 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing Improper Gaussian Signaling for Downlink Rate-Splitting Multiple Access with Imperfect Successive Interference Cancellation
Apr 16, 2026To mitigate the residual interference from imperfect successive interference cancellation (SIC) in Rate-Splitting Multiple Access (RSMA), this paper incorporates improper Gaussian signaling (IGS) into the downlink RSMA framework. Unlike existing RSMA--IGS works that embed impropriety within IQ-imbalanced frameworks, we show that IGS alone effectively counters SIC-induced residual interference. For a basic SISO setup with IGS on the common stream and PGS on private streams, we establish three key results: the optimal impropriety degree for private rate maximization attains its maximum; closed-form optimal solutions with rigorous monotonicity conditions are derived for common rate maximization; and a soft actor-critic (SAC) algorithm is developed for the non-convex sum rate problem. Numerical results show that IGS consistently outperforms PGS, with the gain widening as SIC imperfection increases.
Continuous Telemonitoring of Heart Failure using Personalised Speech Dynamics
Feb 25, 2026Remote monitoring of heart failure (HF) via speech signals provides a non-invasive and cost-effective solution for long-term patient management. However, substantial inter-individual heterogeneity in vocal characteristics often limits the accuracy of traditional cross-sectional classification models. To address this, we propose a Longitudinal Intra-Patient Tracking (LIPT) scheme designed to capture the trajectory of relative symptomatic changes within individuals. Central to this framework is a Personalised Sequential Encoder (PSE), which transforms longitudinal speech recordings into context-aware latent representations. By incorporating historical data at each timestamp, the PSE facilitates a holistic assessment of the clinical trajectory rather than modelling discrete visits independently. Experimental results from a cohort of 225 patients demonstrate that the LIPT paradigm significantly outperforms the classic cross-sectional approaches, achieving a recognition accuracy of 99.7% for clinical status transitions. The model's high sensitivity was further corroborated by additional follow-up data, confirming its efficacy in predicting HF deterioration and its potential to secure patient safety in remote, home-based settings. Furthermore, this work addresses the gap in existing literature by providing a comprehensive analysis of different speech task designs and acoustic features. Taken together, the superior performance of the LIPT framework and PSE architecture validates their readiness for integration into long-term telemonitoring systems, offering a scalable solution for remote heart failure management.
The HR-Calculus: Enabling Information Processing with Quaternion Algebra
Nov 28, 2023



From their inception, quaternions and their division algebra have proven to be advantageous in modelling rotation/orientation in three-dimensional spaces and have seen use from the initial formulation of electromagnetic filed theory through to forming the basis of quantum filed theory. Despite their impressive versatility in modelling real-world phenomena, adaptive information processing techniques specifically designed for quaternion-valued signals have only recently come to the attention of the machine learning, signal processing, and control communities. The most important development in this direction is introduction of the HR-calculus, which provides the required mathematical foundation for deriving adaptive information processing techniques directly in the quaternion domain. In this article, the foundations of the HR-calculus are revised and the required tools for deriving adaptive learning techniques suitable for dealing with quaternion-valued signals, such as the gradient operator, chain and product derivative rules, and Taylor series expansion are presented. This serves to establish the most important applications of adaptive information processing in the quaternion domain for both single-node and multi-node formulations. The article is supported by Supplementary Material, which will be referred to as SM.
