 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLUBench: A Clustering Benchmark
May 28, 2026Clustering is a fundamental problem in data science with a long-standing research history, yielding numerous insightful algorithms. Despite this progress, a systematic and large-scale empirical evaluation that jointly considers conventional algorithms, deep learning-based methods, and recent foundation model-based clustering remains largely absent, leading to limited guidance on algorithm selection and deployment. To address this gap, we introduce CLUBench, a comprehensive clustering benchmark comprising 24 algorithms of diverse principles evaluated on 131 datasets across tabular, text, and image data, involving 178,815 experiments. Importantly, our analyses of (i) the impact of hyperparameter tuning,(ii) the impact of data types and characteristics,(iii) the impact of pretrained embeddings,(iv) large language model-based clustering,(v) the similarity of algorithms, and (vi) the low-rank structures of performance matrices, yield meaningful insights and promising pathways for clustering research. For instance, our study reveals that: 1) All evaluated deep clustering methods do not exhibit a significant advantage compared with the top-performing conventional clustering algorithms (e.g., KMeans, SpeClu) in terms of average performance; 2) For image and text clustering tasks, combining pretrained embeddings with conventional clustering algorithms (e.g., KMeans, SpeClu) offers effective and efficient clustering; 3) Clustering remains a challenging and nontrivial problem, even in the era of increasingly dominant foundation models. Moreover, we propose to use the low-rank structure in cross-model performance matrices to efficiently approximate the overall performance evaluation in practical applications. We further demonstrate the feasibility of model selection based on the performance matrices across all hyperparameter configurations.
Resolving Long-Tail Ambiguity in Unsupervised 3D Point Cloud Segmentation with Language Priors
May 20, 2026Existing approaches for unsupervised 3D point cloud segmentation predominantly rely on a purely visual similarity-based learning-by-clustering paradigm, which suffers from a fundamental limitation: long-tail ambiguity. In such a paradigm, features of minor classes are consistently absorbed by dominant clusters, leading to severely imbalanced predictions. To address this issue, we propose LangTail, a language-guided hierarchical learning framework that leverages the balanced world knowledge encoded in language models to mitigate long-tail ambiguity in unsupervised 3D segmentation. The key idea is to establish multi-level associations between language-derived semantic priors and visually underrepresented minor classes, thereby compensating for the biased attention of purely visual clustering toward dominant classes. Specifically, LangTail first constructs an entity-level semantic prior from language models, capturing balanced and fine-grained world knowledge across categories. These priors are injected into a hierarchical clustering framework via contrastive alignment. This guides multi-granularity semantic structure formation and prevents minor classes from being absorbed by dominant clusters, yielding more discriminative representations for underrepresented categories. Extensive experiments on ScanNet-v2, S3DIS, and nuScenes demonstrate that LangTail consistently outperforms existing methods by significant margins, \ie, +13.5, +12.9, and +8.9 mIoU, respectively. These results demonstrate the effectiveness of language priors in improving the representation of minority classes in 3D point clouds. The code will be released at: https://github.com/Whisky0129/langtail_official.
Triviality Corrected Endogenous Reward
Apr 13, 2026Reinforcement learning for open-ended text generation is constrained by the lack of verifiable rewards, necessitating reliance on judge models that require either annotated data or powerful closed-source models. Inspired by recent work on unsupervised reinforcement learning for mathematical reasoning using confidence-based endogenous rewards, we investigate whether this principle can be adapted to open-ended writing tasks. We find that directly applying confidence rewards leads to Triviality Bias: the policy collapses toward high-probability outputs, reducing diversity and meaningful content. We propose TCER (Triviality Corrected Endogenous Reward), which addresses this bias by rewarding the relative information gain between a specialist policy and a generalist reference policy, modulated by a probability-dependent correction mechanism. Across multiple writing benchmarks and model architectures, TCER achieves consistent improvements without external supervision. Furthermore, TCER also transfers effectively to mathematical reasoning, validating the generality of our approach across different generation tasks.
SignalClaw: LLM-Guided Evolutionary Synthesis of Interpretable Traffic Signal Control Skills
Apr 07, 2026Traffic signal control TSC requires strategies that are both effective and interpretable for deployment, yet reinforcement learning produces opaque neural policies while program synthesis depends on restrictive domain-specific languages. We present SIGNALCLAW, a framework that uses large language models LLMs as evolutionary skill generators to synthesize and refine interpretable control skills for adaptive TSC. Each skill includes rationale, selection guidance, and executable code, making policies human-inspectable and self-documenting. At each generation, evolution signals from simulation metrics such as queue percentiles, delay trends, and stagnation are translated into natural language feedback to guide improvement. SignalClaw also introduces event-driven compositional evolution: an event detector identifies emergency vehicles, transit priority, incidents, and congestion via TraCI, and a priority dispatcher selects specialized skills. Each skill is evolved independently, and a priority chain enables runtime composition without retraining. We evaluate SignalClaw on routine and event-injected SUMO scenarios against four baselines. On routine scenarios, it achieves average delay of 7.8 to 9.2 seconds, within 3 to 10 percent of the best method, with low variance across random seeds. Under event scenarios, it yields the lowest emergency delay 11.2 to 18.5 seconds versus 42.3 to 72.3 for MaxPressure and 78.5 to 95.3 for DQN, and the lowest transit person delay 9.8 to 11.5 seconds versus 38.7 to 45.2 for MaxPressure. In mixed events, the dispatcher composes skills effectively while maintaining stable overall delay. The evolved skills progress from simple linear rules to conditional strategies with multi-feature interactions, while remaining fully interpretable and directly modifiable by traffic engineers.
