 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVHumanNet: A Large-scale Dataset of Multi-view Daily Dressing Human Captures
Dec 05, 2023
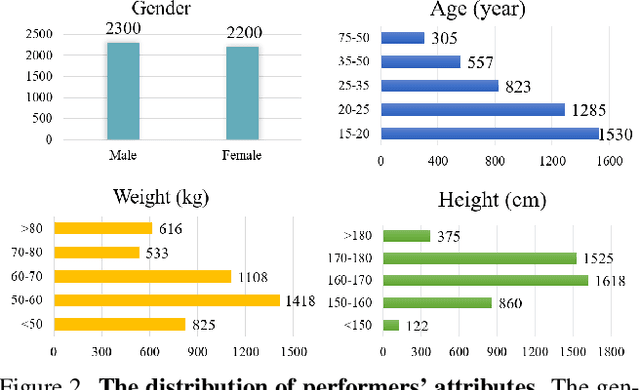
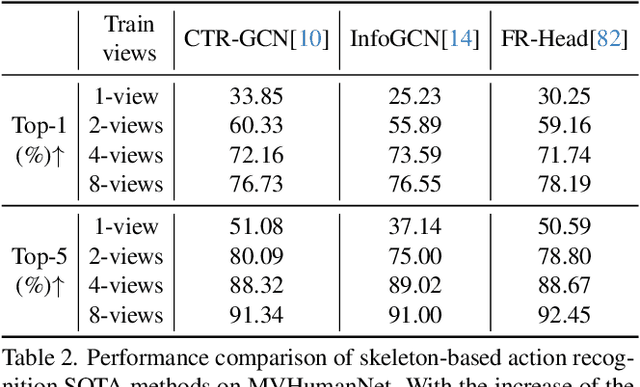

In this era, the success of large language models and text-to-image models can be attributed to the driving force of large-scale datasets. However, in the realm of 3D vision, while remarkable progress has been made with models trained on large-scale synthetic and real-captured object data like Objaverse and MVImgNet, a similar level of progress has not been observed in the domain of human-centric tasks partially due to the lack of a large-scale human dataset. Existing datasets of high-fidelity 3D human capture continue to be mid-sized due to the significant challenges in acquiring large-scale high-quality 3D human data. To bridge this gap, we present MVHumanNet, a dataset that comprises multi-view human action sequences of 4,500 human identities. The primary focus of our work is on collecting human data that features a large number of diverse identities and everyday clothing using a multi-view human capture system, which facilitates easily scalable data collection. Our dataset contains 9,000 daily outfits, 60,000 motion sequences and 645 million frames with extensive annotations, including human masks, camera parameters, 2D and 3D keypoints, SMPL/SMPLX parameters, and corresponding textual descriptions. To explore the potential of MVHumanNet in various 2D and 3D visual tasks, we conducted pilot studies on view-consistent action recognition, human NeRF reconstruction, text-driven view-unconstrained human image generation, as well as 2D view-unconstrained human image and 3D avatar generation. Extensive experiments demonstrate the performance improvements and effective applications enabled by the scale provided by MVHumanNet. As the current largest-scale 3D human dataset, we hope that the release of MVHumanNet data with annotations will foster further innovations in the domain of 3D human-centric tasks at scale.
MVImgNet: A Large-scale Dataset of Multi-view Images
Mar 10, 2023



Being data-driven is one of the most iconic properties of deep learning algorithms. The birth of ImageNet drives a remarkable trend of "learning from large-scale data" in computer vision. Pretraining on ImageNet to obtain rich universal representations has been manifested to benefit various 2D visual tasks, and becomes a standard in 2D vision. However, due to the laborious collection of real-world 3D data, there is yet no generic dataset serving as a counterpart of ImageNet in 3D vision, thus how such a dataset can impact the 3D community is unraveled. To remedy this defect, we introduce MVImgNet, a large-scale dataset of multi-view images, which is highly convenient to gain by shooting videos of real-world objects in human daily life. It contains 6.5 million frames from 219,188 videos crossing objects from 238 classes, with rich annotations of object masks, camera parameters, and point clouds. The multi-view attribute endows our dataset with 3D-aware signals, making it a soft bridge between 2D and 3D vision. We conduct pilot studies for probing the potential of MVImgNet on a variety of 3D and 2D visual tasks, including radiance field reconstruction, multi-view stereo, and view-consistent image understanding, where MVImgNet demonstrates promising performance, remaining lots of possibilities for future explorations. Besides, via dense reconstruction on MVImgNet, a 3D object point cloud dataset is derived, called MVPNet, covering 87,200 samples from 150 categories, with the class label on each point cloud. Experiments show that MVPNet can benefit the real-world 3D object classification while posing new challenges to point cloud understanding. MVImgNet and MVPNet will be publicly available, hoping to inspire the broader vision community.