Optimality of the Proper Gaussian Signal in Complex MIMO Wiretap Channels
Sep 28, 2022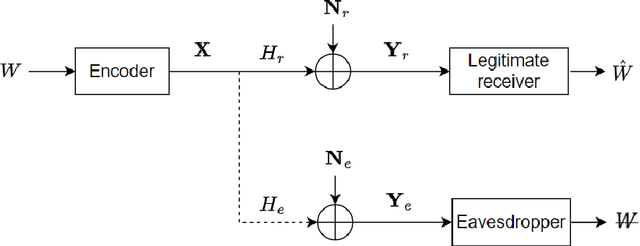
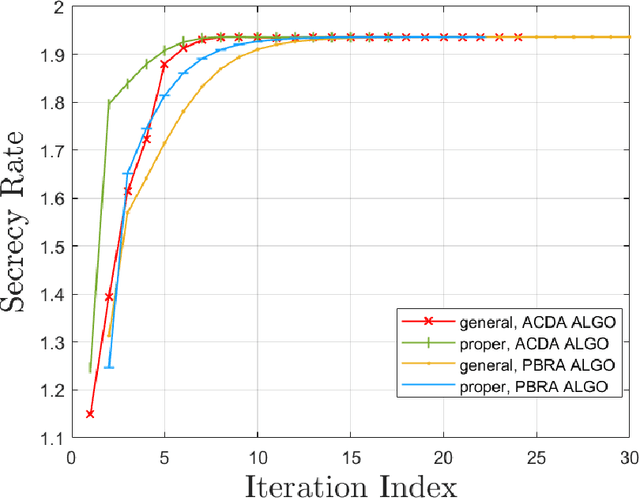
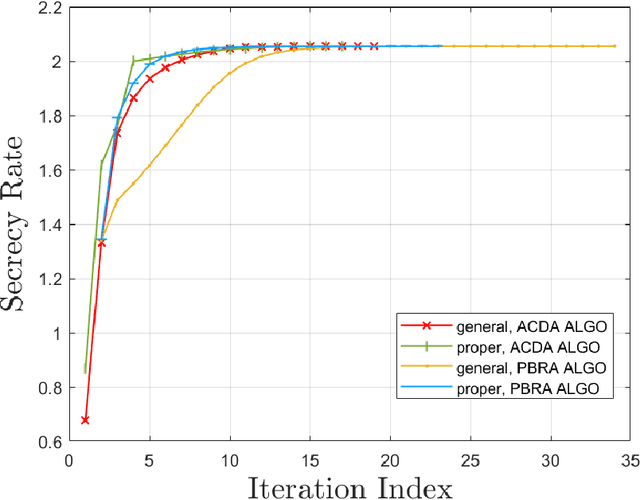
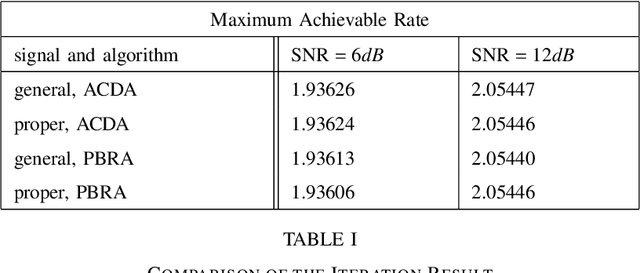
The multiple-input multiple-output (MIMO) wiretap channel (WTC), which has a transmitter, a legitimate user and an eavesdropper, is a classic model for studying information theoretic secrecy. In this paper, the fundamental problem for the complex WTC is whether the proper signal is optimal has yet to be given explicit proof, though previous work implicitly assumed the complex signal was proper. Thus, a determinant inequality is proposed to prove that the secrecy rate of a complex Gaussian signal with a fixed covariance matrix in a degraded complex WTC is maximized if and only if the signal is proper, i.e., the pseudo-covariance matrix is a zero matrix. Moreover, based on the result of the degraded complex WTC and the min-max reformulation of the secrecy capacity, the optimality of the proper signal in the general complex WTC is also revealed. The results of this research complement the current research on complex WTC. To be more specific, we have shown it is sufficient to focus on the proper signal when studying the secrecy capacity of the complex WTC.
