 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASFD: Automatic and Scalable Face Detector
Jan 26, 2022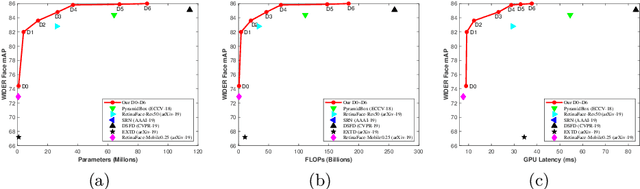

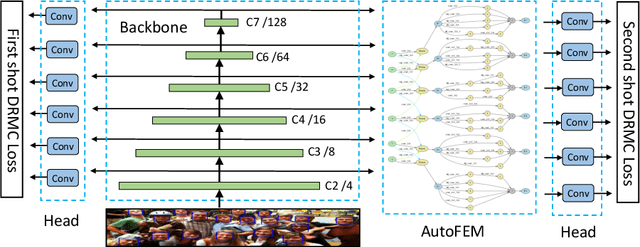
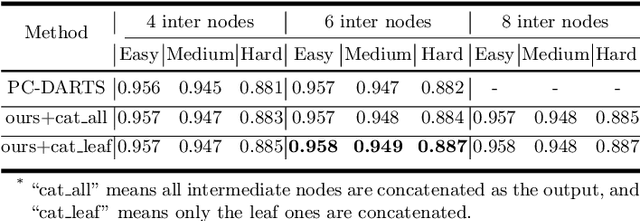
Along with current multi-scale based detectors, Feature Aggregation and Enhancement (FAE) modules have shown superior performance gains for cutting-edge object detection. However, these hand-crafted FAE modules show inconsistent improvements on face detection, which is mainly due to the significant distribution difference between its training and applying corpus, COCO vs. WIDER Face. To tackle this problem, we essentially analyse the effect of data distribution, and consequently propose to search an effective FAE architecture, termed AutoFAE by a differentiable architecture search, which outperforms all existing FAE modules in face detection with a considerable margin. Upon the found AutoFAE and existing backbones, a supernet is further built and trained, which automatically obtains a family of detectors under the different complexity constraints. Extensive experiments conducted on popular benchmarks, WIDER Face and FDDB, demonstrate the state-of-the-art performance-efficiency trade-off for the proposed automatic and scalable face detector (ASFD) family. In particular, our strong ASFD-D6 outperforms the best competitor with AP 96.7/96.2/92.1 on WIDER Face test, and the lightweight ASFD-D0 costs about 3.1 ms, more than 320 FPS, on the V100 GPU with VGA-resolution images.
LSTC: Boosting Atomic Action Detection with Long-Short-Term Context
Oct 19, 2021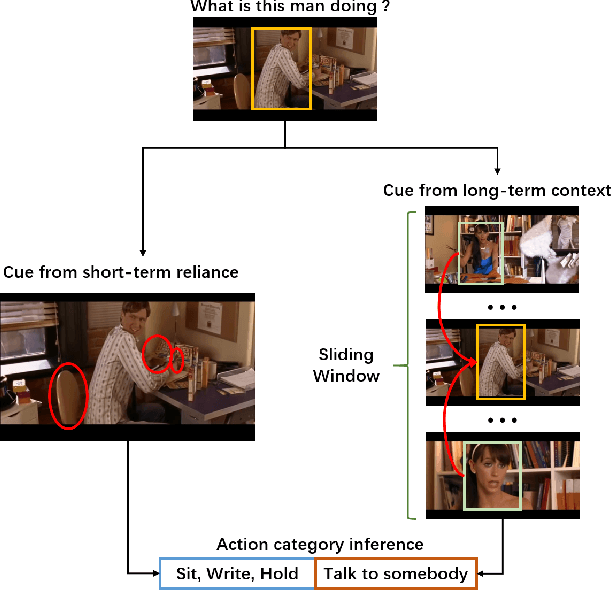
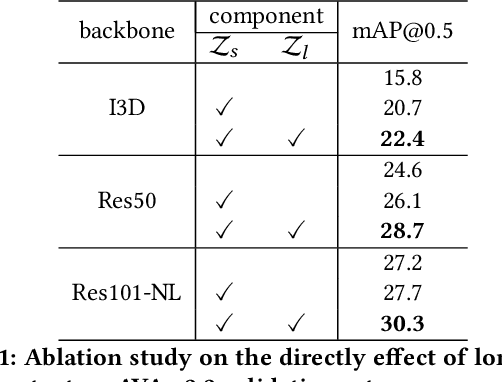
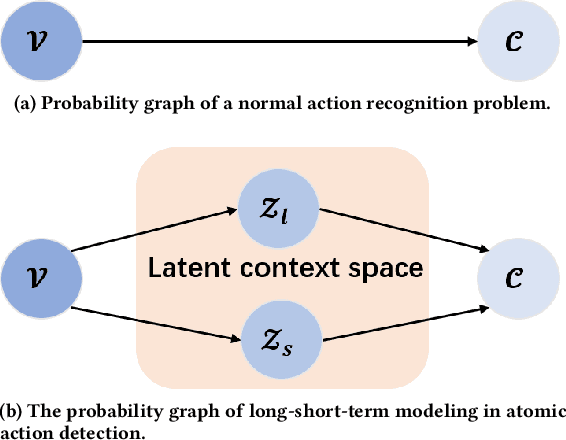
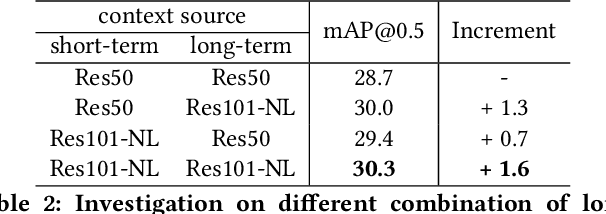
