 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Feature Alignment for Adversarial Training
Jun 16, 2021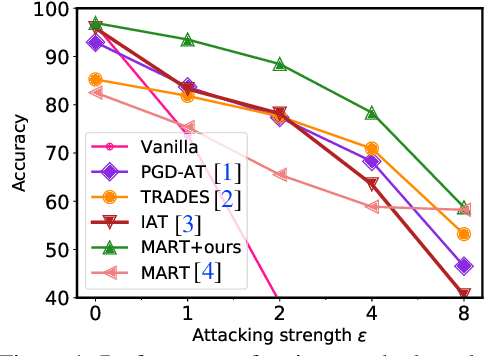
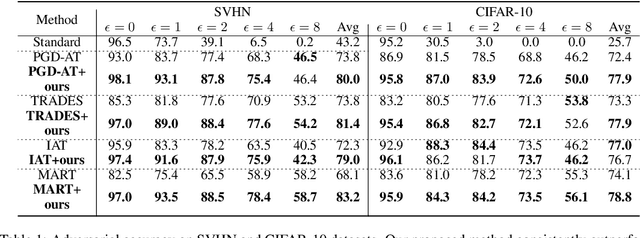
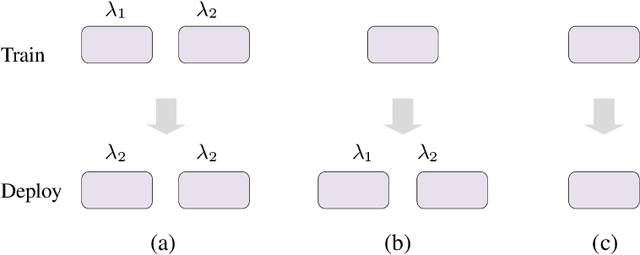
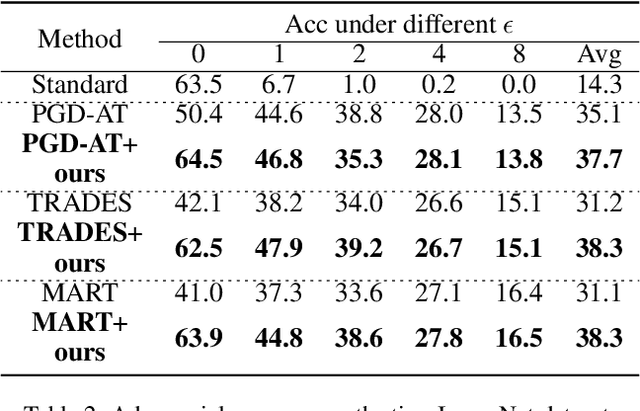
Recent studies reveal that Convolutional Neural Networks (CNNs) are typically vulnerable to adversarial attacks, which pose a threat to security-sensitive applications. Many adversarial defense methods improve robustness at the cost of accuracy, raising the contradiction between standard and adversarial accuracies. In this paper, we observe an interesting phenomenon that feature statistics change monotonically and smoothly w.r.t the rising of attacking strength. Based on this observation, we propose the adaptive feature alignment (AFA) to generate features of arbitrary attacking strengths. Our method is trained to automatically align features of arbitrary attacking strength. This is done by predicting a fusing weight in a dual-BN architecture. Unlike previous works that need to either retrain the model or manually tune a hyper-parameters for different attacking strengths, our method can deal with arbitrary attacking strengths with a single model without introducing any hyper-parameter. Importantly, our method improves the model robustness against adversarial samples without incurring much loss in standard accuracy. Experiments on CIFAR-10, SVHN, and tiny-ImageNet datasets demonstrate that our method outperforms the state-of-the-art under a wide range of attacking strengths.
