Then we extract the unit component vectors and eigenvalues of these patches with principal component analysis (PCA). Base on the eigenvalues, we can model the energy distribution of adversarial perturbations. We then perform black-box attacks by sampling from the perturbation patches according to their energy distribution, and tiling the sampled patches to form a full-size adversarial perturbation. This can be done without the available access to victim models. Extensive experiments well demonstrate that the proposed Energy Attack achieves state-of-the-art performance in black-box attacks on various models and several datasets. Moreover, the extracted distribution is able to transfer among different model architectures and different datasets, and is therefore intrinsic to vision architectures.
Learning Black-Box Attackers with Transferable Priors and Query Feedback
Oct 21, 2020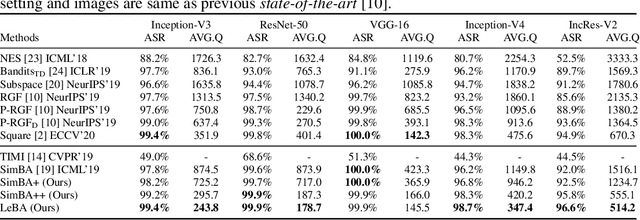

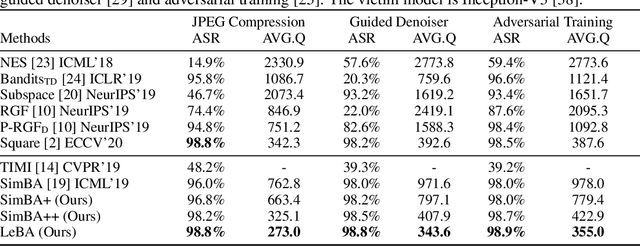

This paper addresses the challenging black-box adversarial attack problem, where only classification confidence of a victim model is available. Inspired by consistency of visual saliency between different vision models, a surrogate model is expected to improve the attack performance via transferability. By combining transferability-based and query-based black-box attack, we propose a surprisingly simple baseline approach (named SimBA++) using the surrogate model, which significantly outperforms several state-of-the-art methods. Moreover, to efficiently utilize the query feedback, we update the surrogate model in a novel learning scheme, named High-Order Gradient Approximation (HOGA). By constructing a high-order gradient computation graph, we update the surrogate model to approximate the victim model in both forward and backward pass. The SimBA++ and HOGA result in Learnable Black-Box Attack (LeBA), which surpasses previous state of the art by considerable margins: the proposed LeBA significantly reduces queries, while keeping higher attack success rates close to 100% in extensive ImageNet experiments, including attacking vision benchmarks and defensive models. Code is open source at https://github.com/TrustworthyDL/LeBA.
Exploiting Channel Similarity for Accelerating Deep Convolutional Neural Networks
Aug 06, 2019



To address the limitations of existing magnitude-based pruning algorithms in cases where model weights or activations are of large and similar magnitude, we propose a novel perspective to discover parameter redundancy among channels and accelerate deep CNNs via channel pruning. Precisely, we argue that channels revealing similar feature information have functional overlap and that most channels within each such similarity group can be removed without compromising model's representational power. After deriving an effective metric for evaluating channel similarity through probabilistic modeling, we introduce a pruning algorithm via hierarchical clustering of channels. In particular, the proposed algorithm does not rely on sparsity training techniques or complex data-driven optimization and can be directly applied to pre-trained models. Extensive experiments on benchmark datasets strongly demonstrate the superior acceleration performance of our approach over prior arts. On ImageNet, our pruned ResNet-50 with 30% FLOPs reduced outperforms the baseline model.