ASFD: Automatic and Scalable Face Detector
Jan 26, 2022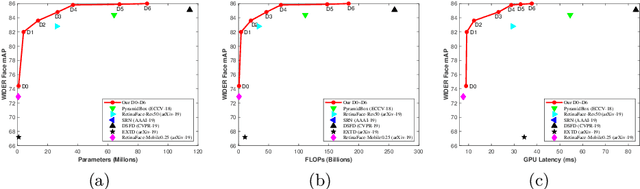

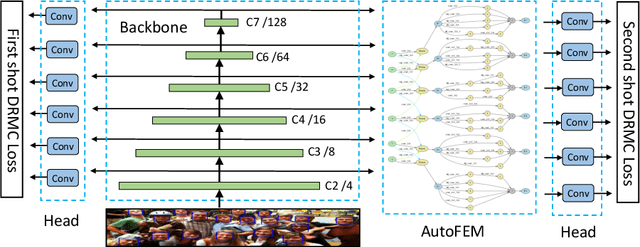
Along with current multi-scale based detectors, Feature Aggregation and Enhancement (FAE) modules have shown superior performance gains for cutting-edge object detection. However, these hand-crafted FAE modules show inconsistent improvements on face detection, which is mainly due to the significant distribution difference between its training and applying corpus, COCO vs. WIDER Face. To tackle this problem, we essentially analyse the effect of data distribution, and consequently propose to search an effective FAE architecture, termed AutoFAE by a differentiable architecture search, which outperforms all existing FAE modules in face detection with a considerable margin. Upon the found AutoFAE and existing backbones, a supernet is further built and trained, which automatically obtains a family of detectors under the different complexity constraints. Extensive experiments conducted on popular benchmarks, WIDER Face and FDDB, demonstrate the state-of-the-art performance-efficiency trade-off for the proposed automatic and scalable face detector (ASFD) family. In particular, our strong ASFD-D6 outperforms the best competitor with AP 96.7/96.2/92.1 on WIDER Face test, and the lightweight ASFD-D0 costs about 3.1 ms, more than 320 FPS, on the V100 GPU with VGA-resolution images.
ACFD: Asymmetric Cartoon Face Detector
Jul 02, 2020

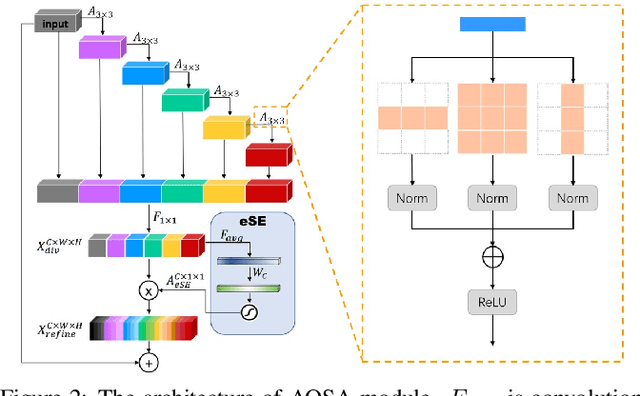

Cartoon face detection is a more challenging task than human face detection due to many difficult scenarios is involved. Aiming at the characteristics of cartoon faces, such as huge differences within the intra-faces, in this paper, we propose an asymmetric cartoon face detector, named ACFD. Specifically, it consists of the following modules: a novel backbone VoVNetV3 comprised of several asymmetric one-shot aggregation modules (AOSA), asymmetric bi-directional feature pyramid network (ABi-FPN), dynamic anchor match strategy (DAM) and the corresponding margin binary classification loss (MBC). In particular, to generate features with diverse receptive fields, multi-scale pyramid features are extracted by VoVNetV3, and then fused and enhanced simultaneously by ABi-FPN for handling the faces in some extreme poses and have disparate aspect ratios. Besides, DAM is used to match enough high-quality anchors for each face, and MBC is for the strong power of discrimination. With the effectiveness of these modules, our ACFD achieves the 1st place on the detection track of 2020 iCartoon Face Challenge under the constraints of model size 200MB, inference time 50ms per image, and without any pretrained models.
