 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent Instance False Positive Improves Fairness in Face Recognition
Jun 10, 2021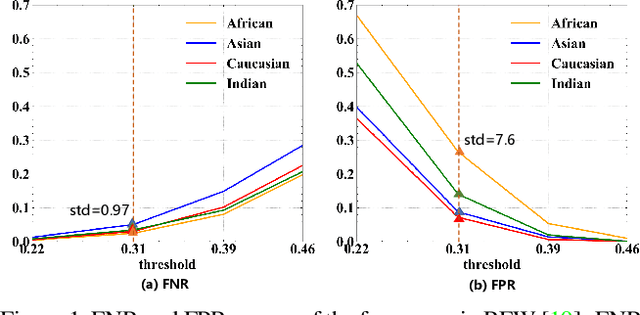
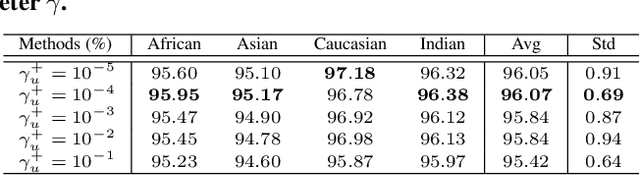
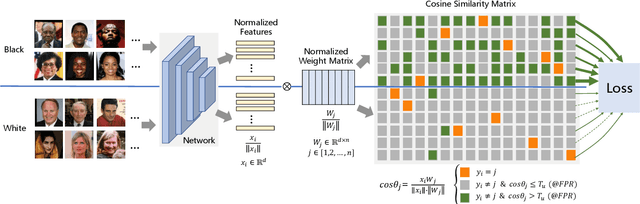
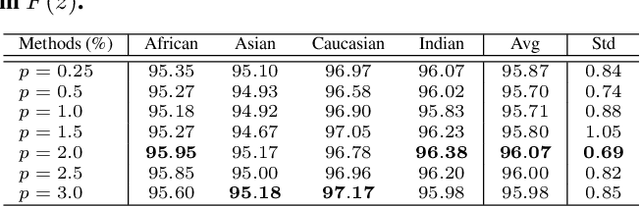
Demographic bias is a significant challenge in practical face recognition systems. Existing methods heavily rely on accurate demographic annotations. However, such annotations are usually unavailable in real scenarios. Moreover, these methods are typically designed for a specific demographic group and are not general enough. In this paper, we propose a false positive rate penalty loss, which mitigates face recognition bias by increasing the consistency of instance False Positive Rate (FPR). Specifically, we first define the instance FPR as the ratio between the number of the non-target similarities above a unified threshold and the total number of the non-target similarities. The unified threshold is estimated for a given total FPR. Then, an additional penalty term, which is in proportion to the ratio of instance FPR overall FPR, is introduced into the denominator of the softmax-based loss. The larger the instance FPR, the larger the penalty. By such unequal penalties, the instance FPRs are supposed to be consistent. Compared with the previous debiasing methods, our method requires no demographic annotations. Thus, it can mitigate the bias among demographic groups divided by various attributes, and these attributes are not needed to be previously predefined during training. Extensive experimental results on popular benchmarks demonstrate the superiority of our method over state-of-the-art competitors. Code and trained models are available at https://github.com/Tencent/TFace.
Federated Face Recognition
May 06, 2021
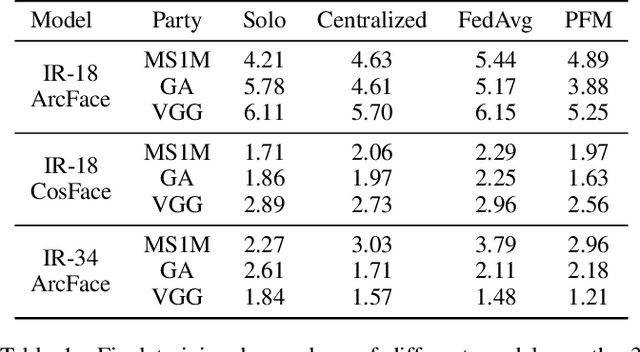
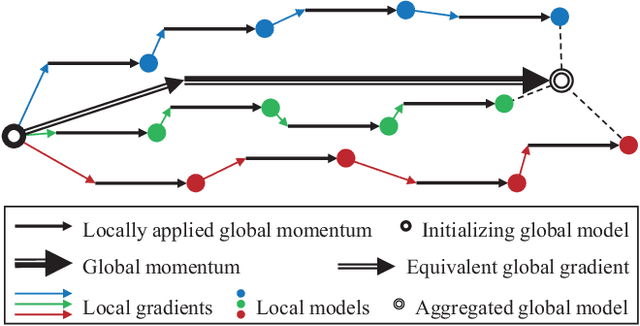
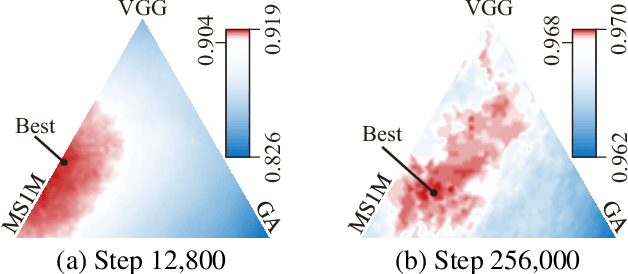
Face recognition has been extensively studied in computer vision and artificial intelligence communities in recent years. An important issue of face recognition is data privacy, which receives more and more public concerns. As a common privacy-preserving technique, Federated Learning is proposed to train a model cooperatively without sharing data between parties. However, as far as we know, it has