 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoulX-LiveAct: Towards Hour-Scale Real-Time Human Animation with Neighbor Forcing and ConvKV Memory
Mar 12, 2026Autoregressive (AR) diffusion models offer a promising framework for sequential generation tasks such as video synthesis by combining diffusion modeling with causal inference. Although they support streaming generation, existing AR diffusion methods struggle to scale efficiently. In this paper, we identify two key challenges in hour-scale real-time human animation. First, most forcing strategies propagate sample-level representations with mismatched diffusion states, causing inconsistent learning signals and unstable convergence. Second, historical representations grow unbounded and lack structure, preventing effective reuse of cached states and severely limiting inference efficiency. To address these challenges, we propose Neighbor Forcing, a diffusion-step-consistent AR formulation that propagates temporally adjacent frames as latent neighbors under the same noise condition. This design provides a distribution-aligned and stable learning signal while preserving drifting throughout the AR chain. Building upon this, we introduce a structured ConvKV memory mechanism that compresses the keys and values in causal attention into a fixed-length representation, enabling constant-memory inference and truly infinite video generation without relying on short-term motion-frame memory. Extensive experiments demonstrate that our approach significantly improves training convergence, hour-scale generation quality, and inference efficiency compared to existing AR diffusion methods. Numerically, LiveAct enables hour-scale real-time human animation and supports 20 FPS real-time streaming inference on as few as two NVIDIA H100 or H200 GPUs. Quantitative results demonstrate that our method attains state-of-the-art performance in lip-sync accuracy, human animation quality, and emotional expressiveness, with the lowest inference cost.
It's LIT! Reliability-Optimized LLMs with Inspectable Tools
Nov 18, 2025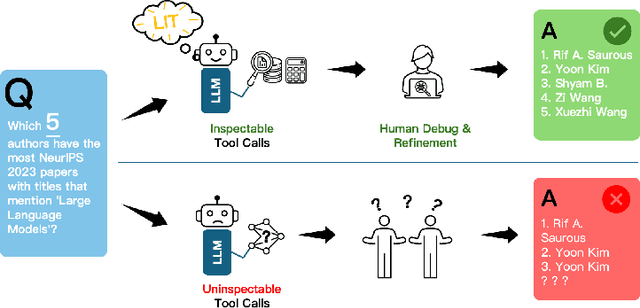
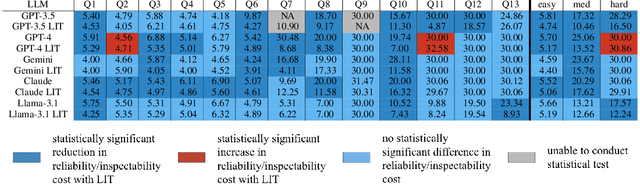
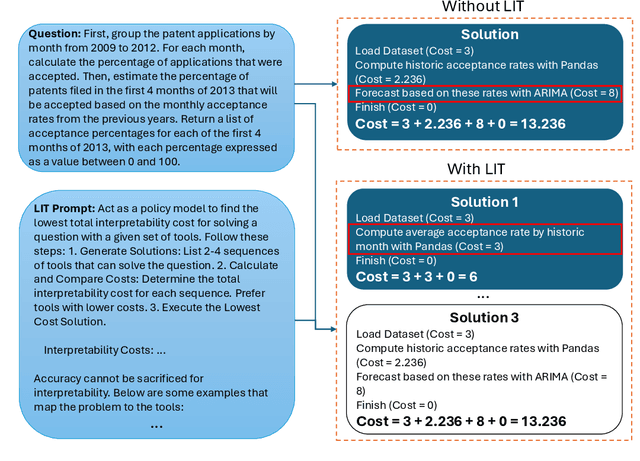
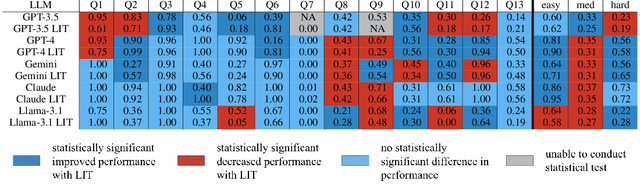
Large language models (LLMs) have exhibited remarkable capabilities across various domains. The ability to call external tools further expands their capability to handle real-world tasks. However, LLMs often follow an opaque reasoning process, which limits their usefulness in high-stakes domains where solutions need to be trustworthy to end users. LLMs can choose solutions that are unreliable and difficult to troubleshoot, even if better options are available. We address this issue by forcing LLMs to use external -- more reliable -- tools to solve problems when possible. We present a framework built on the tool-calling capabilities of existing LLMs to enable them to select the most reliable and easy-to-troubleshoot solution path, which may involve multiple sequential tool calls. We refer to this framework as LIT (LLMs with Inspectable Tools). In order to support LIT, we introduce a new and challenging benchmark dataset of 1,300 questions and a customizable set of reliability cost functions associated with a collection of specialized tools. These cost functions summarize how reliable each tool is and how easy it is to troubleshoot. For instance, a calculator is reliable across domains, whereas a linear prediction model is not reliable if there is distribution shift, but it is easy to troubleshoot. A tool that constructs a random forest is neither reliable nor easy to troubleshoot. These tools interact with the Harvard USPTO Patent Dataset and a new dataset of NeurIPS 2023 papers to solve mathematical, coding, and modeling problems of varying difficulty levels. We demonstrate that LLMs can achieve more reliable and informed problem-solving while maintaining task performance using our framework.
