 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularized Adaptive Graph Learning for Large-Scale Traffic Forecasting
Jun 08, 2025Traffic prediction is a critical task in spatial-temporal forecasting with broad applications in travel planning and urban management. Adaptive graph convolution networks have emerged as mainstream solutions due to their ability to learn node embeddings in a data-driven manner and capture complex latent dependencies. However, existing adaptive graph learning methods for traffic forecasting often either ignore the regularization of node embeddings, which account for a significant proportion of model parameters, or face scalability issues from expensive graph convolution operations. To address these challenges, we propose a Regularized Adaptive Graph Learning (RAGL) model. First, we introduce a regularized adaptive graph learning framework that synergizes Stochastic Shared Embedding (SSE) and adaptive graph convolution via a residual difference mechanism, achieving both embedding regularization and noise suppression. Second, to ensure scalability on large road networks, we develop the Efficient Cosine Operator (ECO), which performs graph convolution based on the cosine similarity of regularized embeddings with linear time complexity. Extensive experiments on four large-scale real-world traffic datasets show that RAGL consistently outperforms state-of-the-art methods in terms of prediction accuracy and exhibits competitive computational efficiency.
GraphSparseNet: a Novel Method for Large Scale Trafffic Flow Prediction
Feb 27, 2025



Traffic flow forecasting is a critical spatio-temporal data mining task with wide-ranging applications in intelligent route planning and dynamic traffic management. Recent advancements in deep learning, particularly through Graph Neural Networks (GNNs), have significantly enhanced the accuracy of these forecasts by capturing complex spatio-temporal dynamics. However, the scalability of GNNs remains a challenge due to their exponential growth in model complexity with increasing nodes in the graph. Existing methods to address this issue, including sparsification, decomposition, and kernel-based approaches, either do not fully resolve the complexity issue or risk compromising predictive accuracy. This paper introduces GraphSparseNet (GSNet), a novel framework designed to improve both the scalability and accuracy of GNN-based traffic forecasting models. GraphSparseNet is comprised of two core modules: the Feature Extractor and the Relational Compressor. These modules operate with linear time and space complexity, thereby reducing the overall computational complexity of the model to a linear scale. Our extensive experiments on multiple real-world datasets demonstrate that GraphSparseNet not only significantly reduces training time by 3.51x compared to state-of-the-art linear models but also maintains high predictive performance.
Universal Model for Multi-Domain Medical Image Retrieval
Jul 14, 2020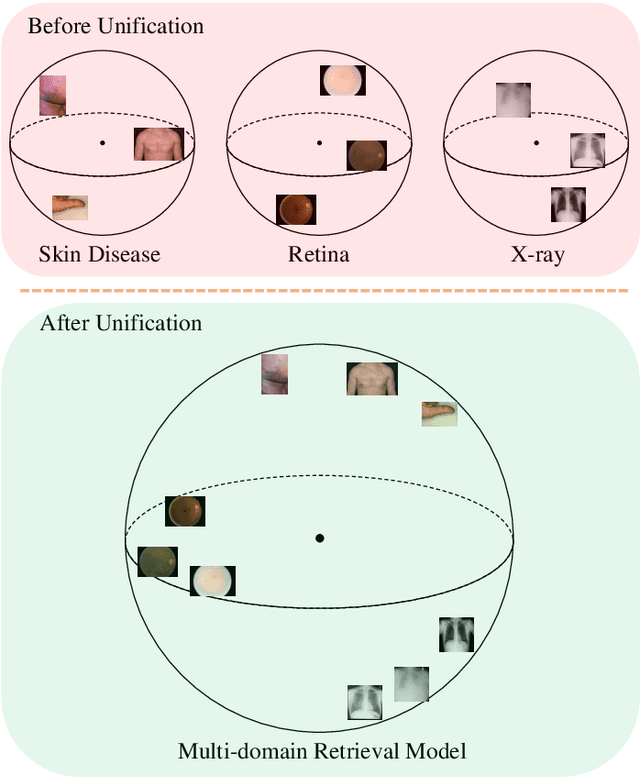
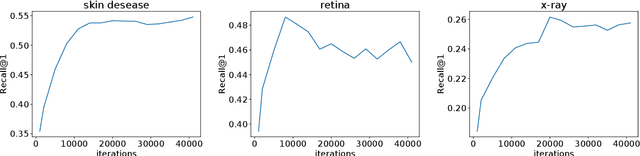
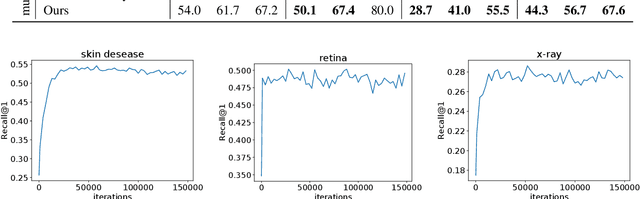
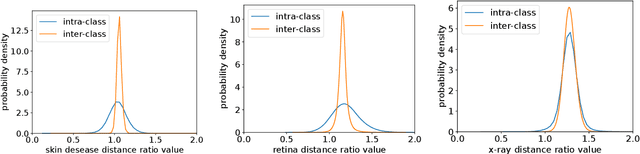
Medical Image Retrieval (MIR) helps doctors quickly find similar patients' data, which can considerably aid the diagnosis process. MIR is becoming increasingly helpful due to the wide use of digital imaging modalities and the growth of the medical image repositories. However, the popularity of various digital imaging modalities in hospitals also poses several challenges to MIR. Usually, one image retrieval model is only trained to handle images from one modality or one source. When there are needs to retrieve medical images from several sources or domains, multiple retrieval models need to be maintained, which is cost ineffective. In this paper, we study an important but unexplored task: how to train one MIR model that is applicable to medical images from multiple domains? Simply fusing the training data from multiple domains cannot solve this problem because some domains become over-fit sooner when trained together using existing methods. Therefore, we propose to distill the knowledge in multiple specialist MIR models into a single multi-domain MIR model via universal embedding to solve this problem. Using skin disease, x-ray, and retina image datasets, we validate that our proposed universal model can effectively accomplish multi-domain MIR.
