 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Efficient Design of Learning System for Energy Demand Forecasting of Electrical Vehicles
Sep 04, 2023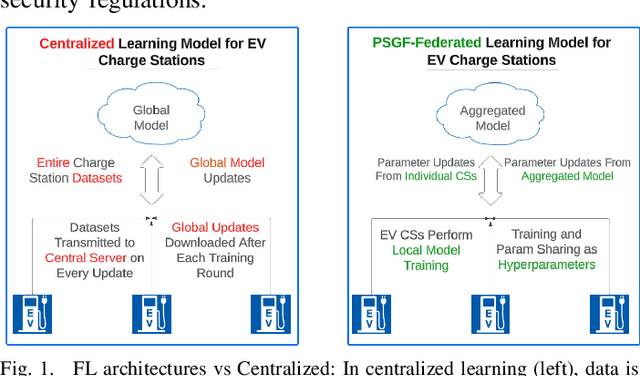
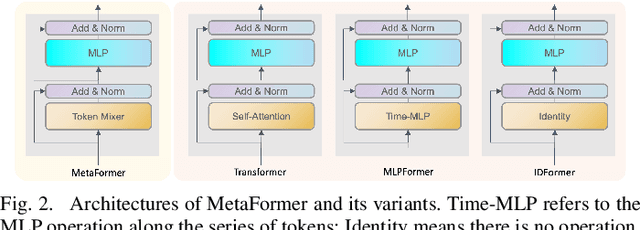

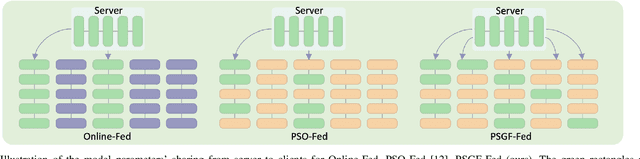
Machine learning (ML) applications to time series energy utilization forecasting problems are a challenging assignment due to a variety of factors. Chief among these is the non-homogeneity of the energy utilization datasets and the geographical dispersion of energy consumers. Furthermore, these ML models require vast amounts of training data and communications overhead in order to develop an effective model. In this paper, we propose a communication-efficient time series forecasting model combining the most recent advancements in transformer architectures implemented across a geographically dispersed series of EV charging stations and an efficient variant of federated learning (FL) to enable distributed training. The time series prediction performance and communication overhead cost of our FL are compared against their counterpart models and shown to have parity in performance while consuming significantly lower data rates during training. Additionally, the comparison is made across EV charging as well as other time series datasets to demonstrate the flexibility of our proposed model in generalized time series prediction beyond energy demand. The source code for this work is available at https://github.com/XuJiacong/LoGTST_PSGF
PIDNet: A Real-time Semantic Segmentation Network Inspired from PID Controller
Jun 04, 2022
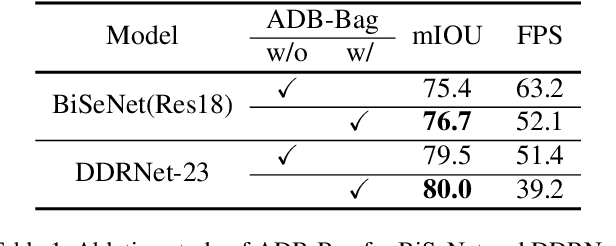


Two-branch network architecture has shown its efficiency and effectiveness for real-time semantic segmentation tasks. However, direct fusion of low-level details and high-level semantics will lead to a phenomenon that the detailed features are easily overwhelmed by surrounding contextual information, namely overshoot in this paper, which limits the improvement of the accuracy of existed two-branch models. In this paper, we bridge a connection between Convolutional Neural Network (CNN) and Proportional-Integral-Derivative (PID) controller and reveal that the two-branch network is nothing but a Proportional-Integral (PI) controller, which inherently suffers from the similar overshoot issue. To alleviate this issue, we propose a novel three-branch network architecture: PIDNet, which possesses three branches to parse the detailed, context and boundary information (derivative of semantics), respectively, and employs boundary attention to guide the fusion of detailed and context branches in final stage. The family of PIDNets achieve the best trade-off between inference speed and accuracy and their test accuracy surpasses all the existed models with similar inference speed on Cityscapes, CamVid and COCO-Stuff datasets. Especially, PIDNet-S achieves 78.6% mIOU with inference speed of 93.2 FPS on Cityscapes test set and 81.6% mIOU with speed of 153.7 FPS on CamVid test set.
An Unsupervised Attentive-Adversarial Learning Framework for Single Image Deraining
Feb 19, 2022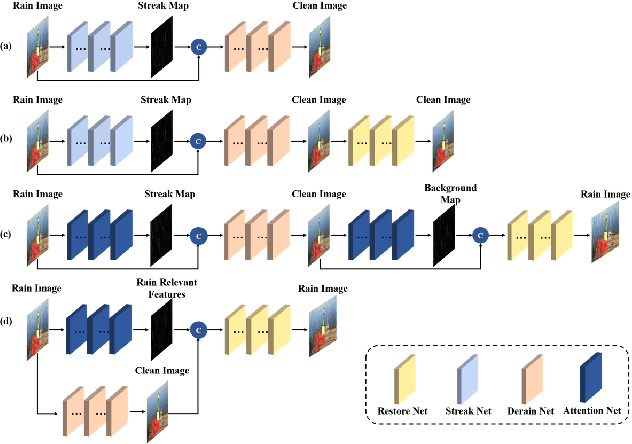