Switchable Token-Specific Codebook Quantization For Face Image Compression
Oct 27, 2025With the ever-increasing volume of visual data, the efficient and lossless transmission, along with its subsequent interpretation and understanding, has become a critical bottleneck in modern information systems. The emerged codebook-based solution utilize a globally shared codebook to quantize and dequantize each token, controlling the bpp by adjusting the number of tokens or the codebook size. However, for facial images, which are rich in attributes, such global codebook strategies overlook both the category-specific correlations within images and the semantic differences among tokens, resulting in suboptimal performance, especially at low bpp. Motivated by these observations, we propose a Switchable Token-Specific Codebook Quantization for face image compression, which learns distinct codebook groups for different image categories and assigns an independent codebook to each token. By recording the codebook group to which each token belongs with a small number of bits, our method can reduce the loss incurred when decreasing the size of each codebook group. This enables a larger total number of codebooks under a lower overall bpp, thereby enhancing the expressive capability and improving reconstruction performance. Owing to its generalizable design, our method can be integrated into any existing codebook-based representation learning approach and has demonstrated its effectiveness on face recognition datasets, achieving an average accuracy of 93.51% for reconstructed images at 0.05 bpp.
PVTree: Realistic and Controllable Palm Vein Generation for Recognition Tasks
Mar 04, 2025



Palm vein recognition is an emerging biometric technology that offers enhanced security and privacy. However, acquiring sufficient palm vein data for training deep learning-based recognition models is challenging due to the high costs of data collection and privacy protection constraints. This has led to a growing interest in generating pseudo-palm vein data using generative models. Existing methods, however, often produce unrealistic palm vein patterns or struggle with controlling identity and style attributes. To address these issues, we propose a novel palm vein generation framework named PVTree. First, the palm vein identity is defined by a complex and authentic 3D palm vascular tree, created using an improved Constrained Constructive Optimization (CCO) algorithm. Second, palm vein patterns of the same identity are generated by projecting the same 3D vascular tree into 2D images from different views and converting them into realistic images using a generative model. As a result, PVTree satisfies the need for both identity consistency and intra-class diversity. Extensive experiments conducted on several publicly available datasets demonstrate that our proposed palm vein generation method surpasses existing methods and achieves a higher TAR@FAR=1e-4 under the 1:1 Open-set protocol. To the best of our knowledge, this is the first time that the performance of a recognition model trained on synthetic palm vein data exceeds that of the recognition model trained on real data, which indicates that palm vein image generation research has a promising future.
