 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSRENet: Spectral Re-Entry Network for Point Cloud Action Recognition
Jun 02, 2026Recognizing human actions from point cloud sequences is critical for 3D perception driven applications such as autonomous driving and human-computer interaction. However, the irregular structure and temporal inconsistency of point clouds pose unique challenges for spatio-temporal representation learning, especially in capturing both global motion context and fine-grained temporal dynamics. We propose SRENet, a spectral-aware framework designed to explicitly learn both global context and fine-grained temporal dynamics of motion from a frequency perspective for action recognition. SRENet introduces a Spectral Decomposition Block (SDeBlock) that performs wavelet-based analysis along temporal and spatial axes, disentangling features into low- and high-frequency components with frequency-specific attention. To recover residual dynamics and re-align temporal frequency structures distorted during semantic fusion, a Spectral Re-entry Block (SReBlock) performs secondary temporal decomposition. Furthermore, a spectral-aware learning strategy is devised to enhance discriminability in both frequency subspaces via contrastive loss and a curriculum schedule that gradually shifts focus from low- to high-frequency spaces in line with coarse to detailed motion patterns. Extensive experiments on MSR-Action3D, NTU-RGBD and NTU-RGBD120 demonstrate that SRENet achieves state-of-the-art performance, validating the effectiveness of frequency modeling in point cloud-based action understanding.
Resolving Long-Tail Ambiguity in Unsupervised 3D Point Cloud Segmentation with Language Priors
May 20, 2026Existing approaches for unsupervised 3D point cloud segmentation predominantly rely on a purely visual similarity-based learning-by-clustering paradigm, which suffers from a fundamental limitation: long-tail ambiguity. In such a paradigm, features of minor classes are consistently absorbed by dominant clusters, leading to severely imbalanced predictions. To address this issue, we propose LangTail, a language-guided hierarchical learning framework that leverages the balanced world knowledge encoded in language models to mitigate long-tail ambiguity in unsupervised 3D segmentation. The key idea is to establish multi-level associations between language-derived semantic priors and visually underrepresented minor classes, thereby compensating for the biased attention of purely visual clustering toward dominant classes. Specifically, LangTail first constructs an entity-level semantic prior from language models, capturing balanced and fine-grained world knowledge across categories. These priors are injected into a hierarchical clustering framework via contrastive alignment. This guides multi-granularity semantic structure formation and prevents minor classes from being absorbed by dominant clusters, yielding more discriminative representations for underrepresented categories. Extensive experiments on ScanNet-v2, S3DIS, and nuScenes demonstrate that LangTail consistently outperforms existing methods by significant margins, \ie, +13.5, +12.9, and +8.9 mIoU, respectively. These results demonstrate the effectiveness of language priors in improving the representation of minority classes in 3D point clouds. The code will be released at: https://github.com/Whisky0129/langtail_official.
Pb4U-GNet: Resolution-Adaptive Garment Simulation via Propagation-before-Update Graph Network
Jan 21, 2026Garment simulation is fundamental to various applications in computer vision and graphics, from virtual try-on to digital human modelling. However, conventional physics-based methods remain computationally expensive, hindering their application in time-sensitive scenarios. While graph neural networks (GNNs) offer promising acceleration, existing approaches exhibit poor cross-resolution generalisation, demonstrating significant performance degradation on higher-resolution meshes beyond the training distribution. This stems from two key factors: (1) existing GNNs employ fixed message-passing depth that fails to adapt information aggregation to mesh density variation, and (2) vertex-wise displacement magnitudes are inherently resolution-dependent in garment simulation. To address these issues, we introduce Propagation-before-Update Graph Network (Pb4U-GNet), a resolution-adaptive framework that decouples message propagation from feature updates. Pb4U-GNet incorporates two key mechanisms: (1) dynamic propagation depth control, adjusting message-passing iterations based on mesh resolution, and (2) geometry-aware update scaling, which scales predictions according to local mesh characteristics. Extensive experiments show that even trained solely on low-resolution meshes, Pb4U-GNet exhibits strong generalisability across diverse mesh resolutions, addressing a fundamental challenge in neural garment simulation.