Single image deraining has been an important topic in low-level computer vision tasks. The atmospheric veiling effect (which is generated by rain accumulation, similar to fog) usually appears with the rain. Most deep learning-based single image deraining methods mainly focus on rain streak removal by disregarding this effect, which leads to low-quality deraining performance. In addition, these methods are trained only on synthetic data, hence they do not take into account real-world rainy images. To address the above issues, we propose a novel unsupervised attentive-adversarial learning framework (UALF) for single image deraining that trains on both synthetic and real rainy images while simultaneously capturing both rain streaks and rain accumulation features. UALF consists of a Rain-fog2Clean (R2C) transformation block and a Clean2Rain-fog (C2R) transformation block. In R2C, to better characterize the rain-fog fusion feature and to achieve high-quality deraining performance, we employ an attention rain-fog feature extraction network (ARFE) to exploit the self-similarity of global and local rain-fog information by learning the spatial feature correlations. Moreover, to improve the transformation ability of C2R, we design a rain-fog feature decoupling and reorganization network (RFDR) by embedding a rainy image degradation model and a mixed discriminator to preserve richer texture details. Extensive experiments on benchmark rain-fog and rain datasets show that UALF outperforms state-of-the-art deraining methods. We also conduct defogging performance evaluation experiments to further demonstrate the effectiveness of UALF
Holistic Attention-Fusion Adversarial Network for Single Image Defogging
Feb 19, 2022



Adversarial learning-based image defogging methods have been extensively studied in computer vision due to their remarkable performance. However, most existing methods have limited defogging capabilities for real cases because they are trained on the paired clear and synthesized foggy images of the same scenes. In addition, they have limitations in preserving vivid color and rich textual details in defogging. To address these issues, we develop a novel generative adversarial network, called holistic attention-fusion adversarial network (HAAN), for single image defogging. HAAN consists of a Fog2Fogfree block and a Fogfree2Fog block. In each block, there are three learning-based modules, namely, fog removal, color-texture recovery, and fog synthetic, that are constrained each other to generate high quality images. HAAN is designed to exploit the self-similarity of texture and structure information by learning the holistic channel-spatial feature correlations between the foggy image with its several derived images. Moreover, in the fog synthetic module, we utilize the atmospheric scattering model to guide it to improve the generative quality by focusing on an atmospheric light optimization with a novel sky segmentation network. Extensive experiments on both synthetic and real-world datasets show that HAAN outperforms state-of-the-art defogging methods in terms of quantitative accuracy and subjective visual quality.
Peeking into occluded joints: A novel framework for crowd pose estimation
Mar 31, 2020



Although occlusion widely exists in nature and remains a fundamental challenge for pose estimation, existing heatmap-based approaches suffer serious degradation on occlusions. Their intrinsic problem is that they directly localize the joints based on visual information; however, the invisible joints are lack of that. In contrast to localization, our framework estimates the invisible joints from an inference perspective by proposing an Image-Guided Progressive GCN module which provides a comprehensive understanding of both image context and pose structure. Moreover, existing benchmarks contain limited occlusions for evaluation. Therefore, we thoroughly pursue this problem and propose a novel OPEC-Net framework together with a new Occluded Pose (OCPose) dataset with 9k annotated images. Extensive quantitative and qualitative evaluations on benchmarks demonstrate that OPEC-Net achieves significant improvements over recent leading works. Notably, our OCPose is the most complex occlusion dataset with respect to average IoU between adjacent instances. Source code and OCPose will be publicly available.
Learning Inverse Rendering of Faces from Real-world Videos
Mar 26, 2020
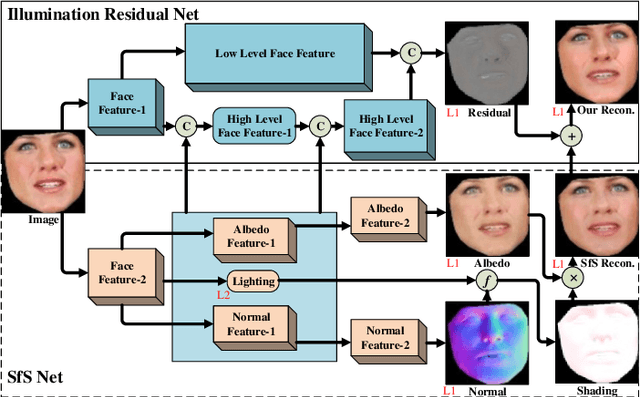