Consistent Instance False Positive Improves Fairness in Face Recognition
Jun 10, 2021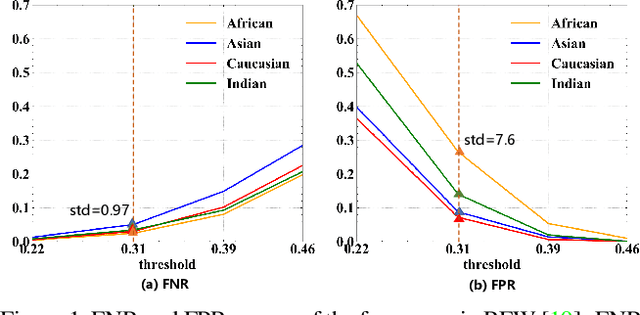
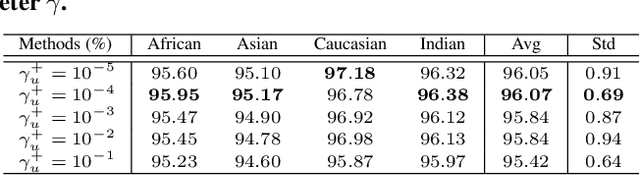
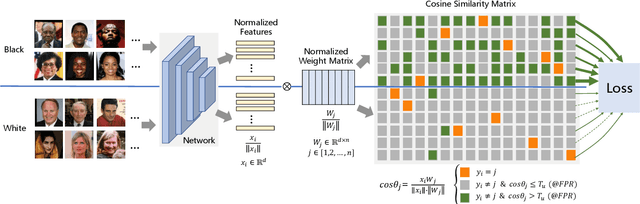
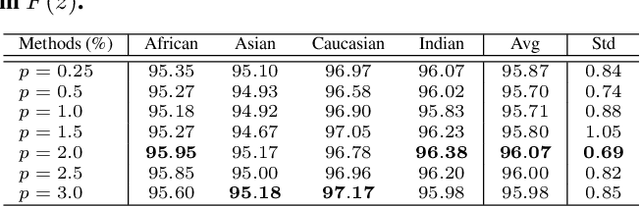
Demographic bias is a significant challenge in practical face recognition systems. Existing methods heavily rely on accurate demographic annotations. However, such annotations are usually unavailable in real scenarios. Moreover, these methods are typically designed for a specific demographic group and are not general enough. In this paper, we propose a false positive rate penalty loss, which mitigates face recognition bias by increasing the consistency of instance False Positive Rate (FPR). Specifically, we first define the instance FPR as the ratio between the number of the non-target similarities above a unified threshold and the total number of the non-target similarities. The unified threshold is estimated for a given total FPR. Then, an additional penalty term, which is in proportion to the ratio of instance FPR overall FPR, is introduced into the denominator of the softmax-based loss. The larger the instance FPR, the larger the penalty. By such unequal penalties, the instance FPRs are supposed to be consistent. Compared with the previous debiasing methods, our method requires no demographic annotations. Thus, it can mitigate the bias among demographic groups divided by various attributes, and these attributes are not needed to be previously predefined during training. Extensive experimental results on popular benchmarks demonstrate the superiority of our method over state-of-the-art competitors. Code and trained models are available at https://github.com/Tencent/TFace.