Get3DHuman: Lifting StyleGAN-Human into a 3D Generative Model using Pixel-aligned Reconstruction Priors
Feb 11, 2023Fast generation of high-quality 3D digital humans is important to a vast number of applications ranging from entertainment to professional concerns. Recent advances in differentiable rendering have enabled the training of 3D generative models without requiring 3D ground truths. However, the quality of the generated 3D humans still has much room to improve in terms of both fidelity and diversity. In this paper, we present Get3DHuman, a novel 3D human framework that can significantly boost the realism and diversity of the generated outcomes by only using a limited budget of 3D ground-truth data. Our key observation is that the 3D generator can profit from human-related priors learned through 2D human generators and 3D reconstructors. Specifically, we bridge the latent space of Get3DHuman with that of StyleGAN-Human via a specially-designed prior network, where the input latent code is mapped to the shape and texture feature volumes spanned by the pixel-aligned 3D reconstructor. The outcomes of the prior network are then leveraged as the supervisory signals for the main generator network. To ensure effective training, we further propose three tailored losses applied to the generated feature volumes and the intermediate feature maps. Extensive experiments demonstrate that Get3DHuman greatly outperforms the other state-of-the-art approaches and can support a wide range of applications including shape interpolation, shape re-texturing, and single-view reconstruction through latent inversion.
PIFu for the Real World: A Self-supervised Framework to Reconstruct Dressed Human from Single-view Images
Aug 23, 2022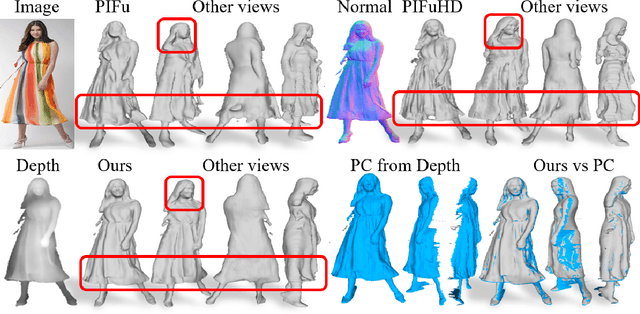
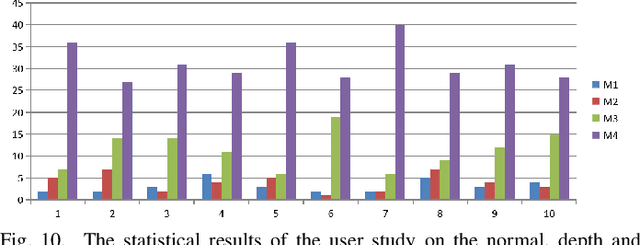
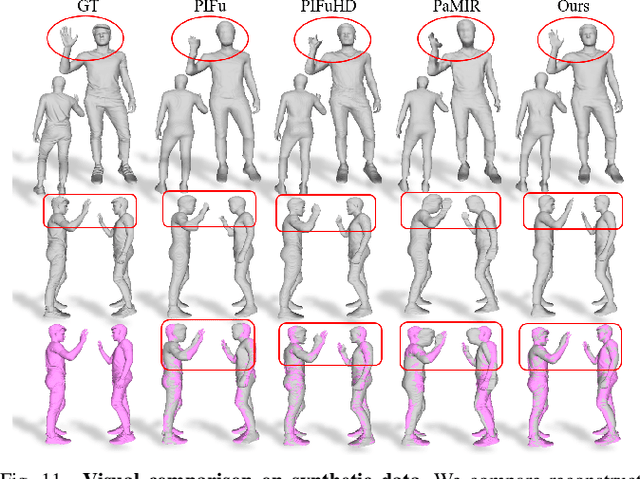
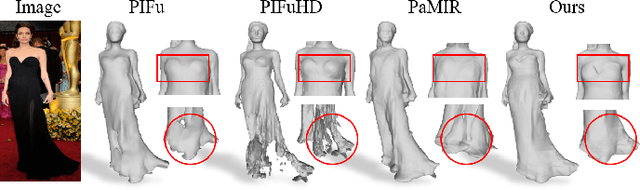
It is very challenging to accurately reconstruct sophisticated human geometry caused by various poses and garments from a single image. Recently, works based on pixel-aligned implicit function (PIFu) have made a big step and achieved state-of-the-art fidelity on image-based 3D human digitization. However, the training of PIFu relies heavily on expensive and limited 3D ground truth data (i.e. synthetic data), thus hindering its generalization to more diverse real world images. In this work, we propose an end-to-end self-supervised network named SelfPIFu to utilize abundant and diverse in-the-wild images, resulting in largely improved reconstructions when tested on unconstrained in-the-wild images. At the core of SelfPIFu is the depth-guided volume-/surface-aware signed distance fields (SDF) learning, which enables self-supervised learning of a PIFu without access to GT mesh. The whole framework consists of a normal estimator, a depth estimator, and a SDF-based PIFu and better utilizes extra depth GT during training. Extensive experiments demonstrate the effectiveness of our self-supervised framework and the superiority of using depth as input. On synthetic data, our Intersection-Over-Union (IoU) achieves to 93.5%, 18% higher compared with PIFuHD. For in-the-wild images, we conduct user studies on the reconstructed results, the selection rate of our results is over 68% compared with other state-of-the-art methods.