In this paper we examine the problem of inverse rendering of real face images. Existing methods decompose a face image into three components (albedo, normal, and illumination) by supervised training on synthetic face data. However, due to the domain gap between real and synthetic face images, a model trained on synthetic data often does not generalize well to real data. Meanwhile, since no ground truth for any component is available for real images, it is not feasible to conduct supervised learning on real face images. To alleviate this problem, we propose a weakly supervised training approach to train our model on real face videos, based on the assumption of consistency of albedo and normal across different frames, thus bridging the gap between real and synthetic face images. In addition, we introduce a learning framework, called IlluRes-SfSNet, to further extract the residual map to capture the global illumination effects that give the fine details that are largely ignored in existing methods. Our network is trained on both real and synthetic data, benefiting from both. We comprehensively evaluate our methods on various benchmarks, obtaining better inverse rendering results than the state-of-the-art.
Attention Mechanism Enhanced Kernel Prediction Networks for Denoising of Burst Images
Oct 18, 2019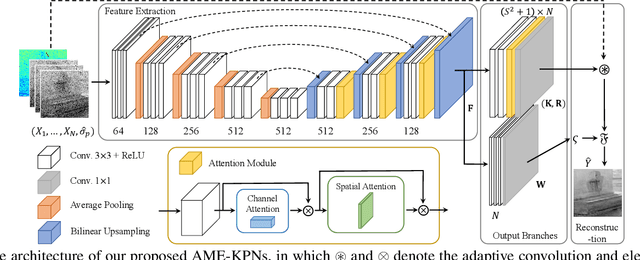
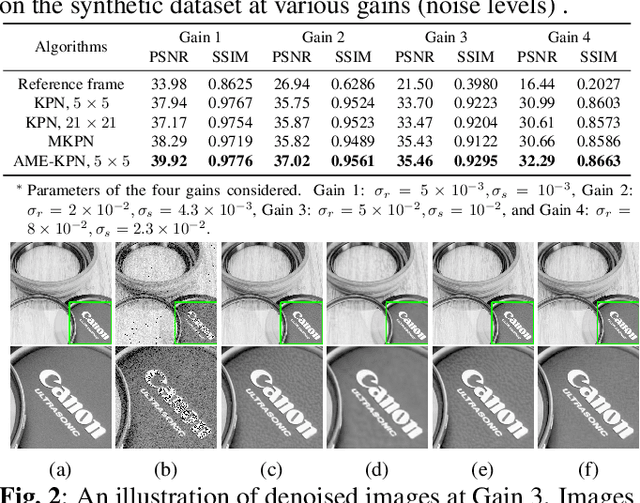
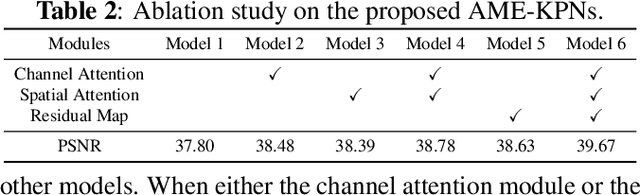
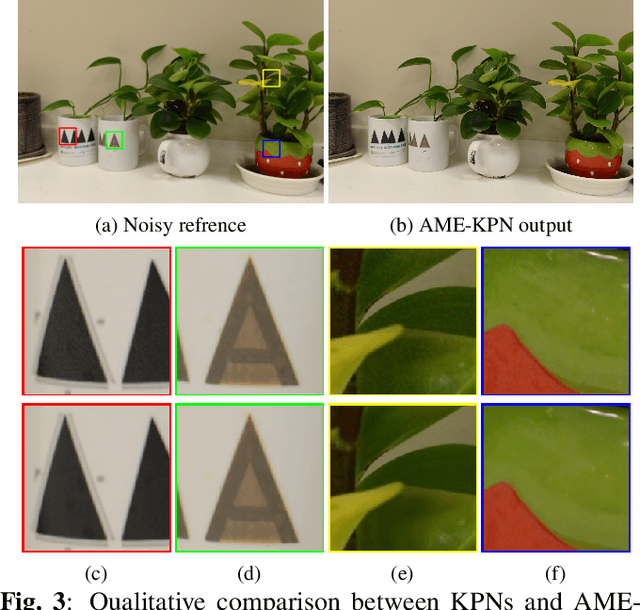
Deep learning based image denoising methods have been extensively investigated. In this paper, attention mechanism enhanced kernel prediction networks (AME-KPNs) are proposed for burst image denoising, in which, nearly cost-free attention modules are adopted to first refine the feature maps and to further make a full use of the inter-frame and intra-frame redundancies within the whole image burst. The proposed AME-KPNs output per-pixel spatially-adaptive kernels, residual maps and corresponding weight maps, in which, the predicted kernels roughly restore clean pixels at their corresponding locations via an adaptive convolution operation, and subsequently, residuals are weighted and summed to compensate the limited receptive field of predicted kernels. Simulations and real-world experiments are conducted to illustrate the robustness of the proposed AME-KPNs in burst image denoising.
Deep Reinforcement Learning of Volume-guided Progressive View Inpainting for 3D Point Scene Completion from a Single Depth Image
Mar 12, 2019