Federated Face Recognition
May 06, 2021
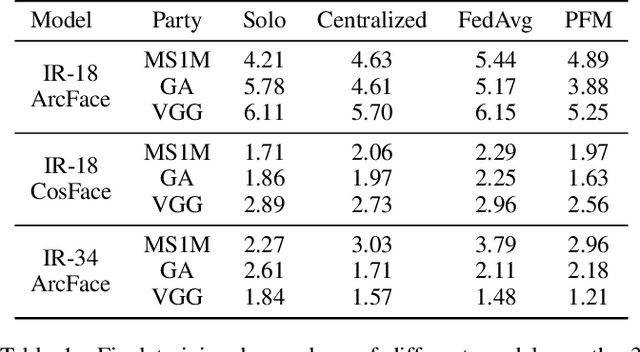
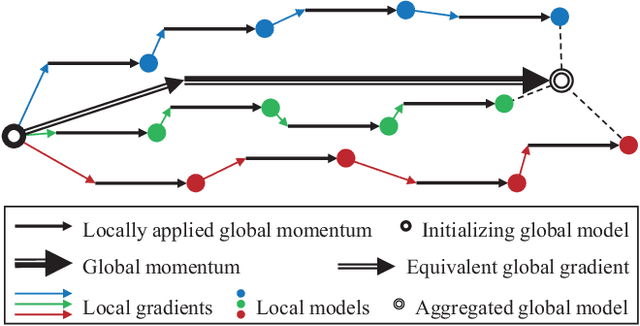
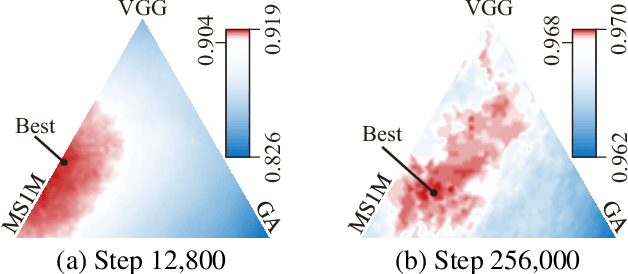
Face recognition has been extensively studied in computer vision and artificial intelligence communities in recent years. An important issue of face recognition is data privacy, which receives more and more public concerns. As a common privacy-preserving technique, Federated Learning is proposed to train a model cooperatively without sharing data between parties. However, as far as we know, it has not been successfully applied in face recognition. This paper proposes a framework named FedFace to innovate federated learning for face recognition. Specifically, FedFace relies on two major innovative algorithms, Partially Federated Momentum (PFM) and Federated Validation (FV). PFM locally applies an estimated equivalent global momentum to approximating the centralized momentum-SGD efficiently. FV repeatedly searches for better federated aggregating weightings via testing the aggregated models on some private validation datasets, which can improve the model's generalization ability. The ablation study and extensive experiments validate the effectiveness of the FedFace method and show that it is comparable to or even better than the centralized baseline in performance.
SDD-FIQA: Unsupervised Face Image Quality Assessment with Similarity Distribution Distance
Mar 10, 2021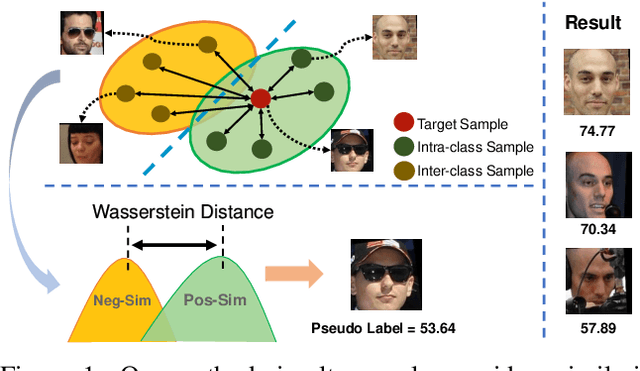
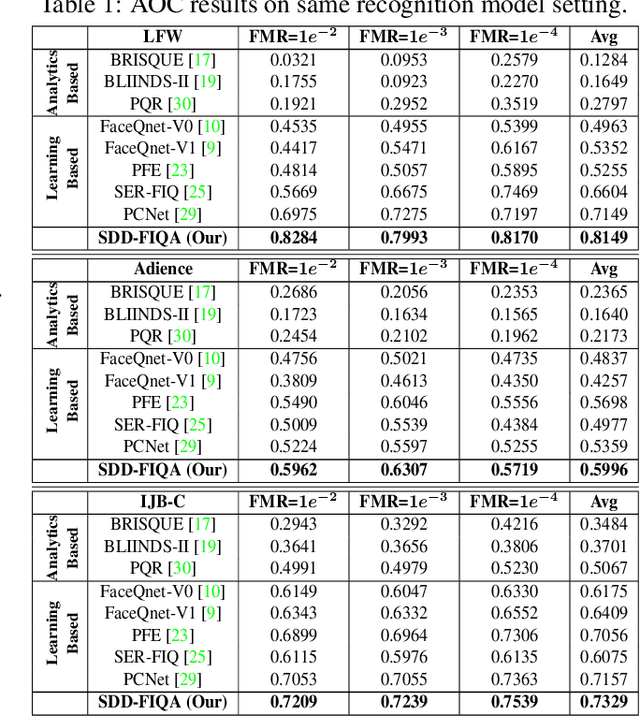
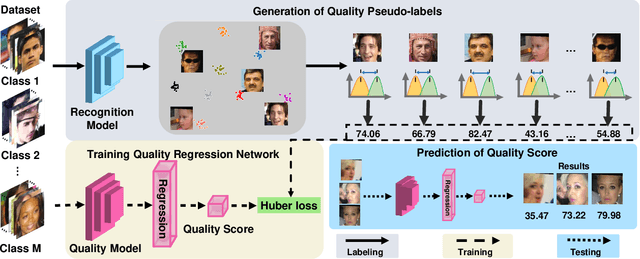
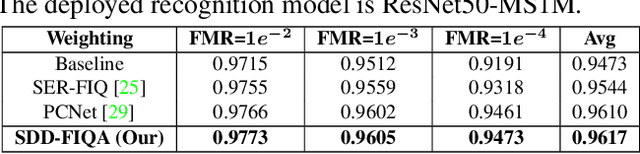
