 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen to Stop Reusing: Dynamic Gradient Gating for Sample-Efficient RLVR
May 19, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has become the dominant paradigm for advanced reasoning in Large Language Models (LLMs), but rollout samples are expensive to obtain, making sample efficiency a critical bottleneck. A natural remedy is to reuse each rollout batch for multiple gradient updates, a standard practice in classical RL. Yet in RLVR, this amplifies policy shift, leading to severe performance degradation. Detecting the onset of degradation early enough to stop reuse remains an open and challenging problem. We close this gap by identifying the \textit{Disproportionate Weight Divergence (DWD)} phenomenon: performance degradation is synchronized with a sharp surge in the \texttt{lm\_head} weight change, while intermediate layers remain stable. Empirically, we verify that DWD emerges consistently across diverse LLMs and tasks. Theoretically, we prove that (i) harmful gradients concentrate at the \texttt{lm\_head} while intermediate layers are structurally attenuated, and (ii) the \texttt{lm\_head} gradient norm lower-bounds the policy divergence. These results establish the \texttt{lm\_head} gradient norm as a principled, real-time signal of catastrophic policy shift. Guided by this insight, we propose \textit{Dynamic Gradient Gating (DGG)}, a lightweight intervention that monitors the \texttt{lm\_head} gradient norm in real time and intercepts harmful gradients before they corrupt the optimizer. DGG consistently matches or exceeds the standard single-use baseline, achieving up to $2.93\times$ sample efficiency and $2.14\times$ wall-clock speedup across math, ALFWorld, WebShop, and search-augmented QA tasks.
Stable Attention Response for Reliable Precipitation Nowcasting
May 13, 2026Precipitation nowcasting remains challenging due to the highly localized, rapidly evolving, and heterogeneous nature of atmospheric dynamics. Although recent methods increasingly adopt attention-based architectures in both unimodal and multimodal settings, they mainly emphasize stronger representation learning and prediction capacity, while paying less attention to the stability of attention responses across samples. In this work, we show that cross-sample instability of attention-response energy is an important and previously underexplored source of forecasting unreliability. Empirically, inaccurate forecasts are associated with larger attention-response energy variance across heads and layers. Theoretically, we show that cross-sample variability can propagate through self-attention, and enlarge a lower bound on prediction error. Based on this insight, we propose HARECast, a Head-wise Attention Response Energy-regulated framework for precipitation nowcasting. HARECast explicitly models head-wise attention-response energy and stabilizes it through a group-wise regularization objective that reduces cross-sample fluctuations. The proposed formulation is generic and applicable to both unimodal and multimodal nowcasting architectures. We instantiate HARECast in a standard forecasting pipeline with reconstruction branches and a diffusion-based predictor, and evaluate it on commonly used benchmarks--SEVIR and MeteoNet. Experimental results demonstrate that HARECast achieves state-of-the-art performance.
RailVQA: A Benchmark and Framework for Efficient Interpretable Visual Cognition in Automatic Train Operation
Mar 28, 2026Automatic Train Operation (ATO) relies on low-latency, reliable cab-view visual perception and decision-oriented inference to ensure safe operation in complex and dynamic railway environments. However, existing approaches focus primarily on basic perception and often generalize poorly to rare yet safety-critical corner cases. They also lack the high-level reasoning and planning capabilities required for operational decision-making. Although recent Large Multi-modal Models (LMMs) show strong generalization and cognitive capabilities, their use in safety-critical ATO is hindered by high computational cost and hallucination risk. Meanwhile, reliable domain-specific benchmarks for systematically evaluating cognitive capabilities are still lacking. To address these gaps, we introduce RailVQA-bench, the first VQA benchmark for cab-view visual cognition in ATO, comprising 20,000 single-frame and 1,168 video based QA pairs to evaluate cognitive generalization and interpretability in both static and dynamic scenarios. Furthermore, we propose RailVQA-CoM, a collaborative large-small model framework that combines small-model efficiency with large-model cognition via a transparent three-module architecture and adaptive temporal sampling, improving perceptual generalization and enabling efficient reasoning and planning. Experiments demonstrate that the proposed approach substantially improves performance, enhances interpretability, reduces inference latency, and strengthens cross-domain generalization, while enabling plug-and-play deployment in autonomous driving systems. Code and datasets will be available at https://github.com/Cybereye-bjtu/RailVQA.
Whisper-MLA: Reducing GPU Memory Consumption of ASR Models based on MHA2MLA Conversion
Feb 28, 2026The Transformer-based Whisper model has achieved state-of-the-art performance in Automatic Speech Recognition (ASR). However, its Multi-Head Attention (MHA) mechanism results in significant GPU memory consumption due to the linearly growing Key-Value (KV) cache usage, which is problematic for many applications especially with long-form audio. To address this, we introduce Whisper-MLA, a novel architecture that incorporates Multi-Head Latent Attention (MLA) into the Whisper model. Specifically, we adapt MLA for Whisper's absolute positional embeddings and systematically investigate its application across encoder self-attention, decoder self-attention, and cross-attention modules. Empirical results indicate that applying MLA exclusively to decoder self-attention yields the desired balance between performance and memory efficiency. Our proposed approach allows conversion of a pretrained Whisper model to Whisper-MLA with minimal fine-tuning. Extensive experiments on the LibriSpeech benchmark validate the effectiveness of this conversion, demonstrating that Whisper-MLA reduces the KV cache size by up to 87.5% while maintaining competitive accuracy.