One-for-More: Continual Diffusion Model for Anomaly Detection
Feb 27, 2025With the rise of generative models, there is a growing interest in unifying all tasks within a generative framework. Anomaly detection methods also fall into this scope and utilize diffusion models to generate or reconstruct normal samples when given arbitrary anomaly images. However, our study found that the diffusion model suffers from severe ``faithfulness hallucination'' and ``catastrophic forgetting'', which can't meet the unpredictable pattern increments. To mitigate the above problems, we propose a continual diffusion model that uses gradient projection to achieve stable continual learning. Gradient projection deploys a regularization on the model updating by modifying the gradient towards the direction protecting the learned knowledge. But as a double-edged sword, it also requires huge memory costs brought by the Markov process. Hence, we propose an iterative singular value decomposition method based on the transitive property of linear representation, which consumes tiny memory and incurs almost no performance loss. Finally, considering the risk of ``over-fitting'' to normal images of the diffusion model, we propose an anomaly-masked network to enhance the condition mechanism of the diffusion model. For continual anomaly detection, ours achieves first place in 17/18 settings on MVTec and VisA. Code is available at https://github.com/FuNz-0/One-for-More
Building a Strong Pre-Training Baseline for Universal 3D Large-Scale Perception
May 12, 2024



An effective pre-training framework with universal 3D representations is extremely desired in perceiving large-scale dynamic scenes. However, establishing such an ideal framework that is both task-generic and label-efficient poses a challenge in unifying the representation of the same primitive across diverse scenes. The current contrastive 3D pre-training methods typically follow a frame-level consistency, which focuses on the 2D-3D relationships in each detached image. Such inconsiderate consistency greatly hampers the promising path of reaching an universal pre-training framework: (1) The cross-scene semantic self-conflict, i.e., the intense collision between primitive segments of the same semantics from different scenes; (2) Lacking a globally unified bond that pushes the cross-scene semantic consistency into 3D representation learning. To address above challenges, we propose a CSC framework that puts a scene-level semantic consistency in the heart, bridging the connection of the similar semantic segments across various scenes. To achieve this goal, we combine the coherent semantic cues provided by the vision foundation model and the knowledge-rich cross-scene prototypes derived from the complementary multi-modality information. These allow us to train a universal 3D pre-training model that facilitates various downstream tasks with less fine-tuning efforts. Empirically, we achieve consistent improvements over SOTA pre-training approaches in semantic segmentation (+1.4% mIoU), object detection (+1.0% mAP), and panoptic segmentation (+3.0% PQ) using their task-specific 3D network on nuScenes. Code is released at https://github.com/chenhaomingbob/CSC, hoping to inspire future research.
SDPose: Tokenized Pose Estimation via Circulation-Guide Self-Distillation
Apr 04, 2024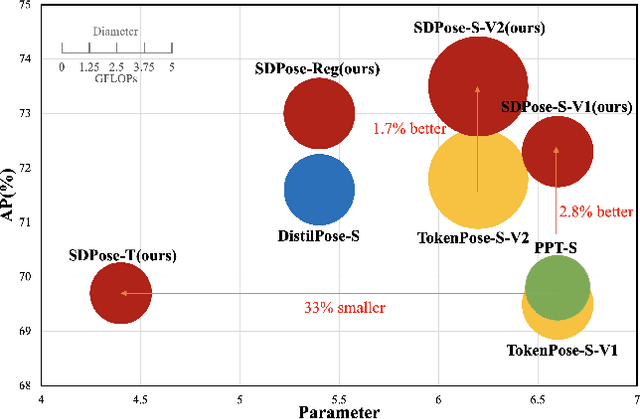
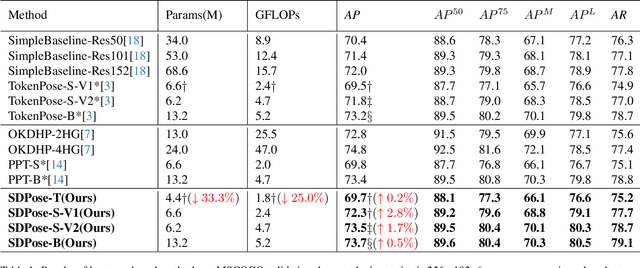
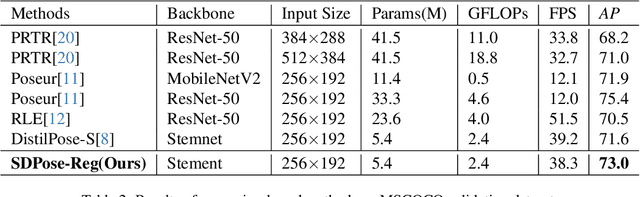
Recently, transformer-based methods have achieved state-of-the-art prediction quality on human pose estimation(HPE). Nonetheless, most of these top-performing transformer-based models are too computation-consuming and storage-demanding to deploy on edge computing platforms. Those transformer-based models that require fewer resources are prone to under-fitting due to their smaller scale and thus perform notably worse than their larger counterparts. Given this conundrum, we introduce SDPose, a new self-distillation method for improving the performance of small transformer-based models. To mitigate the problem of under-fitting, we design a transformer module named Multi-Cycled Transformer(MCT) based on multiple-cycled forwards to more fully exploit the potential of small model parameters. Further, in order to prevent the additional inference compute-consuming brought by MCT, we introduce a self-distillation scheme, extracting the knowledge from the MCT module to a naive forward model. Specifically, on the MSCOCO validation dataset, SDPose-T obtains 69.7% mAP with 4.4M parameters and 1.8 GFLOPs. Furthermore, SDPose-S-V2 obtains 73.5% mAP on the MSCOCO validation dataset with 6.2M parameters and 4.7 GFLOPs, achieving a new state-of-the-art among predominant tiny neural network methods. Our code is available at https://github.com/MartyrPenink/SDPose.