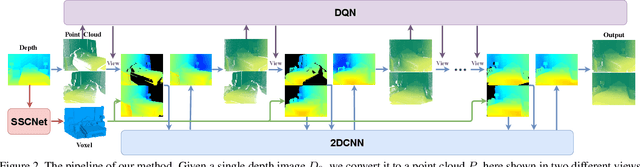

We present a deep reinforcement learning method of progressive view inpainting for 3D point scene completion under volume guidance, achieving high-quality scene reconstruction from only a single depth image with severe occlusion. Our approach is end-to-end, consisting of three modules: 3D scene volume reconstruction, 2D depth map inpainting, and multi-view selection for completion. Given a single depth image, our method first goes through the 3D volume branch to obtain a volumetric scene reconstruction as a guide to the next view inpainting step, which attempts to make up the missing information; the third step involves projecting the volume under the same view of the input, concatenating them to complete the current view depth, and integrating all depth into the point cloud. Since the occluded areas are unavailable, we resort to a deep Q-Network to glance around and pick the next best view for large hole completion progressively until a scene is adequately reconstructed while guaranteeing validity. All steps are learned jointly to achieve robust and consistent results. We perform qualitative and quantitative evaluations with extensive experiments on the SUNCG data, obtaining better results than the state of the art.
Learning Mutually Local-global U-nets For High-resolution Retinal Lesion Segmentation in Fundus Images
Jan 18, 2019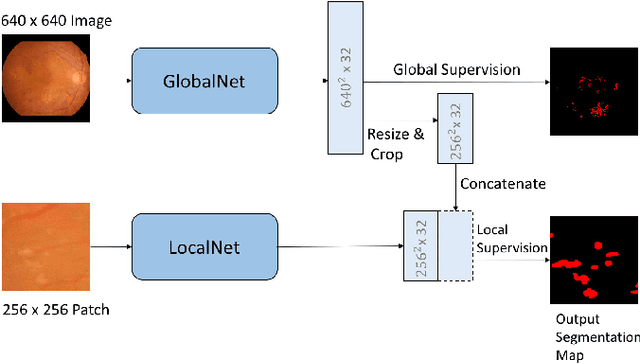
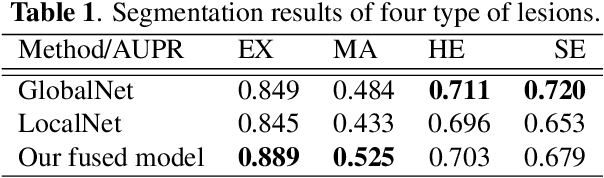


Diabetic retinopathy is the most important complication of diabetes. Early diagnosis of retinal lesions helps to avoid visual loss or blindness. Due to high-resolution and small-size lesion regions, applying existing methods, such as U-Nets, to perform segmentation on fundus photography is very challenging. Although downsampling the input images could simplify the problem, it loses detailed information. Conducting patch-level analysis helps reaching fine-scale segmentation yet usually leads to misunderstanding as the lack of context information. In this paper, we propose an efficient network that combines them together, not only being aware of local details but also taking fully use of the context perceptions. This is implemented by integrating the decoder parts of a global-level U-net and a patch-level one. The two streams are jointly optimized, ensuring that they are enhanced mutually. Experimental results demonstrate our new framework significantly outperforms existing patch-based and global-based methods, especially when the lesion regions are scattered and small-scaled.