 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentity-Consistent Diffusion Network for Grading Knee Osteoarthritis Progression in Radiographic Imaging
Jul 31, 2024
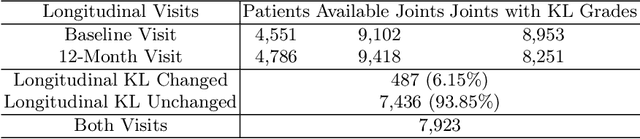
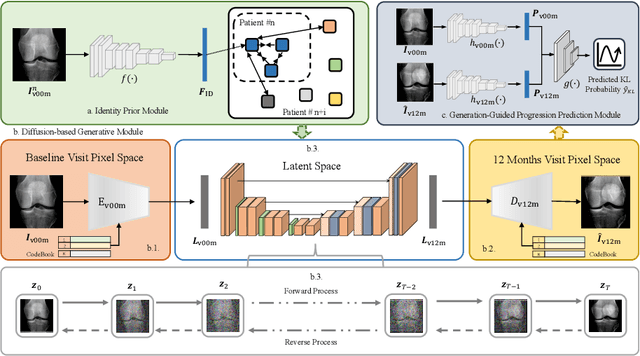

Knee osteoarthritis (KOA), a common form of arthritis that causes physical disability, has become increasingly prevalent in society. Employing computer-aided techniques to automatically assess the severity and progression of KOA can greatly benefit KOA treatment and disease management. Particularly, the advancement of X-ray technology in KOA demonstrates its potential for this purpose. Yet, existing X-ray prognosis research generally yields a singular progression severity grade, overlooking the potential visual changes for understanding and explaining the progression outcome. Therefore, in this study, a novel generative model is proposed, namely Identity-Consistent Radiographic Diffusion Network (IC-RDN), for multifaceted KOA prognosis encompassing a predicted future knee X-ray scan conditioned on the baseline scan. Specifically, an identity prior module for the diffusion and a downstream generation-guided progression prediction module are introduced. Compared to conventional image-to-image generative models, identity priors regularize and guide the diffusion to focus more on the clinical nuances of the prognosis based on a contrastive learning strategy. The progression prediction module utilizes both forecasted and baseline knee scans, and a more comprehensive formulation of KOA severity progression grading is expected. Extensive experiments on a widely used public dataset, OAI, demonstrate the effectiveness of the proposed method.
Part to Whole: Collaborative Prompting for Surgical Instrument Segmentation
Dec 22, 2023Foundation models like the Segment Anything Model (SAM) have demonstrated promise in generic object segmentation. However, directly applying SAM to surgical instrument segmentation presents key challenges. First, SAM relies on per-frame point-or-box prompts which complicate surgeon-computer interaction. Also, SAM yields suboptimal performance on segmenting surgical instruments, owing to insufficient surgical data in its pre-training as well as the complex structure and fine-grained details of various surgical instruments. To address these challenges, in this paper, we investigate text promptable surgical instrument segmentation and propose SP-SAM (SurgicalPart-SAM), a novel efficient-tuning approach that integrates surgical instrument structure knowledge with the generic segmentation knowledge of SAM. Specifically, we achieve this by proposing (1) collaborative prompts in the text form "[part name] of [instrument category name]" that decompose instruments into fine-grained parts; (2) a Cross-Modal Prompt Encoder that encodes text prompts jointly with visual embeddings into discriminative part-level representations; and (3) a Part-to-Whole Selective Fusion and a Hierarchical Decoding strategy that selectively assemble the part-level representations into a whole for accurate instrument segmentation. Built upon them, SP-SAM acquires a better capability to comprehend surgical instrument structures and distinguish between various categories. Extensive experiments on both the EndoVis2018 and EndoVis2017 datasets demonstrate SP-SAM's state-of-the-art performance with minimal tunable parameters. Code is at https://github.com/wenxi-yue/SurgicalPart-SAM.
Robust Audio Anti-Spoofing with Fusion-Reconstruction Learning on Multi-Order Spectrograms
Aug 18, 2023



Robust audio anti-spoofing has been increasingly challenging due to the recent advancements on deepfake techniques. While spectrograms have demonstrated their capability for anti-spoofing, complementary information presented in multi-order spectral patterns have not been well explored, which limits their effectiveness for varying spoofing attacks. Therefore, we propose a novel deep learning method with a spectral fusion-reconstruction strategy, namely S2pecNet, to utilise multi-order spectral patterns for robust audio anti-spoofing representations. Specifically, spectral patterns up to second-order are fused in a coarse-to-fine manner and two branches are designed for the fine-level fusion from the spectral and temporal contexts. A reconstruction from the fused representation to the input spectrograms further reduces the potential fused information loss. Our method achieved the state-of-the-art performance with an EER of 0.77% on a widely used dataset: ASVspoof2019 LA Challenge.
SurgicalSAM: Efficient Class Promptable Surgical Instrument Segmentation
Aug 17, 2023



The Segment Anything Model (SAM) is a powerful foundation model that has revolutionised image segmentation. To apply SAM to surgical instrument segmentation, a common approach is to locate precise points or boxes of instruments and then use them as prompts for SAM in a zero-shot manner. However, we observe two problems with this naive pipeline: (1) the domain gap between natural objects and surgical instruments leads to poor generalisation of SAM; and (2) SAM relies on precise point or box locations for accurate segmentation, requiring either extensive manual guidance or a well-performing specialist detector for prompt preparation, which leads to a complex multi-stage pipeline. To address these problems, we introduce SurgicalSAM, a novel end-to-end efficient-tuning approach for SAM to effectively integrate surgical-specific information with SAM's pre-trained knowledge for improved generalisation. Specifically, we propose a lightweight prototype-based class prompt encoder for tuning, which directly generates prompt embeddings from class prototypes and eliminates the use of explicit prompts for improved robustness and a simpler pipeline. In addition, to address the low inter-class variance among surgical instrument categories, we propose contrastive prototype learning, further enhancing the discrimination of the class prototypes for more accurate class prompting. The results of extensive experiments on both EndoVis2018 and EndoVis2017 datasets demonstrate that SurgicalSAM achieves state-of-the-art performance while only requiring a small number of tunable parameters. The source code will be released at https://github.com/wenxi-yue/SurgicalSAM.