In recent years, Face Image Quality Assessment (FIQA) has become an indispensable part of the face recognition system to guarantee the stability and reliability of recognition performance in an unconstrained scenario. For this purpose, the FIQA method should consider both the intrinsic property and the recognizability of the face image. Most previous works aim to estimate the sample-wise embedding uncertainty or pair-wise similarity as the quality score, which only considers the information from partial intra-class. However, these methods ignore the valuable information from the inter-class, which is for estimating to the recognizability of face image. In this work, we argue that a high-quality face image should be similar to its intra-class samples and dissimilar to its inter-class samples. Thus, we propose a novel unsupervised FIQA method that incorporates Similarity Distribution Distance for Face Image Quality Assessment (SDD-FIQA). Our method generates quality pseudo-labels by calculating the Wasserstein Distance (WD) between the intra-class similarity distributions and inter-class similarity distributions. With these quality pseudo-labels, we are capable of training a regression network for quality prediction. Extensive experiments on benchmark datasets demonstrate that the proposed SDD-FIQA surpasses the state-of-the-arts by an impressive margin. Meanwhile, our method shows good generalization across different recognition systems.
CurricularFace: Adaptive Curriculum Learning Loss for Deep Face Recognition
Apr 01, 2020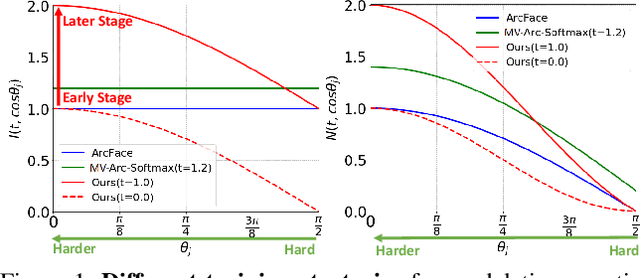
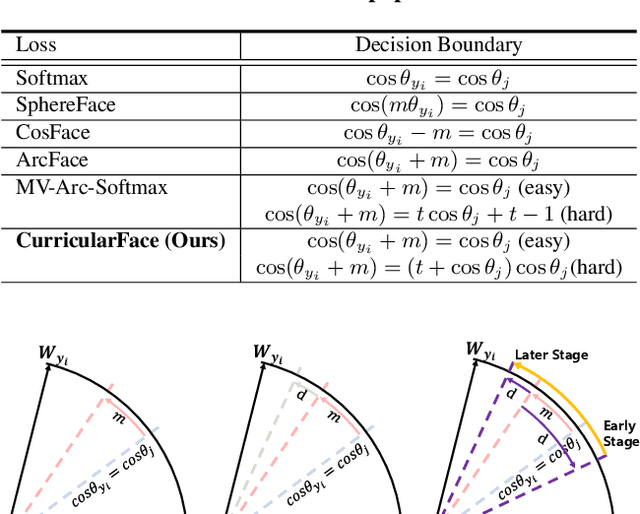
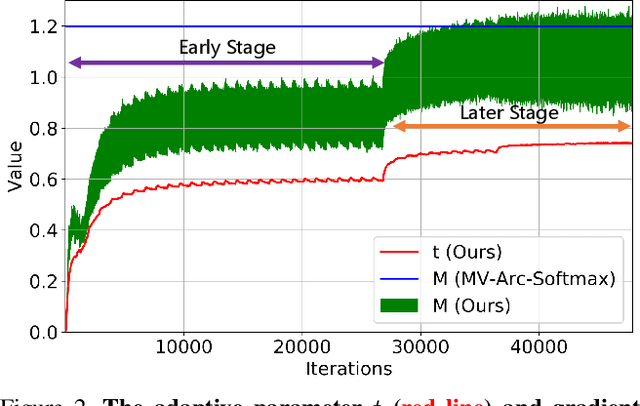
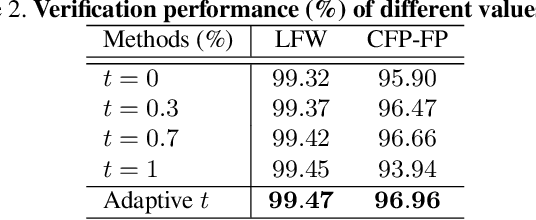