In this paper, we place the atomic action detection problem into a Long-Short Term Context (LSTC) to analyze how the temporal reliance among video signals affect the action detection results. To do this, we decompose the action recognition pipeline into short-term and long-term reliance, in terms of the hypothesis that the two kinds of context are conditionally independent given the objective action instance. Within our design, a local aggregation branch is utilized to gather dense and informative short-term cues, while a high order long-term inference branch is designed to reason the objective action class from high-order interaction between actor and other person or person pairs. Both branches independently predict the context-specific actions and the results are merged in the end. We demonstrate that both temporal grains are beneficial to atomic action recognition. On the mainstream benchmarks of atomic action detection, our design can bring significant performance gain from the existing state-of-the-art pipeline. The code of this project can be found at [this url](https://github.com/TencentYoutuResearch/ActionDetection-LSTC)
Spatiotemporal Inconsistency Learning for DeepFake Video Detection
Sep 07, 2021
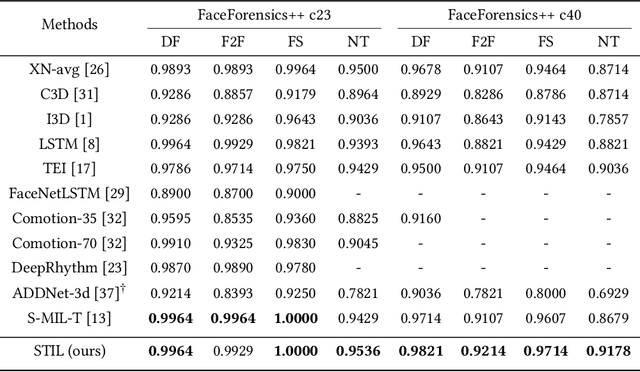
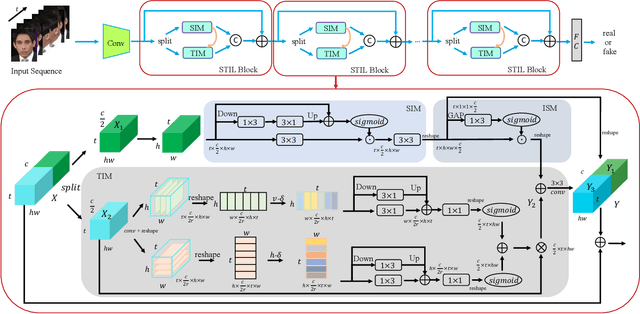
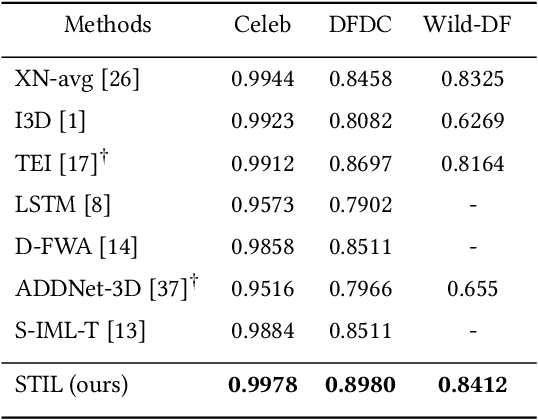
The rapid development of facial manipulation techniques has aroused public concerns in recent years. Following the success of deep learning, existing methods always formulate DeepFake video detection as a binary classification problem and develop frame-based and video-based solutions. However, little attention has been paid to capturing the spatial-temporal inconsistency in forged videos. To address this issue, we term this task as a Spatial-Temporal Inconsistency Learning (STIL) process and instantiate it into a novel STIL block, which consists of a Spatial Inconsistency Module (SIM), a Temporal Inconsistency Module (TIM), and an Information Supplement Module (ISM). Specifically, we present a novel temporal modeling paradigm in TIM by exploiting the temporal difference over adjacent