 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Inverse Rendering of Faces from Real-world Videos
Paper and Code

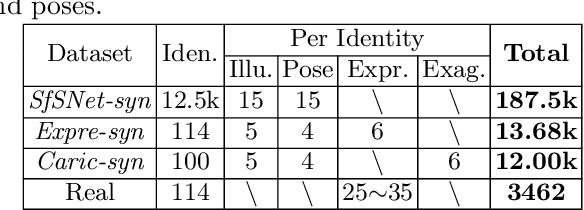
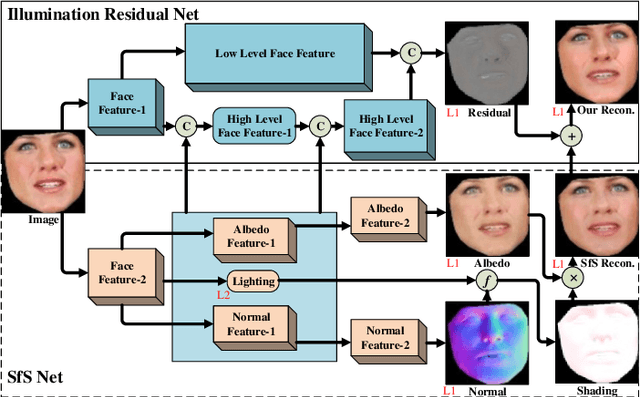

In this paper we examine the problem of inverse rendering of real face images. Existing methods decompose a face image into three components (albedo, normal, and illumination) by supervised training on synthetic face data. However, due to the domain gap between real and synthetic face images, a model trained on synthetic data often does not generalize well to real data. Meanwhile, since no ground truth for any component is available for real images, it is not feasible to conduct supervised learning on real face images. To alleviate this problem, we propose a weakly supervised training approach to train our model on real face videos, based on the assumption of consistency of albedo and normal across different frames, thus bridging the gap between real and synthetic face images. In addition, we introduce a learning framework, called IlluRes-SfSNet, to further extract the residual map to capture the global illumination effects that give the fine details that are largely ignored in existing methods. Our network is trained on both real and synthetic data, benefiting from both. We comprehensively evaluate our methods on various benchmarks, obtaining better inverse rendering results than the state-of-the-art.