 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSRENet: Spectral Re-Entry Network for Point Cloud Action Recognition
Jun 02, 2026Recognizing human actions from point cloud sequences is critical for 3D perception driven applications such as autonomous driving and human-computer interaction. However, the irregular structure and temporal inconsistency of point clouds pose unique challenges for spatio-temporal representation learning, especially in capturing both global motion context and fine-grained temporal dynamics. We propose SRENet, a spectral-aware framework designed to explicitly learn both global context and fine-grained temporal dynamics of motion from a frequency perspective for action recognition. SRENet introduces a Spectral Decomposition Block (SDeBlock) that performs wavelet-based analysis along temporal and spatial axes, disentangling features into low- and high-frequency components with frequency-specific attention. To recover residual dynamics and re-align temporal frequency structures distorted during semantic fusion, a Spectral Re-entry Block (SReBlock) performs secondary temporal decomposition. Furthermore, a spectral-aware learning strategy is devised to enhance discriminability in both frequency subspaces via contrastive loss and a curriculum schedule that gradually shifts focus from low- to high-frequency spaces in line with coarse to detailed motion patterns. Extensive experiments on MSR-Action3D, NTU-RGBD and NTU-RGBD120 demonstrate that SRENet achieves state-of-the-art performance, validating the effectiveness of frequency modeling in point cloud-based action understanding.
Human Identification at a Distance: Challenges, Methods and Results on the Competition HID 2025
Feb 07, 2026Human identification at a distance (HID) is challenging because traditional biometric modalities such as face and fingerprints are often difficult to acquire in real-world scenarios. Gait recognition provides a practical alternative, as it can be captured reliably at a distance. To promote progress in gait recognition and provide a fair evaluation platform, the International Competition on Human Identification at a Distance (HID) has been organized annually since 2020. Since 2023, the competition has adopted the challenging SUSTech-Competition dataset, which features substantial variations in clothing, carried objects, and view angles. No dedicated training data are provided, requiring participants to train their models using external datasets. Each year, the competition applies a different random seed to generate distinct evaluation splits, which reduces the risk of overfitting and supports a fair assessment of cross-domain generalization. While HID 2023 and HID 2024 already used this dataset, HID 2025 explicitly examined whether algorithmic advances could surpass the accuracy limits observed previously. Despite the heightened difficulty, participants achieved further improvements, and the best-performing method reached 94.2% accuracy, setting a new benchmark on this dataset. We also analyze key technical trends and outline potential directions for future research in gait recognition.
Pb4U-GNet: Resolution-Adaptive Garment Simulation via Propagation-before-Update Graph Network
Jan 21, 2026Garment simulation is fundamental to various applications in computer vision and graphics, from virtual try-on to digital human modelling. However, conventional physics-based methods remain computationally expensive, hindering their application in time-sensitive scenarios. While graph neural networks (GNNs) offer promising acceleration, existing approaches exhibit poor cross-resolution generalisation, demonstrating significant performance degradation on higher-resolution meshes beyond the training distribution. This stems from two key factors: (1) existing GNNs employ fixed message-passing depth that fails to adapt information aggregation to mesh density variation, and (2) vertex-wise displacement magnitudes are inherently resolution-dependent in garment simulation. To address these issues, we introduce Propagation-before-Update Graph Network (Pb4U-GNet), a resolution-adaptive framework that decouples message propagation from feature updates. Pb4U-GNet incorporates two key mechanisms: (1) dynamic propagation depth control, adjusting message-passing iterations based on mesh resolution, and (2) geometry-aware update scaling, which scales predictions according to local mesh characteristics. Extensive experiments show that even trained solely on low-resolution meshes, Pb4U-GNet exhibits strong generalisability across diverse mesh resolutions, addressing a fundamental challenge in neural garment simulation.
M3DHMR: Monocular 3D Hand Mesh Recovery
May 26, 2025Monocular 3D hand mesh recovery is challenging due to high degrees of freedom of hands, 2D-to-3D ambiguity and self-occlusion. Most existing methods are either inefficient or less straightforward for predicting the position of 3D mesh vertices. Thus, we propose a new pipeline called Monocular 3D Hand Mesh Recovery (M3DHMR) to directly estimate the positions of hand mesh vertices. M3DHMR provides 2D cues for 3D tasks from a single image and uses a new spiral decoder consist of several Dynamic Spiral Convolution (DSC) Layers and a Region of Interest (ROI) Layer. On the one hand, DSC Layers adaptively adjust the weights based on the vertex positions and extract the vertex features in both spatial and channel dimensions. On the other hand, ROI Layer utilizes the physical information and refines mesh vertices in each predefined hand region separately. Extensive experiments on popular dataset FreiHAND demonstrate that M3DHMR significantly outperforms state-of-the-art real-time methods.