frames along with both horizontal and vertical directions. And the ISM simultaneously utilizes the spatial information from SIM and temporal information from TIM to establish a more comprehensive spatial-temporal representation. Moreover, our STIL block is flexible and could be plugged into existing 2D CNNs. Extensive experiments and visualizations are presented to demonstrate the effectiveness of our method against the state-of-the-art competitors.
Rethinking Counting and Localization in Crowds:A Purely Point-Based Framework
Aug 07, 2021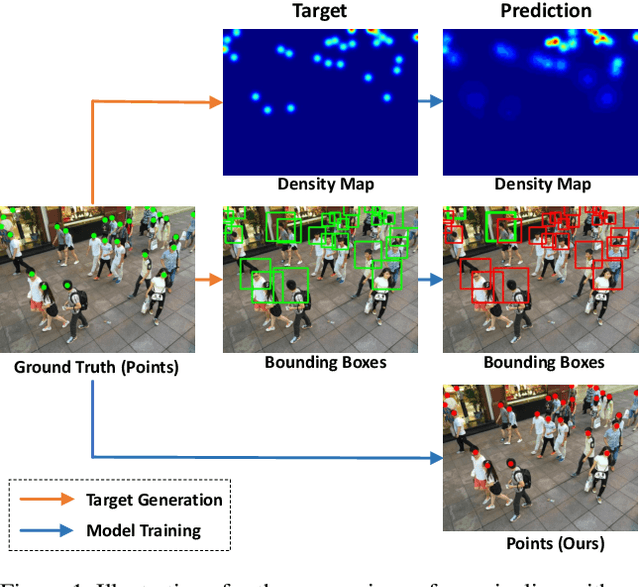
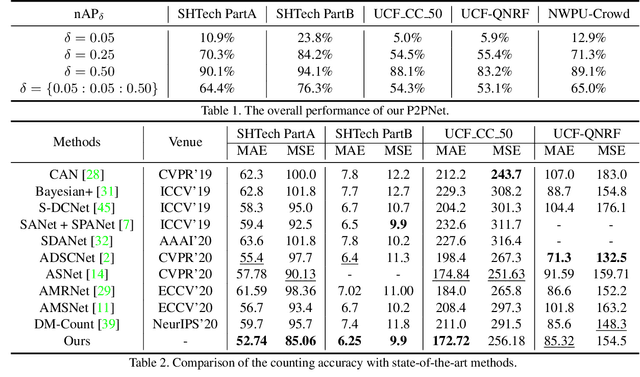
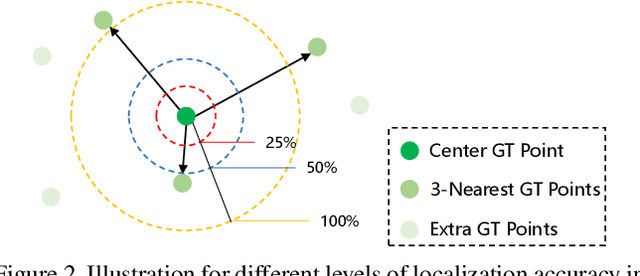
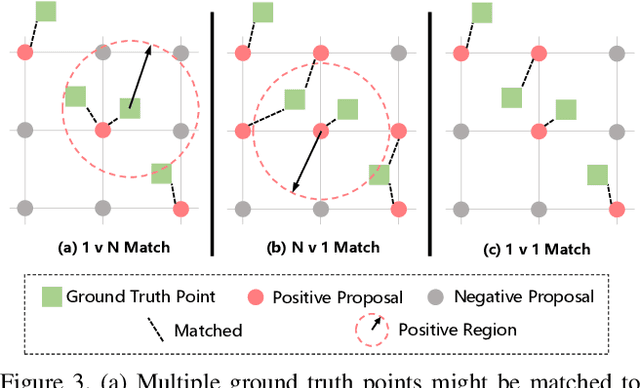
Localizing individuals in crowds is more in accordance with the practical demands of subsequent high-level crowd analysis tasks than simply counting. However, existing localization based methods relying on intermediate representations (\textit{i.e.}, density maps or pseudo boxes) serving as learning targets are counter-intuitive and error-prone. In this paper, we propose a purely point-based framework for joint crowd counting and individual localization. For this framework, instead of merely reporting the absolute counting error at image level, we propose a new metric, called density Normalized Average Precision (nAP), to provide more comprehensive and more precise performance evaluation. Moreover, we design an intuitive solution under this framework, which is called Point to Point Network (P2PNet). P2PNet discards superfluous steps and directly predicts a set of point proposals to represent heads in an image, being consistent with the human annotation results. By thorough analysis, we reveal the key step towards implementing such a novel idea is to assign optimal learning targets for these proposals. Therefore, we propose to conduct this crucial association in an one-to-one matching manner using the Hungarian algorithm. The P2PNet not only significantly surpasses state-of-the-art methods on popular counting benchmarks, but also achieves promising localization accuracy. The codes will be available at: https://github.com/TencentYoutuResearch/CrowdCounting-P2PNet.
