 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3DHMR: Monocular 3D Hand Mesh Recovery
May 26, 2025Monocular 3D hand mesh recovery is challenging due to high degrees of freedom of hands, 2D-to-3D ambiguity and self-occlusion. Most existing methods are either inefficient or less straightforward for predicting the position of 3D mesh vertices. Thus, we propose a new pipeline called Monocular 3D Hand Mesh Recovery (M3DHMR) to directly estimate the positions of hand mesh vertices. M3DHMR provides 2D cues for 3D tasks from a single image and uses a new spiral decoder consist of several Dynamic Spiral Convolution (DSC) Layers and a Region of Interest (ROI) Layer. On the one hand, DSC Layers adaptively adjust the weights based on the vertex positions and extract the vertex features in both spatial and channel dimensions. On the other hand, ROI Layer utilizes the physical information and refines mesh vertices in each predefined hand region separately. Extensive experiments on popular dataset FreiHAND demonstrate that M3DHMR significantly outperforms state-of-the-art real-time methods.
EmoFace: Emotion-Content Disentangled Speech-Driven 3D Talking Face with Mesh Attention
Aug 21, 2024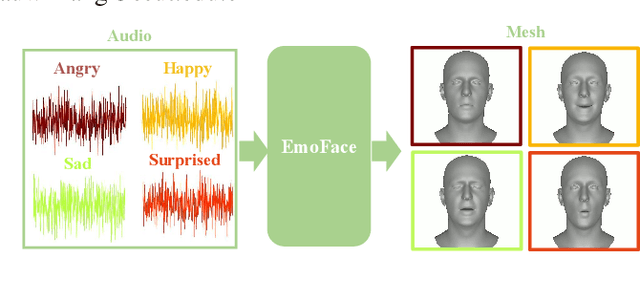
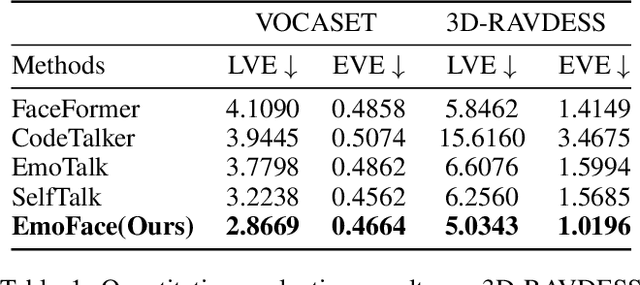
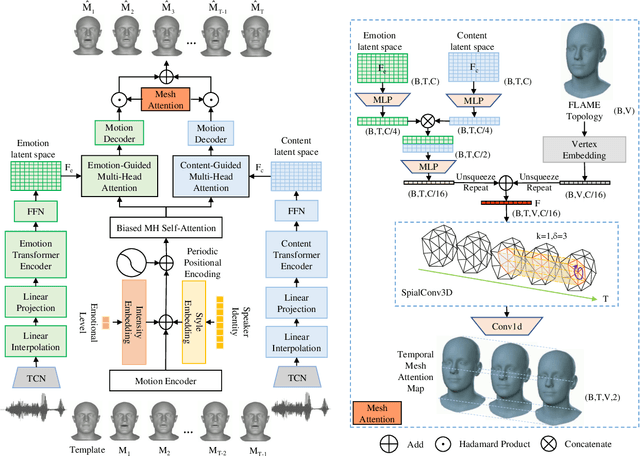

The creation of increasingly vivid 3D virtual digital humans has become a hot topic in recent years. Currently, most speech-driven work focuses on training models to learn the relationship between phonemes and visemes to achieve more realistic lips. However, they fail to capture the correlations between emotions and facial expressions effectively. To solve this problem, we propose a new model, termed EmoFace. EmoFace employs a novel Mesh Attention mechanism, which helps to learn potential feature dependencies between mesh vertices in time and space. We also adopt, for the first time to our knowledge, an effective self-growing training scheme that combines teacher-forcing and scheduled sampling in a 3D face animation task. Additionally, since EmoFace is an autoregressive model, there is no requirement that the first frame of the training data must be a silent frame, which greatly reduces the data limitations and contributes to solve the current dilemma of insufficient datasets. Comprehensive quantitative and qualitative evaluations on our proposed high-quality reconstructed 3D emotional facial animation dataset, 3D-RAVDESS ($5.0343\times 10^{-5}$mm for LVE and $1.0196\times 10^{-5}$mm for EVE), and publicly available dataset VOCASET ($2.8669\times 10^{-5}$mm for LVE and $0.4664\times 10^{-5}$mm for EVE), demonstrate that our algorithm achieves state-of-the-art performance.