SplatCo: Structure-View Collaborative Gaussian Splatting for Detail-Preserving Rendering of Large-Scale Unbounded Scenes
May 23, 2025We present SplatCo, a structure-view collaborative Gaussian splatting framework for high-fidelity rendering of complex outdoor environments. SplatCo builds upon two novel components: (1) a cross-structure collaboration module that combines global tri-plane representations, which capture coarse scene layouts, with local context grid features that represent fine surface details. This fusion is achieved through a novel hierarchical compensation strategy, ensuring both global consistency and local detail preservation; and (2) a cross-view assisted training strategy that enhances multi-view consistency by synchronizing gradient updates across viewpoints, applying visibility-aware densification, and pruning overfitted or inaccurate Gaussians based on structural consistency. Through joint optimization of structural representation and multi-view coherence, SplatCo effectively reconstructs fine-grained geometric structures and complex textures in large-scale scenes. Comprehensive evaluations on 13 diverse large-scale scenes, including Mill19, MatrixCity, Tanks & Temples, WHU, and custom aerial captures, demonstrate that SplatCo consistently achieves higher reconstruction quality than state-of-the-art methods, with PSNR improvements of 1-2 dB and SSIM gains of 0.1 to 0.2. These results establish a new benchmark for high-fidelity rendering of large-scale unbounded scenes. Code and additional information are available at https://github.com/SCUT-BIP-Lab/SplatCo.
EA-3DGS: Efficient and Adaptive 3D Gaussians with Highly Enhanced Quality for outdoor scenes
May 16, 2025Efficient scene representations are essential for many real-world applications, especially those involving spatial measurement. Although current NeRF-based methods have achieved impressive results in reconstructing building-scale scenes, they still suffer from slow training and inference speeds due to time-consuming stochastic sampling. Recently, 3D Gaussian Splatting (3DGS) has demonstrated excellent performance with its high-quality rendering and real-time speed, especially for objects and small-scale scenes. However, in outdoor scenes, its point-based explicit representation lacks an effective adjustment mechanism, and the millions of Gaussian points required often lead to memory constraints during training. To address these challenges, we propose EA-3DGS, a high-quality real-time rendering method designed for outdoor scenes. First, we introduce a mesh structure to regulate the initialization of Gaussian components by leveraging an adaptive tetrahedral mesh that partitions the grid and initializes Gaussian components on each face, effectively capturing geometric structures in low-texture regions. Second, we propose an efficient Gaussian pruning strategy that evaluates each 3D Gaussian's contribution to the view and prunes accordingly. To retain geometry-critical Gaussian points, we also present a structure-aware densification strategy that densifies Gaussian points in low-curvature regions. Additionally, we employ vector quantization for parameter quantization of Gaussian components, significantly reducing disk space requirements with only a minimal impact on rendering quality. Extensive experiments on 13 scenes, including eight from four public datasets (MatrixCity-Aerial, Mill-19, Tanks \& Temples, WHU) and five self-collected scenes acquired through UAV photogrammetry measurement from SCUT-CA and plateau regions, further demonstrate the superiority of our method.
AS3D: 2D-Assisted Cross-Modal Understanding with Semantic-Spatial Scene Graphs for 3D Visual Grounding
May 07, 20253D visual grounding aims to localize the unique target described by natural languages in 3D scenes. The significant gap between 3D and language modalities makes it a notable challenge to distinguish multiple similar objects through the described spatial relationships. Current methods attempt to achieve cross-modal understanding in complex scenes via a target-centered learning mechanism, ignoring the perception of referred objects. We propose a novel 2D-assisted 3D visual grounding framework that constructs semantic-spatial scene graphs with referred object discrimination for relationship perception. The framework incorporates a dual-branch visual encoder that utilizes 2D pre-trained attributes to guide the multi-modal object encoding. Furthermore, our cross-modal interaction module uses graph attention to facilitate relationship-oriented information fusion. The enhanced object representation and iterative relational learning enable the model to establish effective alignment between 3D vision and referential descriptions. Experimental results on the popular benchmarks demonstrate our superior performance compared to state-of-the-art methods, especially in addressing the challenges of multiple similar distractors.