Uniformity in Heterogeneity:Diving Deep into Count Interval Partition for Crowd Counting
Aug 07, 2021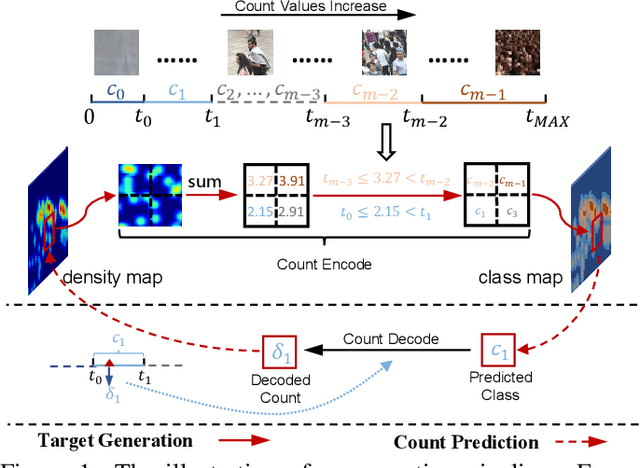
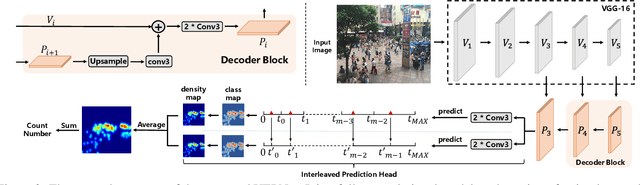
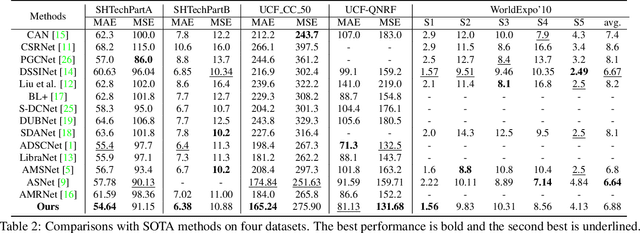
Recently, the problem of inaccurate learning targets in crowd counting draws increasing attention. Inspired by a few pioneering work, we solve this problem by trying to predict the indices of pre-defined interval bins of counts instead of the count values themselves. However, an inappropriate interval setting might make the count error contributions from different intervals extremely imbalanced, leading to inferior counting performance. Therefore, we propose a novel count interval partition criterion called Uniform Error Partition (UEP), which always keeps the expected counting error contributions equal for all intervals to minimize the prediction risk. Then to mitigate the inevitably introduced discretization errors in the count quantization process, we propose another criterion called Mean Count Proxies (MCP). The MCP criterion selects the best count proxy for each interval to represent its count value during inference, making the overall expected discretization error of an image nearly negligible. As far as we are aware, this work is the first to delve into such a classification task and ends up with a promising solution for count interval partition. Following the above two theoretically demonstrated criterions, we propose a simple yet effective model termed Uniform Error Partition Network (UEPNet), which achieves state-of-the-art performance on several challenging datasets. The codes will be available at: https://github.com/TencentYoutuResearch/CrowdCounting-UEPNet.