Enhancing Diffusion-Based Quantitatively Controllable Image Generation via Matrix-Form EDM and Adaptive Vicinal Training
Feb 02, 2026Continuous Conditional Diffusion Model (CCDM) is a diffusion-based framework designed to generate high-quality images conditioned on continuous regression labels. Although CCDM has demonstrated clear advantages over prior approaches across a range of datasets, it still exhibits notable limitations and has recently been surpassed by a GAN-based method, namely CcGAN-AVAR. These limitations mainly arise from its reliance on an outdated diffusion framework and its low sampling efficiency due to long sampling trajectories. To address these issues, we propose an improved CCDM framework, termed iCCDM, which incorporates the more advanced \textit{Elucidated Diffusion Model} (EDM) framework with substantial modifications to improve both generation quality and sampling efficiency. Specifically, iCCDM introduces a novel matrix-form EDM formulation together with an adaptive vicinal training strategy. Extensive experiments on four benchmark datasets, spanning image resolutions from $64\times64$ to $256\times256$, demonstrate that iCCDM consistently outperforms existing methods, including state-of-the-art large-scale text-to-image diffusion models (e.g., Stable Diffusion 3, FLUX.1, and Qwen-Image), achieving higher generation quality while significantly reducing sampling cost.
Large Sign Language Models: Toward 3D American Sign Language Translation
Nov 11, 2025We present Large Sign Language Models (LSLM), a novel framework for translating 3D American Sign Language (ASL) by leveraging Large Language Models (LLMs) as the backbone, which can benefit hearing-impaired individuals' virtual communication. Unlike existing sign language recognition methods that rely on 2D video, our approach directly utilizes 3D sign language data to capture rich spatial, gestural, and depth information in 3D scenes. This enables more accurate and resilient translation, enhancing digital communication accessibility for the hearing-impaired community. Beyond the task of ASL translation, our work explores the integration of complex, embodied multimodal languages into the processing capabilities of LLMs, moving beyond purely text-based inputs to broaden their understanding of human communication. We investigate both direct translation from 3D gesture features to text and an instruction-guided setting where translations can be modulated by external prompts, offering greater flexibility. This work provides a foundational step toward inclusive, multimodal intelligent systems capable of understanding diverse forms of language.
Physics-Informed Neural Networks and Neural Operators for Parametric PDEs: A Human-AI Collaborative Analysis
Nov 06, 2025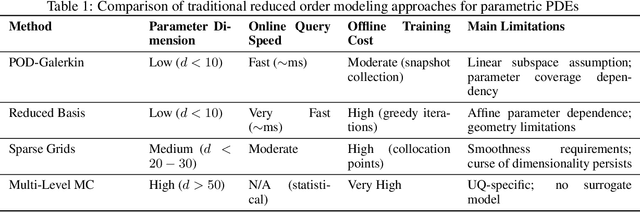
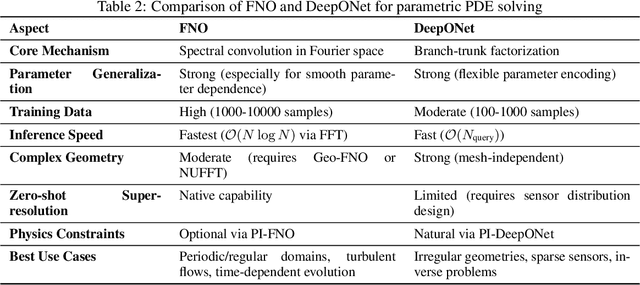
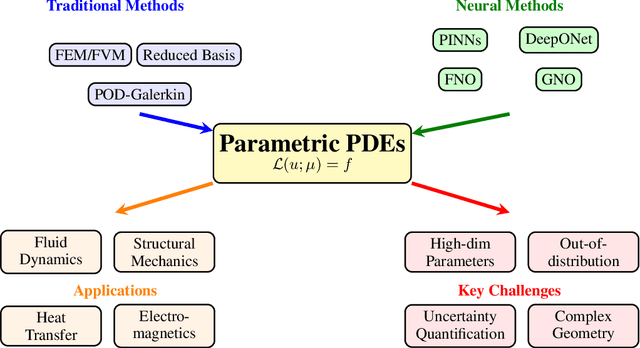
PDEs arise ubiquitously in science and engineering, where solutions depend on parameters (physical properties, boundary conditions, geometry). Traditional numerical methods require re-solving the PDE for each parameter, making parameter space exploration prohibitively expensive. Recent machine learning advances, particularly physics-informed neural networks (PINNs) and neural operators, have revolutionized parametric PDE solving by learning solution operators that generalize across parameter spaces. We critically analyze two main paradigms: (1) PINNs, which embed physical laws as soft constraints and excel at inverse problems with sparse data, and (2) neural operators (e.g., DeepONet, Fourier Neural Operator), which learn mappings between infinite-dimensional function spaces and achieve unprecedented generalization. Through comparisons across fluid dynamics, solid mechanics, heat transfer, and electromagnetics, we show neural operators can achieve computational speedups of $10^3$ to $10^5$ times faster than traditional solvers for multi-query scenarios, while maintaining comparable accuracy. We provide practical guidance for method selection, discuss theoretical foundations (universal approximation, convergence), and identify critical open challenges: high-dimensional parameters, complex geometries, and out-of-distribution generalization. This work establishes a unified framework for understanding parametric PDE solvers via operator learning, offering a comprehensive, incrementally updated resource for this rapidly evolving field