Bumper Drone: Elastic Morphology Design for Aerial Physical Interaction
Feb 21, 2026Aerial robots are evolving from avoiding obstacles to exploiting the environmental contact interactions for navigation, exploration and manipulation. A key challenge in such aerial physical interactions lies in handling uncertain contact forces on unknown targets, which typically demand accurate sensing and active control. We present a drone platform with elastic horns that enables touch-and-go manoeuvres - a self-regulated, consecutive bumping motion that allows the drone to maintain proximity to a wall without relying on active obstacle avoidance. It leverages environmental interaction as a form of embodied control, where low-level stabilisation and near-obstacle navigation emerge from the passive dynamic responses of the drone-obstacle system that resembles a mass-spring-damper system. Experiments show that the elastic horn can absorb impact energy while maintaining vehicle stability, reducing pitch oscillations by 38% compared to the rigid horn configuration. The lower horn arrangement was found to reduce pitch oscillations by approximately 54%. In addition to intermittent contact, the platform equipped with elastic horns also demonstrates stable, sustained contact with static objects, relying on a standard attitude PID controller.
Outcome-Grounded Advantage Reshaping for Fine-Grained Credit Assignment in Mathematical Reasoning
Jan 12, 2026Group Relative Policy Optimization (GRPO) has emerged as a promising critic-free reinforcement learning paradigm for reasoning tasks. However, standard GRPO employs a coarse-grained credit assignment mechanism that propagates group-level rewards uniformly to to every token in a sequence, neglecting the varying contribution of individual reasoning steps. We address this limitation by introducing Outcome-grounded Advantage Reshaping (OAR), a fine-grained credit assignment mechanism that redistributes advantages based on how much each token influences the model's final answer. We instantiate OAR via two complementary strategies: (1) OAR-P, which estimates outcome sensitivity through counterfactual token perturbations, serving as a high-fidelity attribution signal; (2) OAR-G, which uses an input-gradient sensitivity proxy to approximate the influence signal with a single backward pass. These importance signals are integrated with a conservative Bi-Level advantage reshaping scheme that suppresses low-impact tokens and boosts pivotal ones while preserving the overall advantage mass. Empirical results on extensive mathematical reasoning benchmarks demonstrate that while OAR-P sets the performance upper bound, OAR-G achieves comparable gains with negligible computational overhead, both significantly outperforming a strong GRPO baseline, pushing the boundaries of critic-free LLM reasoning.
IRPO: Scaling the Bradley-Terry Model via Reinforcement Learning
Jan 02, 2026Generative Reward Models (GRMs) have attracted considerable research interest in reward modeling due to their interpretability, inference-time scalability, and potential for refinement through reinforcement learning (RL). However, widely used pairwise GRMs create a computational bottleneck when integrated with RL algorithms such as Group Relative Policy Optimization (GRPO). This bottleneck arises from two factors: (i) the O(n^2) time complexity of pairwise comparisons required to obtain relative scores, and (ii) the computational overhead of repeated sampling or additional chain-of-thought (CoT) reasoning to improve performance. To address the first factor, we propose Intergroup Relative Preference Optimization (IRPO), a novel RL framework that incorporates the well-established Bradley-Terry model into GRPO. By generating a pointwise score for each response, IRPO enables efficient evaluation of arbitrarily many candidates during RL training while preserving interpretability and fine-grained reward signals. Experimental results demonstrate that IRPO achieves state-of-the-art (SOTA) performance among pointwise GRMs across multiple benchmarks, with performance comparable to that of current leading pairwise GRMs. Furthermore, we show that IRPO significantly outperforms pairwise GRMs in post-training evaluations.
MV-Debate: Multi-view Agent Debate with Dynamic Reflection Gating for Multimodal Harmful Content Detection in Social Media
Aug 07, 2025Social media has evolved into a complex multimodal environment where text, images, and other signals interact to shape nuanced meanings, often concealing harmful intent. Identifying such intent, whether sarcasm, hate speech, or misinformation, remains challenging due to cross-modal contradictions, rapid cultural shifts, and subtle pragmatic cues. To address these challenges, we propose MV-Debate, a multi-view agent debate framework with dynamic reflection gating for unified multimodal harmful content detection. MV-Debate assembles four complementary debate agents, a surface analyst, a deep reasoner, a modality contrast, and a social contextualist, to analyze content from diverse interpretive perspectives. Through iterative debate and reflection, the agents refine responses under a reflection-gain criterion, ensuring both accuracy and efficiency. Experiments on three benchmark datasets demonstrate that MV-Debate significantly outperforms strong single-model and existing multi-agent debate baselines. This work highlights the promise of multi-agent debate in advancing reliable social intent detection in safety-critical online contexts.