Adaptive Normalized Representation Learning for Generalizable Face Anti-Spoofing
Aug 05, 2021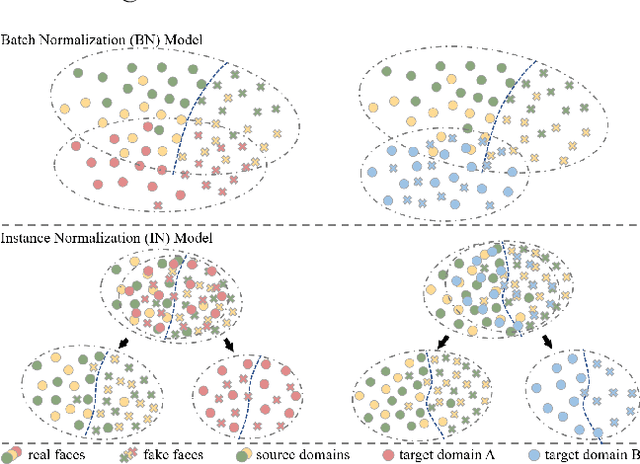
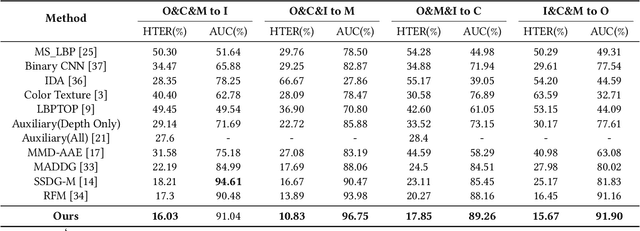
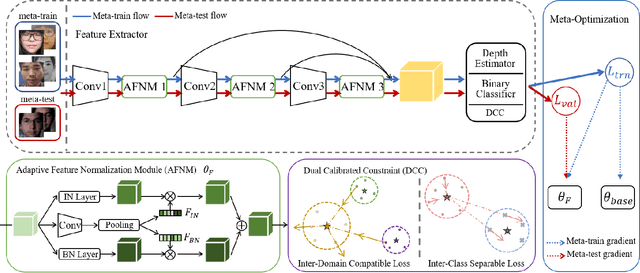
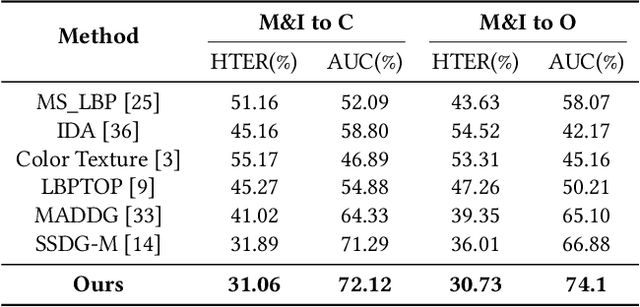
With various face presentation attacks arising under unseen scenarios, face anti-spoofing (FAS) based on domain generalization (DG) has drawn growing attention due to its robustness. Most existing methods utilize DG frameworks to align the features to seek a compact and generalized feature space. However, little attention has been paid to the feature extraction process for the FAS task, especially the influence of normalization, which also has a great impact on the generalization of the learned representation. To address this issue, we propose a novel perspective of face anti-spoofing that focuses on the normalization selection in the feature extraction process. Concretely, an Adaptive Normalized Representation Learning (ANRL) framework is devised, which adaptively selects feature normalization methods according to the inputs, aiming to learn domain-agnostic and discriminative representation. Moreover, to facilitate the representation learning, Dual Calibration Constraints are designed, including Inter-Domain Compatible loss and Inter-Class Separable loss, which provide a better optimization direction for generalizable representation. Extensive experiments and visualizations are presented to demonstrate the effectiveness of our method against the SOTA competitors.