Learning Inverse Rendering of Faces from Real-world Videos
Mar 26, 2020
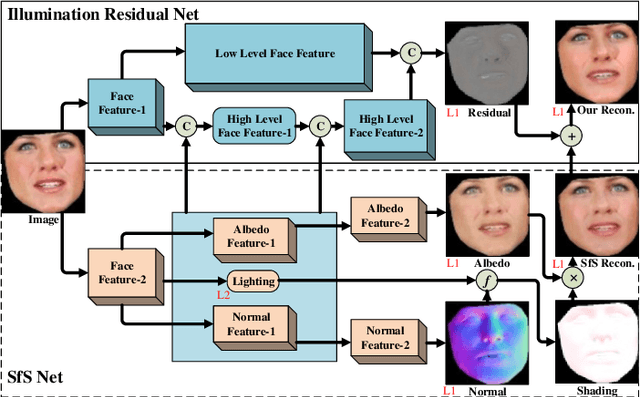

In this paper we examine the problem of inverse rendering of real face images. Existing methods decompose a face image into three components (albedo, normal, and illumination) by supervised training on synthetic face data. However, due to the domain gap between real and synthetic face images, a model trained on synthetic data often does not generalize well to real data. Meanwhile, since no ground truth for any component is available for real images, it is not feasible to conduct supervised learning on real face images. To alleviate this problem, we propose a weakly supervised training approach to train our model on real face videos, based on the assumption of consistency of albedo and normal across different frames, thus bridging the gap between real and synthetic face images. In addition, we introduce a learning framework, called IlluRes-SfSNet, to further extract the residual map to capture the global illumination effects that give the fine details that are largely ignored in existing methods. Our network is trained on both real and synthetic data, benefiting from both. We comprehensively evaluate our methods on various benchmarks, obtaining better inverse rendering results than the state-of-the-art.
Masked Face Recognition Dataset and Application
Mar 23, 2020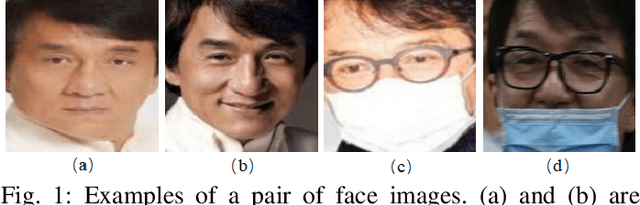
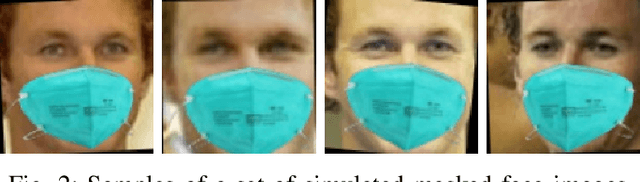
In order to effectively prevent the spread of COVID-19 virus, almost everyone wears a mask during coronavirus epidemic. This almost makes conventional facial recognition technology ineffective in many cases, such as community access control, face access control, facial attendance, facial security checks at train stations, etc. Therefore, it is very urgent to improve the recognition performance of the existing face recognition technology on the masked faces. Most current advanced face recognition approaches are designed based on deep learning, which depend on a large number of face samples. However, at present, there are no publicly available masked face recognition datasets. To this end, this work proposes three types of masked face datasets, including Masked Face Detection Dataset (MFDD), Real-world Masked Face Recognition Dataset (RMFRD) and Simulated Masked Face Recognition Dataset (SMFRD). Among them, to the best of our knowledge, RMFRD is currently theworld's largest real-world masked face dataset. These datasets are freely available to industry and academia, based on which various applications on masked faces can be developed. The multi-granularity masked face recognition model we developed achieves 95% accuracy, exceeding the results reported by the industry. Our datasets are available at: https://github.com/X-zhangyang/Real-World-Masked-Face-Dataset.