DC-PCN: Point Cloud Completion Network with Dual-Codebook Guided Quantization
Jan 19, 2025Point cloud completion aims to reconstruct complete 3D shapes from partial 3D point clouds. With advancements in deep learning techniques, various methods for point cloud completion have been developed. Despite achieving encouraging results, a significant issue remains: these methods often overlook the variability in point clouds sampled from a single 3D object surface. This variability can lead to ambiguity and hinder the achievement of more precise completion results. Therefore, in this study, we introduce a novel point cloud completion network, namely Dual-Codebook Point Completion Network (DC-PCN), following an encder-decoder pipeline. The primary objective of DC-PCN is to formulate a singular representation of sampled point clouds originating from the same 3D surface. DC-PCN introduces a dual-codebook design to quantize point-cloud representations from a multilevel perspective. It consists of an encoder-codebook and a decoder-codebook, designed to capture distinct point cloud patterns at shallow and deep levels. Additionally, to enhance the information flow between these two codebooks, we devise an information exchange mechanism. This approach ensures that crucial features and patterns from both shallow and deep levels are effectively utilized for completion. Extensive experiments on the PCN, ShapeNet\_Part, and ShapeNet34 datasets demonstrate the state-of-the-art performance of our method.
RI-MAE: Rotation-Invariant Masked AutoEncoders for Self-Supervised Point Cloud Representation Learning
Aug 31, 2024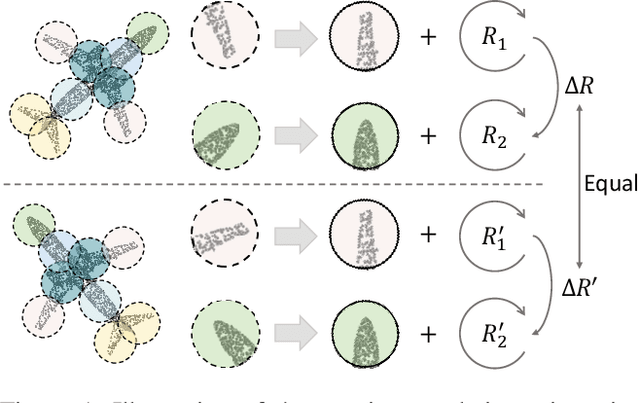
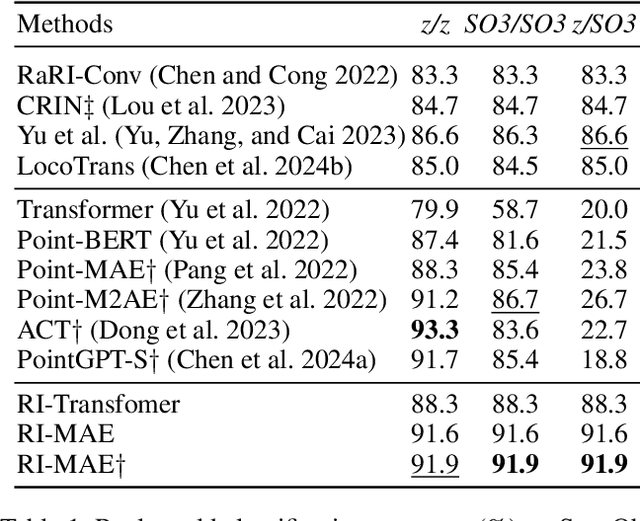
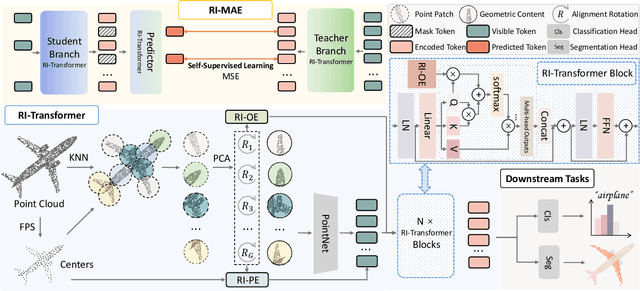
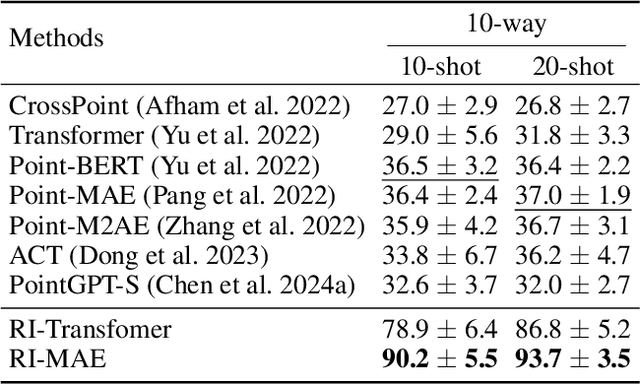
Masked point modeling methods have recently achieved great success in self-supervised learning for point cloud data. However, these methods are sensitive to rotations and often exhibit sharp performance drops when encountering rotational variations. In this paper, we propose a novel Rotation-Invariant Masked AutoEncoders (RI-MAE) to address two major challenges: 1) achieving rotation-invariant latent representations, and 2) facilitating self-supervised reconstruction in a rotation-invariant manner. For the first challenge, we introduce RI-Transformer, which features disentangled geometry content, rotation-invariant relative orientation and position embedding mechanisms for constructing rotation-invariant point cloud latent space. For the second challenge, a novel dual-branch student-teacher architecture is devised. It enables the self-supervised learning via the reconstruction of masked patches within the learned rotation-invariant latent space. Each branch is based on an RI-Transformer, and they are connected with an additional RI-Transformer predictor. The teacher encodes all point patches, while the student solely encodes unmasked ones. Finally, the predictor predicts the latent features of the masked patches using the output latent embeddings from the student, supervised by the outputs from the teacher. Extensive experiments demonstrate that our method is robust to rotations, achieving the state-of-the-art performance on various downstream tasks.