As an emerging topic in face recognition, designing margin-based loss functions can increase the feature margin between different classes for enhanced discriminability. More recently, the idea of mining-based strategies is adopted to emphasize the misclassified samples, achieving promising results. However, during the entire training process, the prior methods either do not explicitly emphasize the sample based on its importance that renders the hard samples not fully exploited; or explicitly emphasize the effects of semi-hard/hard samples even at the early training stage that may lead to convergence issue. In this work, we propose a novel Adaptive Curriculum Learning loss (CurricularFace) that embeds the idea of curriculum learning into the loss function to achieve a novel training strategy for deep face recognition, which mainly addresses easy samples in the early training stage and hard ones in the later stage. Specifically, our CurricularFace adaptively adjusts the relative importance of easy and hard samples during different training stages. In each stage, different samples are assigned with different importance according to their corresponding difficultness. Extensive experimental results on popular benchmarks demonstrate the superiority of our CurricularFace over the state-of-the-art competitors.
Towards Palmprint Verification On Smartphones
Mar 30, 2020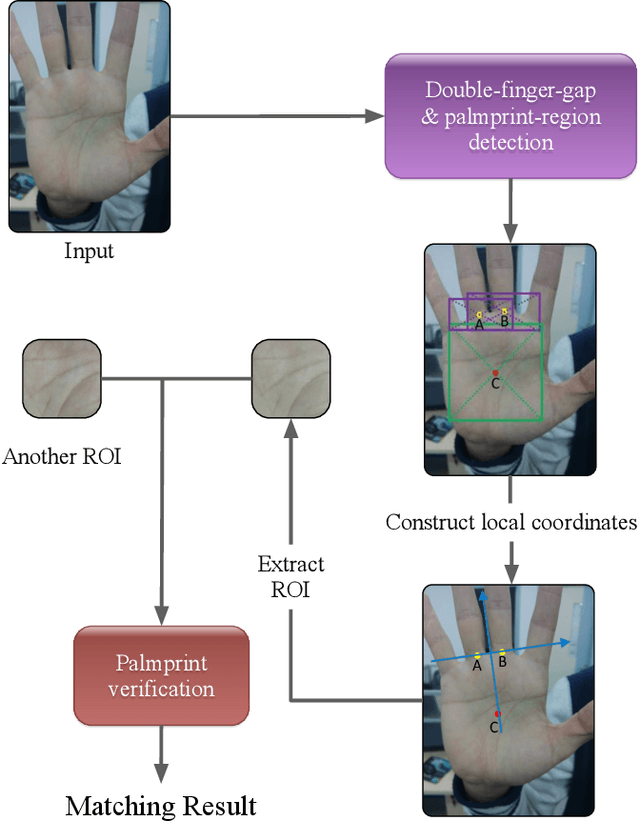
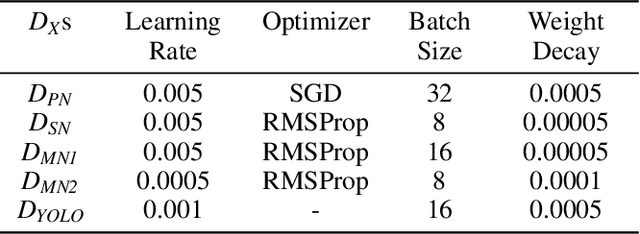
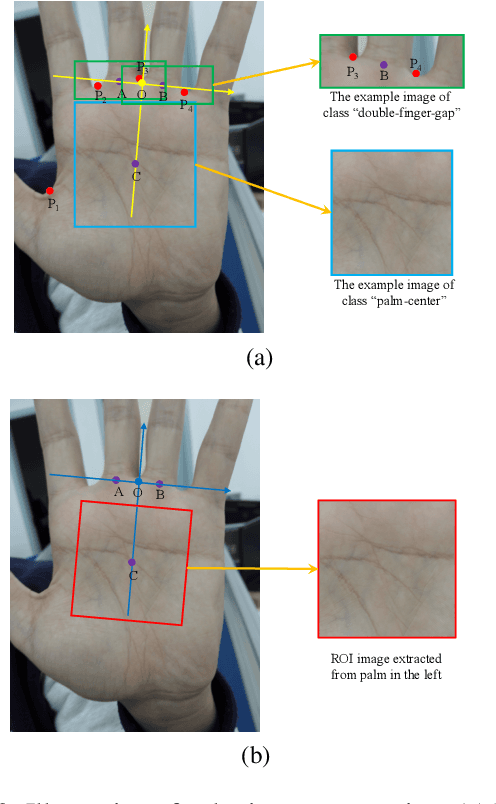
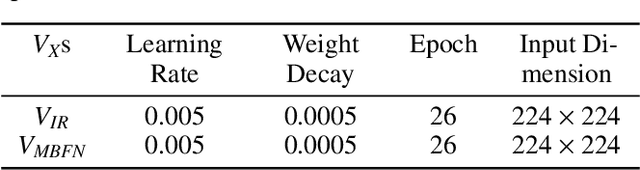