Structure Destruction and Content Combination for Face Anti-Spoofing
Jul 22, 2021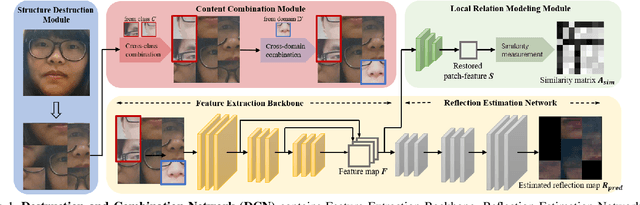
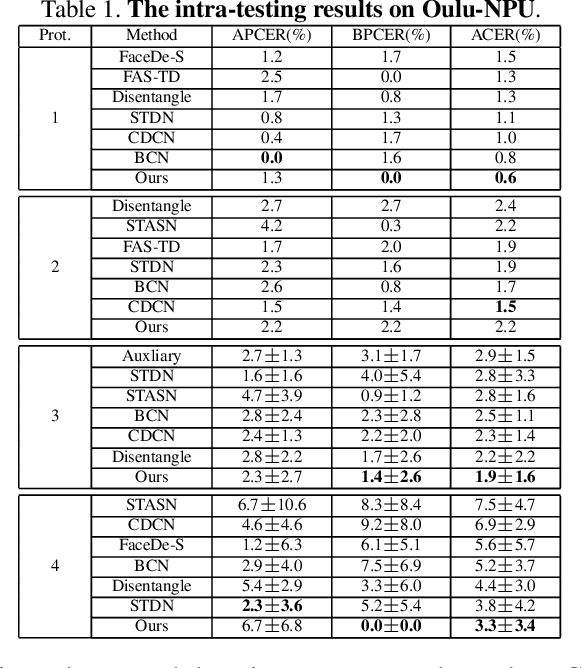
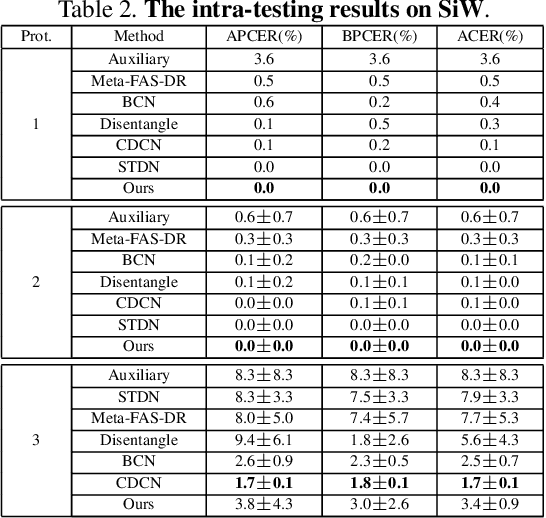

In pursuit of consolidating the face verification systems, prior face anti-spoofing studies excavate the hidden cues in original images to discriminate real persons and diverse attack types with the assistance of auxiliary supervision. However, limited by the following two inherent disturbances in their training process: 1) Complete facial structure in a single image. 2) Implicit subdomains in the whole dataset, these methods are prone to stick on memorization of the entire training dataset and show sensitivity to nonhomologous domain distribution. In this paper, we propose Structure Destruction Module and Content Combination Module to address these two imitations separately. The former mechanism destroys images into patches to construct a non-structural input, while the latter mechanism recombines patches from different subdomains or classes into a mixup construct. Based on this splitting-and-splicing operation, Local Relation Modeling Module is further proposed to model the second-order relationship between patches. We evaluate our method on extensive public datasets and promising experimental results to demonstrate the reliability of our method against state-of-the-art competitors.