Text-ADBench: Text Anomaly Detection Benchmark based on LLMs Embedding
Jul 16, 2025Text anomaly detection is a critical task in natural language processing (NLP), with applications spanning fraud detection, misinformation identification, spam detection and content moderation, etc. Despite significant advances in large language models (LLMs) and anomaly detection algorithms, the absence of standardized and comprehensive benchmarks for evaluating the existing anomaly detection methods on text data limits rigorous comparison and development of innovative approaches. This work performs a comprehensive empirical study and introduces a benchmark for text anomaly detection, leveraging embeddings from diverse pre-trained language models across a wide array of text datasets. Our work systematically evaluates the effectiveness of embedding-based text anomaly detection by incorporating (1) early language models (GloVe, BERT); (2) multiple LLMs (LLaMa-2, LLama-3, Mistral, OpenAI (small, ada, large)); (3) multi-domain text datasets (news, social media, scientific publications); (4) comprehensive evaluation metrics (AUROC, AUPRC). Our experiments reveal a critical empirical insight: embedding quality significantly governs anomaly detection efficacy, and deep learning-based approaches demonstrate no performance advantage over conventional shallow algorithms (e.g., KNN, Isolation Forest) when leveraging LLM-derived embeddings.In addition, we observe strongly low-rank characteristics in cross-model performance matrices, which enables an efficient strategy for rapid model evaluation (or embedding evaluation) and selection in practical applications. Furthermore, by open-sourcing our benchmark toolkit that includes all embeddings from different models and code at https://github.com/jicongfan/Text-Anomaly-Detection-Benchmark, this work provides a foundation for future research in robust and scalable text anomaly detection systems.
Fairness-aware Anomaly Detection via Fair Projection
May 16, 2025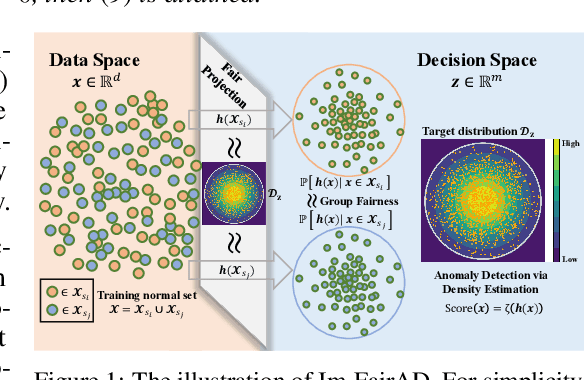
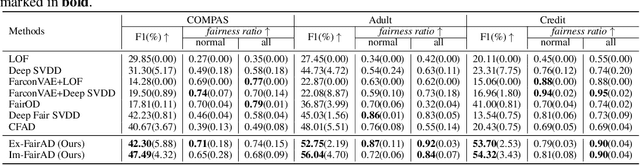
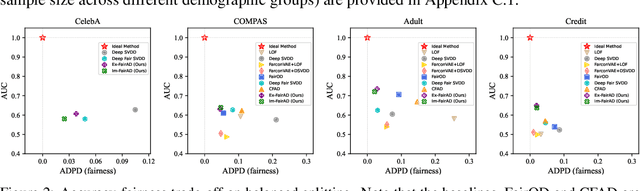
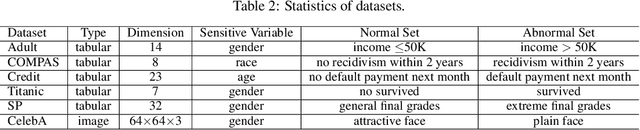
Unsupervised anomaly detection is a critical task in many high-social-impact applications such as finance, healthcare, social media, and cybersecurity, where demographics involving age, gender, race, disease, etc, are used frequently. In these scenarios, possible bias from anomaly detection systems can lead to unfair treatment for different groups and even exacerbate social bias. In this work, first, we thoroughly analyze the feasibility and necessary assumptions for ensuring group fairness in unsupervised anomaly detection. Second, we propose a novel fairness-aware anomaly detection method FairAD. From the normal training data, FairAD learns a projection to map data of different demographic groups to a common target distribution that is simple and compact, and hence provides a reliable base to estimate the density of the data. The density can be directly used to identify anomalies while the common target distribution ensures fairness between different groups. Furthermore, we propose a threshold-free fairness metric that provides a global view for model's fairness, eliminating dependence on manual threshold selection. Experiments on real-world benchmarks demonstrate that our method achieves an improved trade-off between detection accuracy and fairness under both balanced and skewed data across different groups.