MVHumanNet: A Large-scale Dataset of Multi-view Daily Dressing Human Captures
Dec 05, 2023
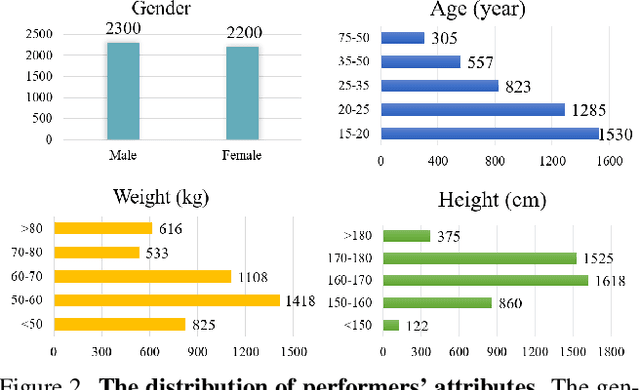
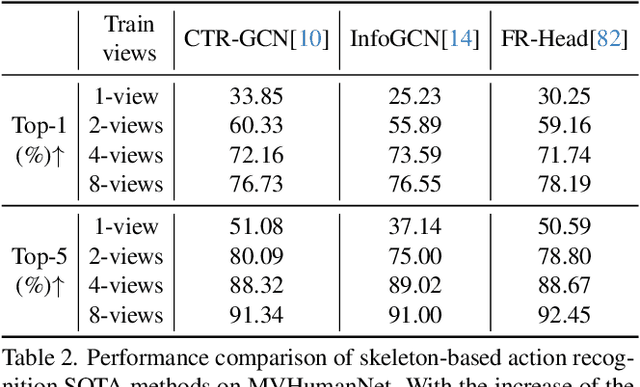

In this era, the success of large language models and text-to-image models can be attributed to the driving force of large-scale datasets. However, in the realm of 3D vision, while remarkable progress has been made with models trained on large-scale synthetic and real-captured object data like Objaverse and MVImgNet, a similar level of progress has not been observed in the domain of human-centric tasks partially due to the lack of a large-scale human dataset. Existing datasets of high-fidelity 3D human capture continue to be mid-sized due to the significant challenges in acquiring large-scale high-quality 3D human data. To bridge this gap, we present MVHumanNet, a dataset that comprises multi-view human action sequences of 4,500 human identities. The primary focus of our work is on collecting human data that features a large number of diverse identities and everyday clothing using a multi-view human capture system, which facilitates easily scalable data collection. Our dataset contains 9,000 daily outfits, 60,000 motion sequences and 645 million frames with extensive annotations, including human masks, camera parameters, 2D and 3D keypoints, SMPL/SMPLX parameters, and corresponding textual descriptions. To explore the potential of MVHumanNet in various 2D and 3D visual tasks, we conducted pilot studies on view-consistent action recognition, human NeRF reconstruction, text-driven view-unconstrained human image generation, as well as 2D view-unconstrained human image and 3D avatar generation. Extensive experiments demonstrate the performance improvements and effective applications enabled by the scale provided by MVHumanNet. As the current largest-scale 3D human dataset, we hope that the release of MVHumanNet data with annotations will foster further innovations in the domain of 3D human-centric tasks at scale.