not been successfully applied in face recognition. This paper proposes a framework named FedFace to innovate federated learning for face recognition. Specifically, FedFace relies on two major innovative algorithms, Partially Federated Momentum (PFM) and Federated Validation (FV). PFM locally applies an estimated equivalent global momentum to approximating the centralized momentum-SGD efficiently. FV repeatedly searches for better federated aggregating weightings via testing the aggregated models on some private validation datasets, which can improve the model's generalization ability. The ablation study and extensive experiments validate the effectiveness of the FedFace method and show that it is comparable to or even better than the centralized baseline in performance.
CurricularFace: Adaptive Curriculum Learning Loss for Deep Face Recognition
Apr 01, 2020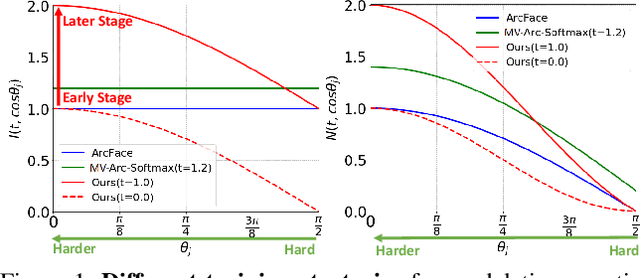
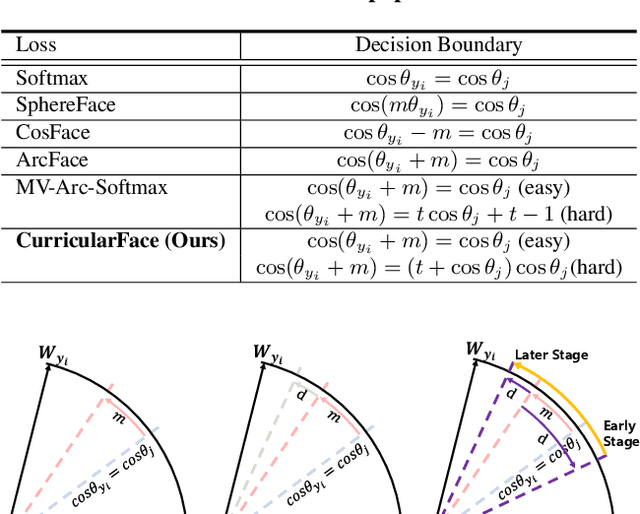
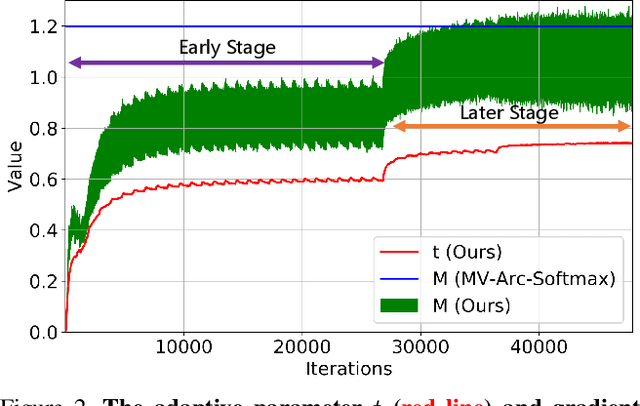
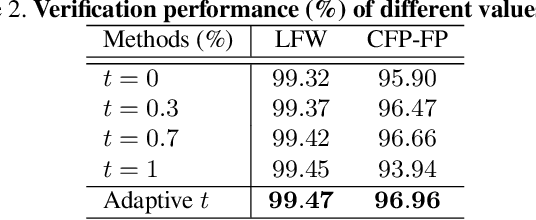
As an emerging topic in face recognition, designing margin-based loss functions can increase the feature margin between different classes for enhanced discriminability. More recently, the idea of mining-based strategies is adopted to emphasize the misclassified samples, achieving promising results. However, during the entire training process, the prior methods either do not explicitly emphasize the sample based on its importance that renders the hard samples not fully exploited; or explicitly emphasize the effects of semi-hard/hard samples even at the early training stage that may lead to convergence issue. In this work, we propose a novel Adaptive Curriculum Learning loss (CurricularFace) that embeds the idea of curriculum learning into the loss function to achieve a novel training strategy for deep face recognition, which mainly addresses easy samples in the early training stage and hard ones in the later stage. Specifically, our CurricularFace adaptively adjusts the relative importance of easy and hard samples during different training stages. In each stage, different samples are assigned with different importance according to their corresponding difficultness. Extensive experimental results on popular benchmarks demonstrate the superiority of our CurricularFace over the state-of-the-art competitors.