Dual Reweighting Domain Generalization for Face Presentation Attack Detection
Jun 30, 2021
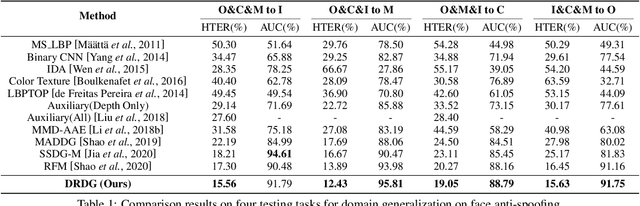
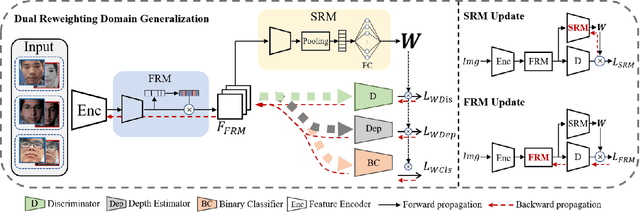
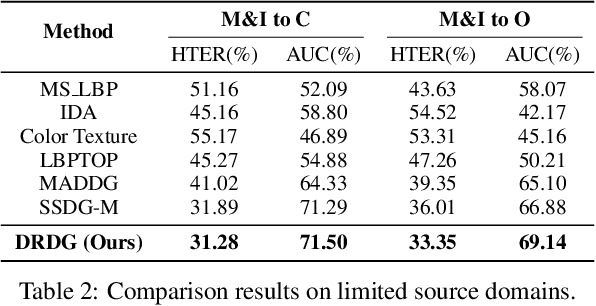
Face anti-spoofing approaches based on domain generalization (DG) have drawn growing attention due to their robustness for unseen scenarios. Previous methods treat each sample from multiple domains indiscriminately during the training process, and endeavor to extract a common feature space to improve the generalization. However, due to complex and biased data distribution, directly treating them equally will corrupt the generalization ability. To settle the issue, we propose a novel Dual Reweighting Domain Generalization (DRDG) framework which iteratively reweights the relative importance between samples to further improve the generalization. Concretely, Sample Reweighting Module is first proposed to identify samples with relatively large domain bias, and reduce their impact on the overall optimization. Afterwards, Feature Reweighting Module is introduced to focus on these samples and extract more domain-irrelevant features via a self-distilling mechanism. Combined with the domain discriminator, the iteration of the two modules promotes the extraction of generalized features. Extensive experiments and visualizations are presented to demonstrate the effectiveness and interpretability of our method against the state-of-the-art competitors.
HifiFace: 3D Shape and Semantic Prior Guided High Fidelity Face Swapping
Jun 18, 2021
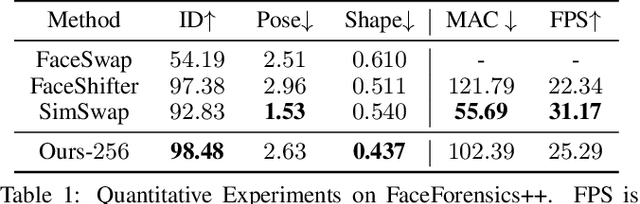
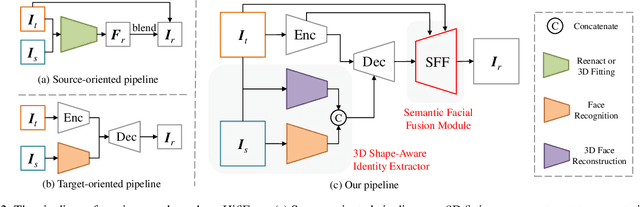
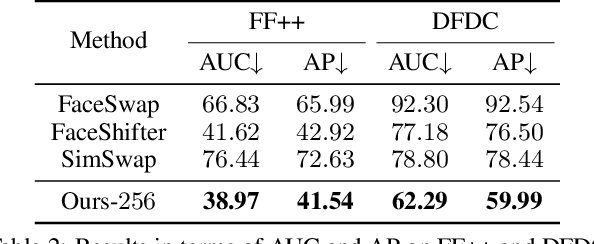
In this work, we propose a high fidelity face swapping method, called HifiFace, which can well preserve the face shape of the source face and generate photo-realistic results. Unlike other existing face swapping works that only use face recognition model to keep the identity similarity, we propose 3D shape-aware identity to control the face shape with the geometric supervision from 3DMM and 3D face reconstruction method. Meanwhile, we introduce the Semantic Facial Fusion module to optimize the combination of encoder and decoder features and make adaptive blending, which makes the results more photo-realistic. Extensive experiments on faces in the wild demonstrate that our method can preserve better identity, especially on the face shape, and can generate more photo-realistic results than previous state-of-the-art methods.