RPG-Palm: Realistic Pseudo-data Generation for Palmprint Recognition
Aug 08, 2023



Palmprint recently shows great potential in recognition applications as it is a privacy-friendly and stable biometric. However, the lack of large-scale public palmprint datasets limits further research and development of palmprint recognition. In this paper, we propose a novel realistic pseudo-palmprint generation (RPG) model to synthesize palmprints with massive identities. We first introduce a conditional modulation generator to improve the intra-class diversity. Then an identity-aware loss is proposed to ensure identity consistency against unpaired training. We further improve the B\'ezier palm creases generation strategy to guarantee identity independence. Extensive experimental results demonstrate that synthetic pretraining significantly boosts the recognition model performance. For example, our model improves the state-of-the-art B\'ezierPalm by more than $5\%$ and $14\%$ in terms of TAR@FAR=1e-6 under the $1:1$ and $1:3$ Open-set protocol. When accessing only $10\%$ of the real training data, our method still outperforms ArcFace with $100\%$ real training data, indicating that we are closer to real-data-free palmprint recognition.
Coordinating Cross-modal Distillation for Molecular Property Prediction
Nov 30, 2022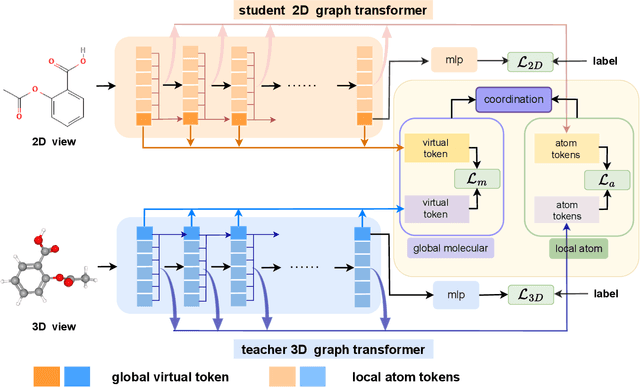
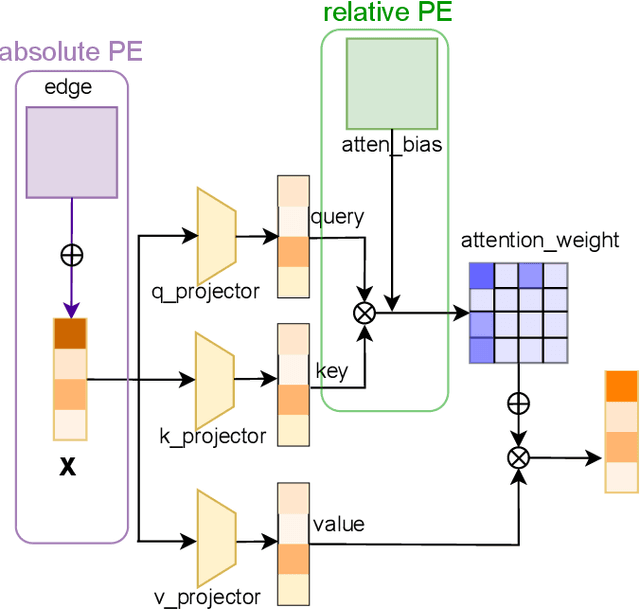
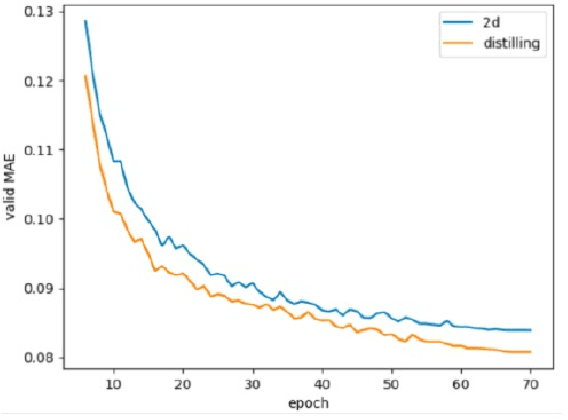
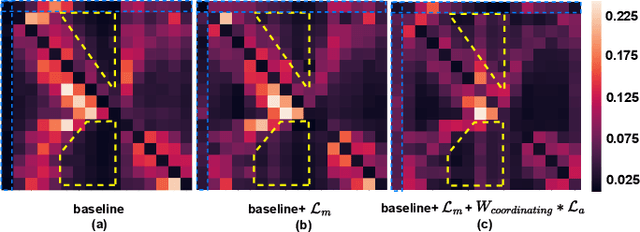
In recent years, molecular graph representation learning (GRL) has drawn much more attention in molecular property prediction (MPP) problems. The existing graph methods have demonstrated that 3D geometric information is significant for better performance in MPP. However, accurate 3D structures are often costly and time-consuming to obtain, limiting the large-scale application of GRL. It is an intuitive solution to train with 3D to 2D knowledge distillation and predict with only 2D inputs. But some challenging problems remain open for 3D to 2D distillation. One is that the 3D view is quite distinct from the 2D view, and the other is that the gradient magnitudes of atoms in distillation are discrepant and unstable due to the variable molecular size. To address these