With the rapid development of mobile devices, smartphones have gradually become an indispensable part of people's lives. Meanwhile, biometric authentication has been corroborated to be an effective method for establishing a person's identity with high confidence. Hence, recently, biometric technologies for smartphones have also become increasingly sophisticated and popular. But it is noteworthy that the application potential of palmprints for smartphones is seriously underestimated. Studies in the past two decades have shown that palmprints have outstanding merits in uniqueness and permanence, and have high user acceptance. However, currently, studies specializing in palmprint verification for smartphones are still quite sporadic, especially when compared to face- or fingerprint-oriented ones. In this paper, aiming to fill the aforementioned research gap, we conducted a thorough study of palmprint verification on smartphones and our contributions are twofold. First, to facilitate the study of palmprint verification on smartphones, we established an annotated palmprint dataset named MPD, which was collected by multi-brand smartphones in two separate sessions with various backgrounds and illumination conditions. As the largest dataset in this field, MPD contains 16,000 palm images collected from 200 subjects. Second, we built a DCNN-based palmprint verification system named DeepMPV+ for smartphones. In DeepMPV+, two key steps, ROI extraction and ROI matching, are both formulated as learning problems and then solved naturally by modern DCNN models. The efficiency and efficacy of DeepMPV+ have been corroborated by extensive experiments. To make our results fully reproducible, the labeled dataset and the relevant source codes have been made publicly available at https://cslinzhang.github.io/MobilePalmPrint/.