Attention Mechanism Enhanced Kernel Prediction Networks for Denoising of Burst Images
Oct 18, 2019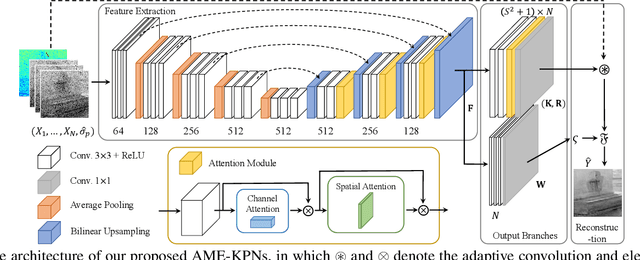
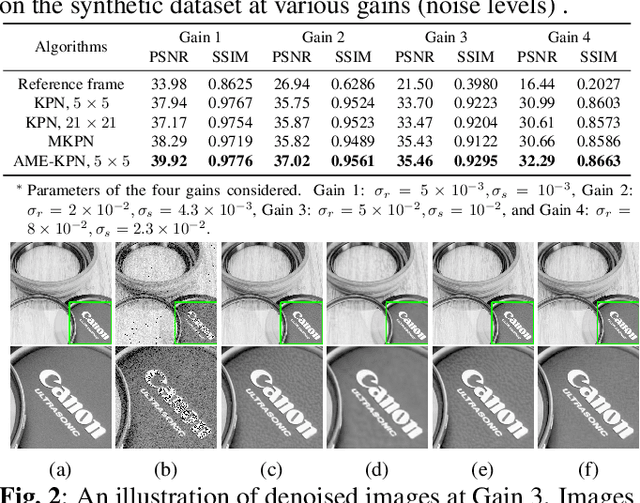
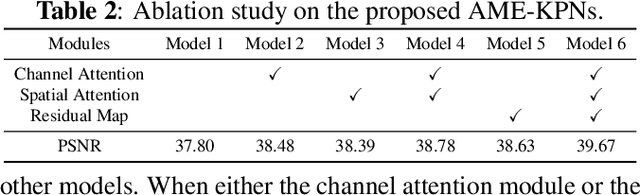
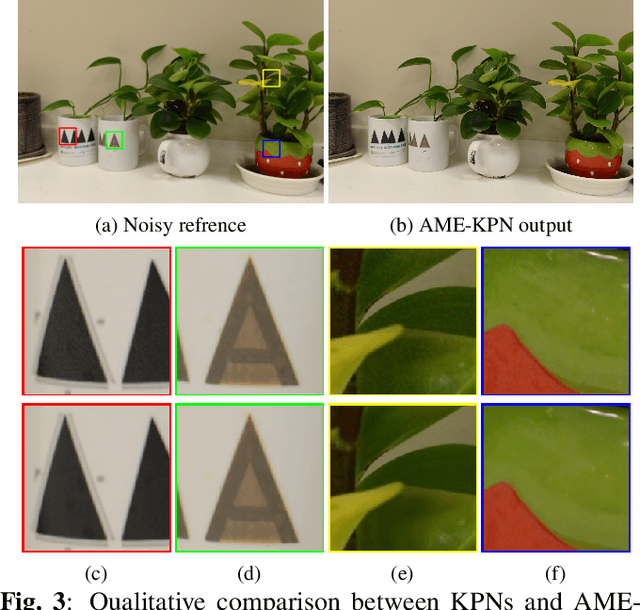
Deep learning based image denoising methods have been extensively investigated. In this paper, attention mechanism enhanced kernel prediction networks (AME-KPNs) are proposed for burst image denoising, in which, nearly cost-free attention modules are adopted to first refine the feature maps and to further make a full use of the inter-frame and intra-frame redundancies within the whole image burst. The proposed AME-KPNs output per-pixel spatially-adaptive kernels, residual maps and corresponding weight maps, in which, the predicted kernels roughly restore clean pixels at their corresponding locations via an adaptive convolution operation, and subsequently, residuals are weighted and summed to compensate the limited receptive field of predicted kernels. Simulations and real-world experiments are conducted to illustrate the robustness of the proposed AME-KPNs in burst image denoising.