Adaptive Feature Alignment for Adversarial Training
Jun 16, 2021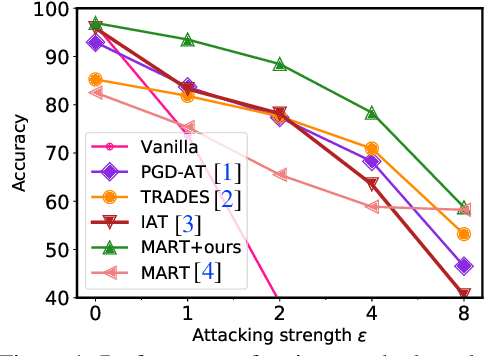
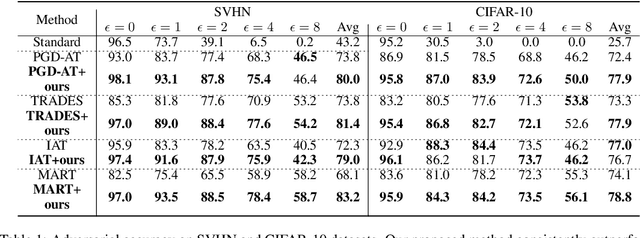
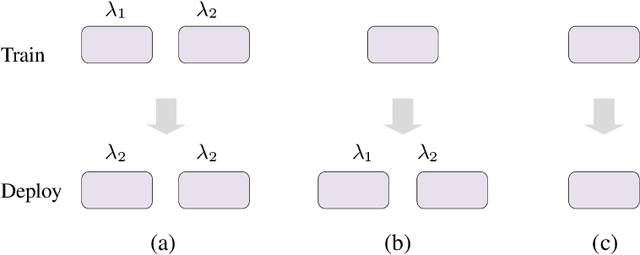
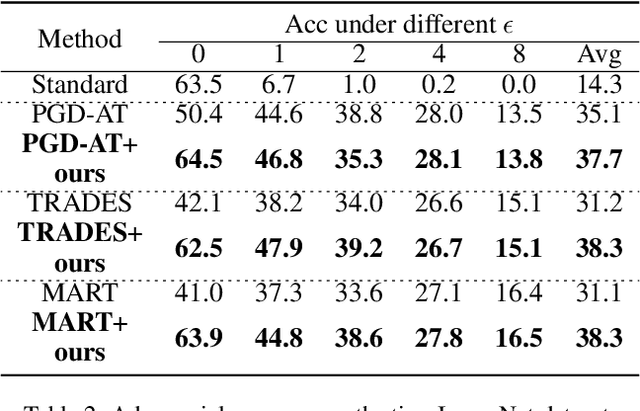
Recent studies reveal that Convolutional Neural Networks (CNNs) are typically vulnerable to adversarial attacks, which pose a threat to security-sensitive applications. Many adversarial defense methods improve robustness at the cost of accuracy, raising the contradiction between standard and adversarial accuracies. In this paper, we observe an interesting phenomenon that feature statistics change monotonically and smoothly w.r.t the rising of attacking strength. Based on this observation, we propose the adaptive feature alignment (AFA) to generate features of arbitrary attacking strengths. Our method is trained to automatically align features of arbitrary attacking strength. This is done by predicting a fusing weight in a dual-BN architecture. Unlike previous works that need to either retrain the model or manually tune a hyper-parameters for different attacking strengths, our method can deal with arbitrary attacking strengths with a single model without introducing any hyper-parameter. Importantly, our method improves the model robustness against adversarial samples without incurring much loss in standard accuracy. Experiments on CIFAR-10, SVHN, and tiny-ImageNet datasets demonstrate that our method outperforms the state-of-the-art under a wide range of attacking strengths.