Pseudo-label Refinement for Improving Self-Supervised Learning Systems
Oct 18, 2024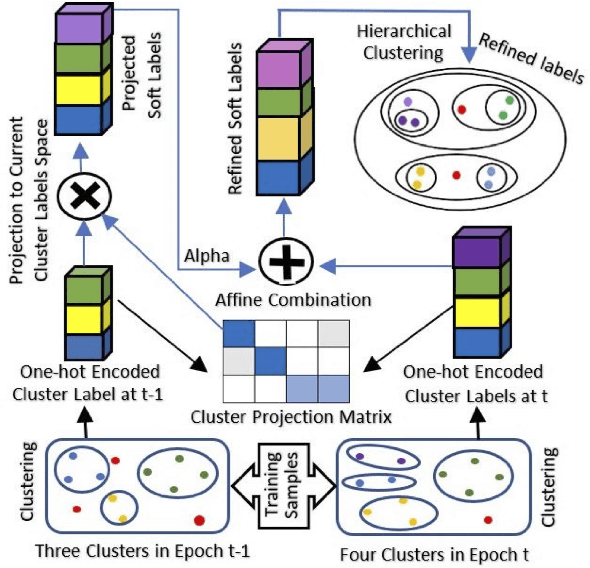

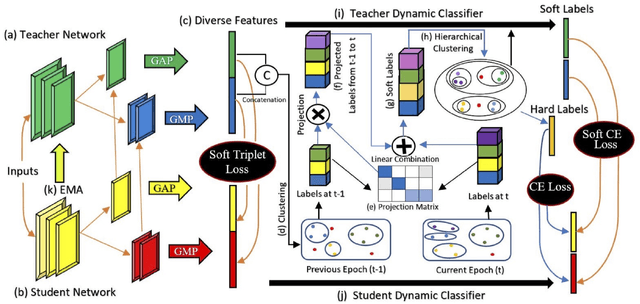

Self-supervised learning systems have gained significant attention in recent years by leveraging clustering-based pseudo-labels to provide supervision without the need for human annotations. However, the noise in these pseudo-labels caused by the clustering methods poses a challenge to the learning process leading to degraded performance. In this work, we propose a pseudo-label refinement (SLR) algorithm to address this issue. The cluster labels from the previous epoch are projected to the current epoch cluster-labels space and a linear combination of the new label and the projected label is computed as a soft refined label containing the information from the previous epoch clusters as well as from the current epoch. In contrast to the common practice of using the maximum value as a cluster/class indicator, we employ hierarchical clustering on these soft pseudo-labels to generate refined hard-labels. This approach better utilizes the information embedded in the soft labels, outperforming the simple maximum value approach for hard label generation. The effectiveness of the proposed SLR algorithm is evaluated in the context of person re-identification (Re-ID) using unsupervised domain adaptation (UDA). Experimental results demonstrate that the modified Re-ID baseline, incorporating the SLR algorithm, achieves significantly improved mean Average Precision (mAP) performance in various UDA tasks, including real-to-synthetic, synthetic-to-real, and different real-to-real scenarios. These findings highlight the efficacy of the SLR algorithm in enhancing the performance of self-supervised learning systems.
4DStyleGaussian: Zero-shot 4D Style Transfer with Gaussian Splatting
Oct 14, 20243D neural style transfer has gained significant attention for its potential to provide user-friendly stylization with spatial consistency. However, existing 3D style transfer methods often fall short in terms of inference efficiency, generalization ability, and struggle to handle dynamic scenes with temporal consistency. In this paper, we introduce 4DStyleGaussian, a novel 4D style transfer framework designed to achieve real-time stylization of arbitrary style references while maintaining reasonable content affinity, multi-view consistency, and temporal coherence. Our approach leverages an embedded 4D Gaussian Splatting technique, which is trained using a reversible neural network for reducing content loss in the feature distillation process. Utilizing the 4D embedded Gaussians, we predict a 4D style transformation matrix that facilitates spatially and temporally consistent style transfer with Gaussian Splatting. Experiments demonstrate that our method can achieve high-quality and zero-shot stylization for 4D scenarios with enhanced efficiency and spatial-temporal consistency.
ControLRM: Fast and Controllable 3D Generation via Large Reconstruction Model
Oct 12, 2024



Despite recent advancements in 3D generation methods, achieving controllability still remains a challenging issue. Current approaches utilizing score-distillation sampling are hindered by laborious procedures that consume a significant amount of time. Furthermore, the process of first generating 2D representations and then mapping them to 3D lacks internal alignment between the two forms of representation. To address these challenges, we introduce ControLRM, an end-to-end feed-forward model designed for rapid and controllable 3D generation using a large reconstruction model (LRM). ControLRM comprises a 2D condition generator, a condition encoding transformer, and a triplane decoder transformer. Instead of training our model from scratch, we advocate for a joint training framework. In the condition training branch, we lock the triplane decoder and reuses the deep and robust encoding layers pretrained with millions of 3D data in LRM. In the image training branch, we unlock the triplane decoder to establish an implicit alignment between the 2D and 3D representations. To ensure unbiased evaluation, we curate evaluation samples from three distinct datasets (G-OBJ, GSO, ABO) rather than relying on cherry-picking manual generation. The comprehensive experiments conducted on quantitative and qualitative comparisons of 3D controllability and generation quality demonstrate the strong generalization capacity of our proposed approach.