Distribution Distillation Loss: Generic Approach for Improving Face Recognition from Hard Samples
Feb 10, 2020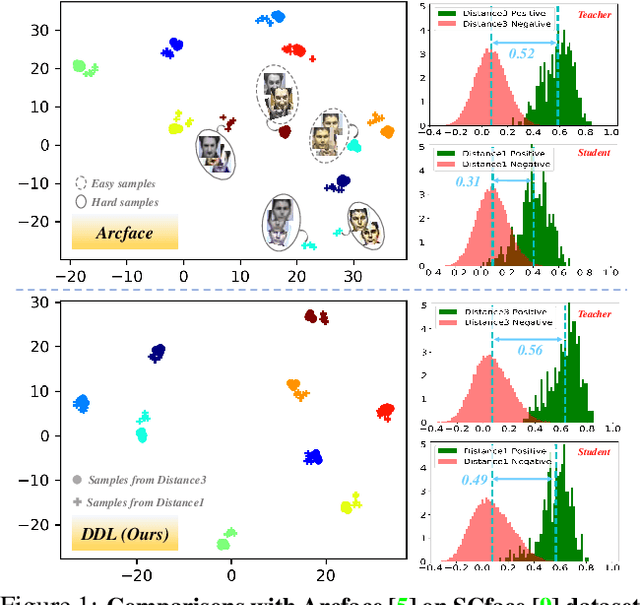
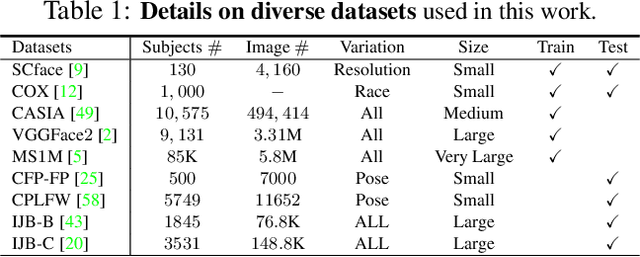
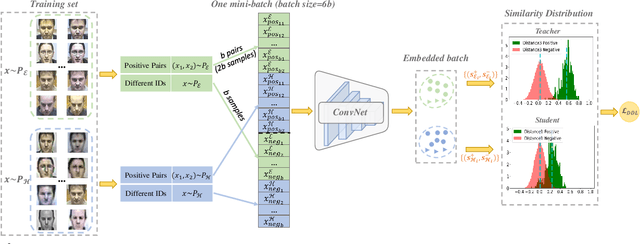
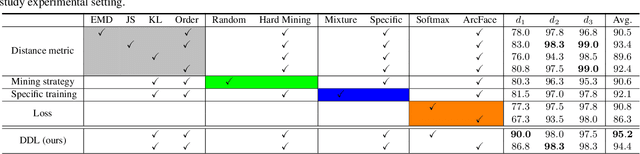
Large facial variations are the main challenge in face recognition. To this end, previous variation-specific methods make full use of task-related prior to design special network losses, which are typically not general among different tasks and scenarios. In contrast, the existing generic methods focus on improving the feature discriminability to minimize the intra-class distance while maximizing the interclass distance, which perform well on easy samples but fail on hard samples. To improve the performance on those hard samples for general tasks, we propose a novel Distribution Distillation Loss to narrow the performance gap between easy and hard samples, which is a simple, effective and generic for various types of facial variations. Specifically, we first adopt state-of-the-art classifiers such as ArcFace to construct two similarity distributions: teacher distribution from easy samples and student distribution from hard samples. Then, we propose a novel distribution-driven loss to constrain the student distribution to approximate the teacher distribution, which thus leads to smaller overlap between the positive and negative pairs in the student distribution. We have conducted extensive experiments on both generic large-scale face benchmarks and benchmarks with diverse variations on race, resolution and pose. The quantitative results demonstrate the superiority of our method over strong baselines, e.g., Arcface and Cosface.