One-shot Face Sketch Synthesis in the Wild via Generative Diffusion Prior and Instruction Tuning
Jun 18, 2025
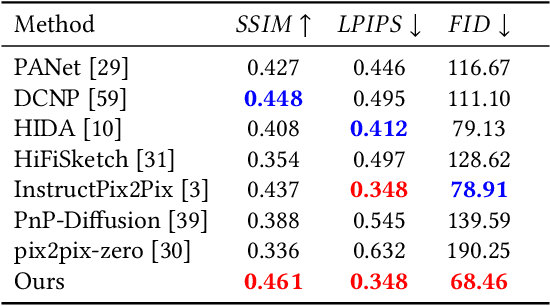


Face sketch synthesis is a technique aimed at converting face photos into sketches. Existing face sketch synthesis research mainly relies on training with numerous photo-sketch sample pairs from existing datasets. However, these large-scale discriminative learning methods will have to face problems such as data scarcity and high human labor costs. Once the training data becomes scarce, their generative performance significantly degrades. In this paper, we propose a one-shot face sketch synthesis method based on diffusion models. We optimize text instructions on a diffusion model using face photo-sketch image pairs. Then, the instructions derived through gradient-based optimization are used for inference. To simulate real-world scenarios more accurately and evaluate method effectiveness more comprehensively, we introduce a new benchmark named One-shot Face Sketch Dataset (OS-Sketch). The benchmark consists of 400 pairs of face photo-sketch images, including sketches with different styles and photos with different backgrounds, ages, sexes, expressions, illumination, etc. For a solid out-of-distribution evaluation, we select only one pair of images for training at each time, with the rest used for inference. Extensive experiments demonstrate that the proposed method can convert various photos into realistic and highly consistent sketches in a one-shot context. Compared to other methods, our approach offers greater convenience and broader applicability. The dataset will be available at: https://github.com/HanWu3125/OS-Sketch
Regularized Adaptive Graph Learning for Large-Scale Traffic Forecasting
Jun 08, 2025Traffic prediction is a critical task in spatial-temporal forecasting with broad applications in travel planning and urban management. Adaptive graph convolution networks have emerged as mainstream solutions due to their ability to learn node embeddings in a data-driven manner and capture complex latent dependencies. However, existing adaptive graph learning methods for traffic forecasting often either ignore the regularization of node embeddings, which account for a significant proportion of model parameters, or face scalability issues from expensive graph convolution operations. To address these challenges, we propose a Regularized Adaptive Graph Learning (RAGL) model. First, we introduce a regularized adaptive graph learning framework that synergizes Stochastic Shared Embedding (SSE) and adaptive graph convolution via a residual difference mechanism, achieving both embedding regularization and noise suppression. Second, to ensure scalability on large road networks, we develop the Efficient Cosine Operator (ECO), which performs graph convolution based on the cosine similarity of regularized embeddings with linear time complexity. Extensive experiments on four large-scale real-world traffic datasets show that RAGL consistently outperforms state-of-the-art methods in terms of prediction accuracy and exhibits competitive computational efficiency.
Neuron-level Balance between Stability and Plasticity in Deep Reinforcement Learning
Apr 09, 2025In contrast to the human ability to continuously acquire knowledge, agents struggle with the stability-plasticity dilemma in deep reinforcement learning (DRL), which refers to the trade-off between retaining existing skills (stability) and learning new knowledge (plasticity). Current methods focus on balancing these two aspects at the network level, lacking sufficient differentiation and fine-grained control of individual neurons. To overcome this limitation, we propose Neuron-level Balance between Stability and Plasticity (NBSP) method, by taking inspiration from the observation that specific neurons are strongly relevant to task-relevant skills. Specifically, NBSP first (1) defines and identifies RL skill neurons that are crucial for knowledge retention through a goal-oriented method, and then (2) introduces a framework by employing gradient masking and experience replay techniques targeting these neurons to preserve the encoded existing skills while enabling adaptation to new tasks. Numerous experimental results on the Meta-World and Atari benchmarks demonstrate that NBSP significantly outperforms existing approaches in balancing stability and plasticity.