Deeply Matting-based Dual Generative Adversarial Network for Image and Document Label Supervision
Sep 19, 2019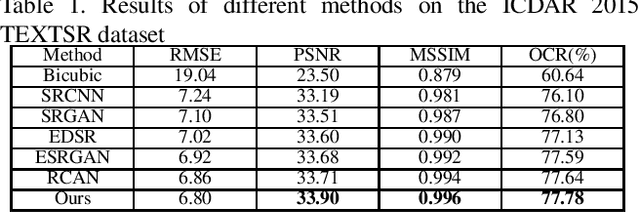
Although many methods have been proposed to deal with nature image super-resolution (SR) and get impressive performance, the text images SR is not good due to their ignorance of document images. In this paper, we propose a matting-based dual generative adversarial network (mdGAN) for document image SR. Firstly, the input image is decomposed into document text, foreground and background layers using deep image matting. Then two parallel branches are constructed to recover text boundary information and color information respectively. Furthermore, in order to improve the restoration accuracy of characters in output image, we use the input image's corresponding ground truth text label as extra supervise information to refine the two-branch networks during training. Experiments on real text images demonstrate that our method outperforms several state-of-the-art methods quantitatively and qualitatively.
Neural Collective Entity Linking Based on Recurrent Random Walk Network Learning
Jun 20, 2019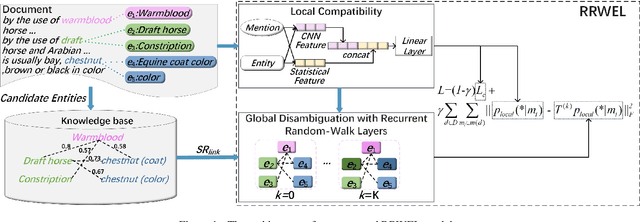
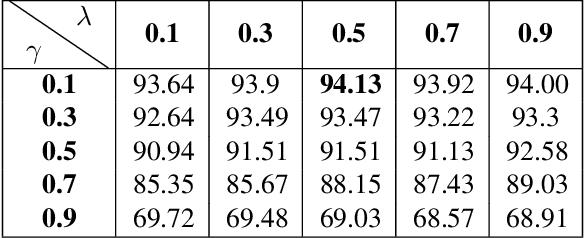
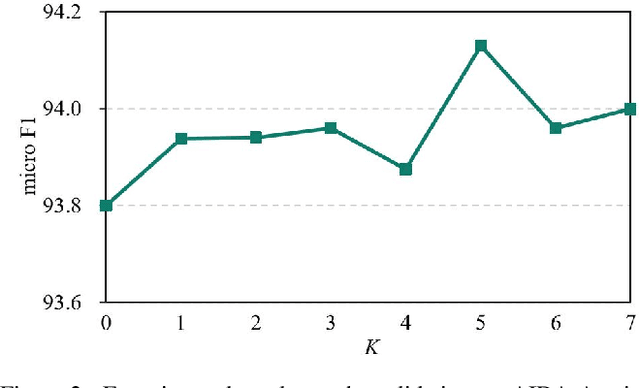
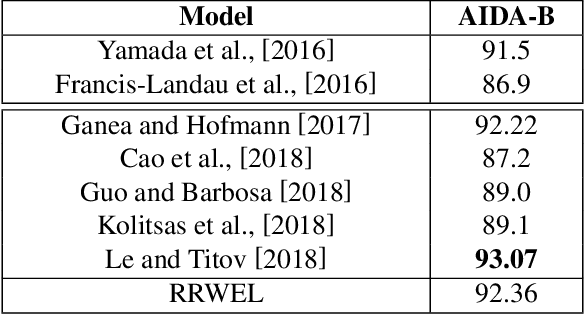
Benefiting from the excellent ability of neural networks on learning semantic representations, existing studies for entity linking (EL) have resorted to neural networks to exploit both the local mention-to-entity compatibility and the global interdependence between different EL decisions for target entity disambiguation. However, most neural collective EL methods depend entirely upon neural networks to automatically model the semantic dependencies between different EL decisions, which lack of the guidance from external knowledge. In this paper, we propose a novel end-to-end neural network with recurrent random-walk layers for collective EL, which introduces external knowledge to model the semantic interdependence between different EL decisions. Specifically, we first establish a model based on local context features, and then stack random-walk layers to reinforce the evidence for related EL decisions into high-probability decisions, where the semantic interdependence between candidate entities is mainly induced from an external knowledge base. Finally, a semantic regularizer that preserves the collective EL decisions consistency is incorporated into the conventional objective function, so that the external knowledge base can be fully exploited in collective EL decisions. Experimental results and in-depth analysis on various datasets show that our model achieves better performance than other state-of-the-art models. Our code and data are released at \url{https://github.com/DeepLearnXMU/RRWEL}.