challenging problems, we exclusively propose a distillation framework that contains global molecular distillation and local atom distillation. We also provide a theoretical insight to justify how to coordinate atom and molecular information, which tackles the drawback of variable molecular size for atom information distillation. Experimental results on two popular molecular datasets demonstrate that our proposed model achieves superior performance over other methods. Specifically, on the largest MPP dataset PCQM4Mv2 served as an "ImageNet Large Scale Visual Recognition Challenge" in the field of graph ML, the proposed method achieved a 6.9% improvement compared with the best works. And we obtained fourth place with the MAE of 0.0734 on the test-challenge set for OGB-LSC 2022 Graph Regression Task. We will release the code soon.
ECO-TR: Efficient Correspondences Finding Via Coarse-to-Fine Refinement
Sep 25, 2022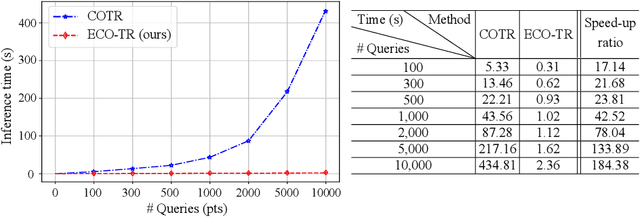
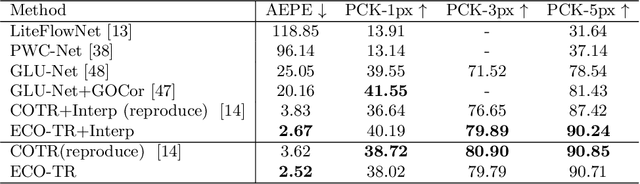
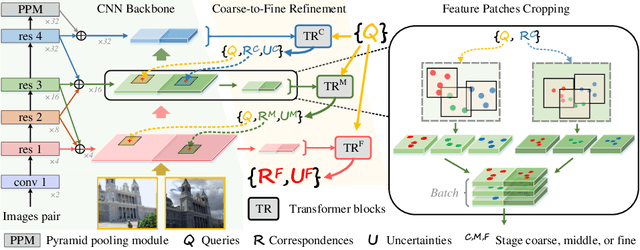
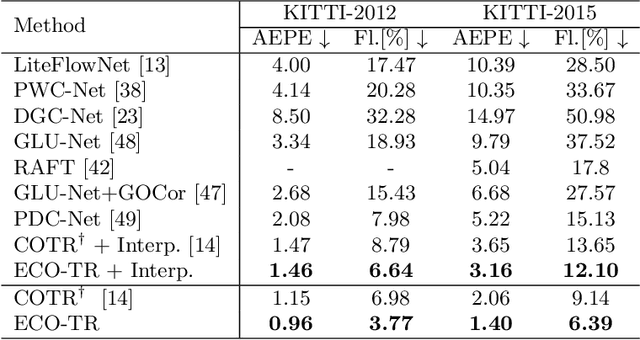
Modeling sparse and dense image matching within a unified functional correspondence model has recently attracted increasing research interest. However, existing efforts mainly focus on improving matching accuracy while ignoring its efficiency, which is crucial for realworld applications. In this paper, we propose an efficient structure named Efficient Correspondence Transformer (ECO-TR) by finding correspondences in a coarse-to-fine manner, which significantly improves the efficiency of functional correspondence model. To achieve this, multiple transformer blocks are stage-wisely connected to gradually refine the predicted coordinates upon a shared multi-scale feature extraction network. Given a pair of images and for arbitrary query coordinates, all the correspondences are predicted within a single feed-forward pass. We further propose an adaptive query-clustering strategy and an uncertainty-based outlier detection module to cooperate with the proposed framework for faster and better predictions. Experiments on various sparse and dense matching tasks demonstrate the superiority of our method in both efficiency and effectiveness against existing state-of-the-arts.