SeCG: Semantic-Enhanced 3D Visual Grounding via Cross-modal Graph Attention
Mar 13, 2024



3D visual grounding aims to automatically locate the 3D region of the specified object given the corresponding textual description. Existing works fail to distinguish similar objects especially when multiple referred objects are involved in the description. Experiments show that direct matching of language and visual modal has limited capacity to comprehend complex referential relationships in utterances. It is mainly due to the interference caused by redundant visual information in cross-modal alignment. To strengthen relation-orientated mapping between different modalities, we propose SeCG, a semantic-enhanced relational learning model based on a graph network with our designed memory graph attention layer. Our method replaces original language-independent encoding with cross-modal encoding in visual analysis. More text-related feature expressions are obtained through the guidance of global semantics and implicit relationships. Experimental results on ReferIt3D and ScanRefer benchmarks show that the proposed method outperforms the existing state-of-the-art methods, particularly improving the localization performance for the multi-relation challenges.
Part to Whole: Collaborative Prompting for Surgical Instrument Segmentation
Dec 22, 2023Foundation models like the Segment Anything Model (SAM) have demonstrated promise in generic object segmentation. However, directly applying SAM to surgical instrument segmentation presents key challenges. First, SAM relies on per-frame point-or-box prompts which complicate surgeon-computer interaction. Also, SAM yields suboptimal performance on segmenting surgical instruments, owing to insufficient surgical data in its pre-training as well as the complex structure and fine-grained details of various surgical instruments. To address these challenges, in this paper, we investigate text promptable surgical instrument segmentation and propose SP-SAM (SurgicalPart-SAM), a novel efficient-tuning approach that integrates surgical instrument structure knowledge with the generic segmentation knowledge of SAM. Specifically, we achieve this by proposing (1) collaborative prompts in the text form "[part name] of [instrument category name]" that decompose instruments into fine-grained parts; (2) a Cross-Modal Prompt Encoder that encodes text prompts jointly with visual embeddings into discriminative part-level representations; and (3) a Part-to-Whole Selective Fusion and a Hierarchical Decoding strategy that selectively assemble the part-level representations into a whole for accurate instrument segmentation. Built upon them, SP-SAM acquires a better capability to comprehend surgical instrument structures and distinguish between various categories. Extensive experiments on both the EndoVis2018 and EndoVis2017 datasets demonstrate SP-SAM's state-of-the-art performance with minimal tunable parameters. Code is at https://github.com/wenxi-yue/SurgicalPart-SAM.
Self-supervised Multi-view Stereo via Effective Co-Segmentation and Data-Augmentation
Apr 12, 2021Recent studies have witnessed that self-supervised methods based on view synthesis obtain clear progress on multi-view stereo (MVS). However, existing methods rely on the assumption that the corresponding points among different views share the same color, which may not always be true in practice. This may lead to unreliable self-supervised signal and harm the final reconstruction performance. To address the issue, we propose a framework integrated with more reliable supervision guided by semantic co-segmentation and data-augmentation. Specially, we excavate mutual semantic from multi-view images to guide the semantic consistency. And we devise effective data-augmentation mechanism which ensures the transformation robustness by treating the prediction of regular samples as pseudo ground truth to regularize the prediction of augmented samples. Experimental results on DTU dataset show that our proposed methods achieve the state-of-the-art performance among unsupervised methods, and even compete on par with supervised methods. Furthermore, extensive experiments on Tanks&Temples dataset demonstrate the effective generalization ability of the proposed method.