Distribution Distillation Loss: Generic Approach for Improving Face Recognition from Hard Samples
Feb 10, 2020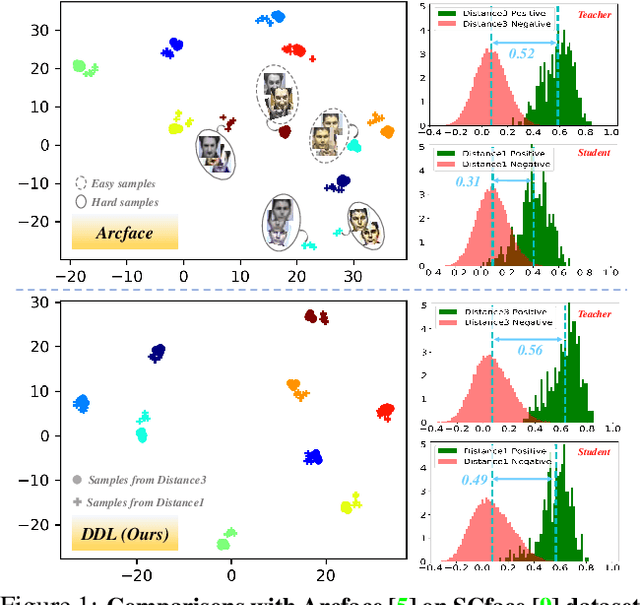
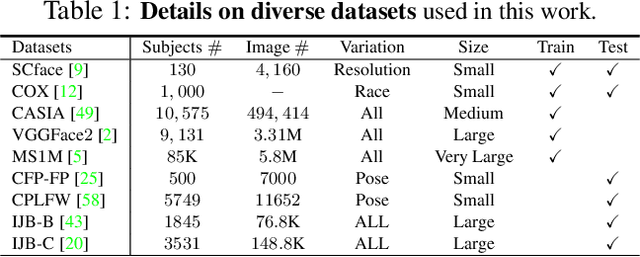
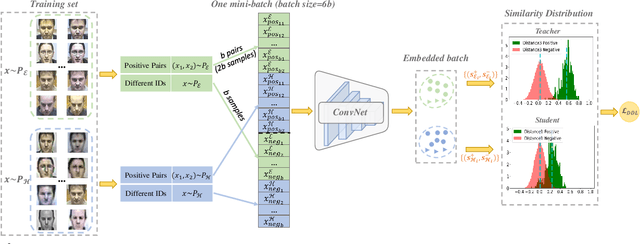
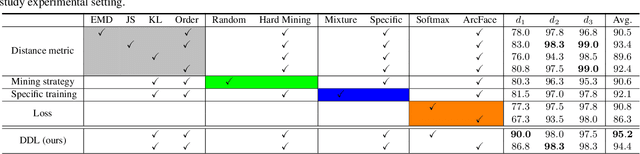
Large facial variations are the main challenge in face recognition. To this end, previous variation-specific methods make full use of task-related prior to design special network losses, which are typically not general among different tasks and scenarios. In contrast, the existing generic methods focus on improving the feature discriminability to minimize the intra-class distance while maximizing the interclass distance, which perform well on easy samples but fail on hard samples. To improve the performance on those hard samples for general tasks, we propose a novel Distribution Distillation Loss to narrow the performance gap between easy and hard samples, which is a simple, effective and generic for various types of facial variations. Specifically, we first adopt state-of-the-art classifiers such as ArcFace to construct two similarity distributions: teacher distribution from easy samples and student distribution from hard samples. Then, we propose a novel distribution-driven loss to constrain the student distribution to approximate the teacher distribution, which thus leads to smaller overlap between the positive and negative pairs in the student distribution. We have conducted extensive experiments on both generic large-scale face benchmarks and benchmarks with diverse variations on race, resolution and pose. The quantitative results demonstrate the superiority of our method over strong baselines, e.g., Arcface and Cosface.