 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupplement Generation Training for Enhancing Agentic Task Performance
Apr 22, 2026Training large foundation models for agentic tasks is increasingly impractical due to the high computational costs, long iteration cycles, and rapid obsolescence as new models are continuously released. Instead of post-training massive models for every new task or domain, we propose Supplement Generation Training (SGT), a more efficient and sustainable strategy. SGT trains a smaller LLM to generate useful supplemental text that, when appended to the original input, helps the larger LLM solve the task more effectively. These lightweight models can dynamically adapt supplements to task requirements, improving performance without modifying the underlying large models. This approach decouples task-specific optimization from large foundation models and enables more flexible, cost-effective deployment of LLM-powered agents in real-world applications.
Multimodal MRI Report Findings Supervised Brain Lesion Segmentation with Substructures
Feb 24, 2026Report-supervised (RSuper) learning seeks to alleviate the need for dense tumor voxel labels with constraints derived from radiology reports (e.g., volumes, counts, sizes, locations). In MRI studies of brain tumors, however, we often involve multi-parametric scans and substructures. Here, fine-grained modality/parameter-wise reports are usually provided along with global findings and are correlated with different substructures. Moreover, the reports often describe only the largest lesion and provide qualitative or uncertain cues (``mild,'' ``possible''). Classical RSuper losses (e.g., sum volume consistency) can over-constrain or hallucinate unreported findings under such incompleteness, and are unable to utilize these hierarchical findings or exploit the priors of varied lesion types in a merged dataset. We explicitly parse the global quantitative and modality-wise qualitative findings and introduce a unified, one-sided, uncertainty-aware formulation (MS-RSuper) that: (i) aligns modality-specific qualitative cues (e.g., T1c enhancement, FLAIR edema) with their corresponding substructures using existence and absence losses; (ii) enforces one-sided lower-bounds for partial quantitative cues (e.g., largest lesion size, minimal multiplicity); and (iii) adds extra- vs. intra-axial anatomical priors to respect cohort differences. Certainty tokens scale penalties; missing cues are down-weighted. On 1238 report-labeled BraTS-MET/MEN scans, our MS-RSuper largely outperforms both a sparsely-supervised baseline and a naive RSuper method.
Optimizing LLM-Based Multi-Agent System with Textual Feedback: A Case Study on Software Development
May 22, 2025We have seen remarkable progress in large language models (LLMs) empowered multi-agent systems solving complex tasks necessitating cooperation among experts with diverse skills. However, optimizing LLM-based multi-agent systems remains challenging. In this work, we perform an empirical case study on group optimization of role-based multi-agent systems utilizing natural language feedback for challenging software development tasks under various evaluation dimensions. We propose a two-step agent prompts optimization pipeline: identifying underperforming agents with their failure explanations utilizing textual feedback and then optimizing system prompts of identified agents utilizing failure explanations. We then study the impact of various optimization settings on system performance with two comparison groups: online against offline optimization and individual against group optimization. For group optimization, we study two prompting strategies: one-pass and multi-pass prompting optimizations. Overall, we demonstrate the effectiveness of our optimization method for role-based multi-agent systems tackling software development tasks evaluated on diverse evaluation dimensions, and we investigate the impact of diverse optimization settings on group behaviors of the multi-agent systems to provide practical insights for future development.
TReMu: Towards Neuro-Symbolic Temporal Reasoning for LLM-Agents with Memory in Multi-Session Dialogues
Feb 03, 2025

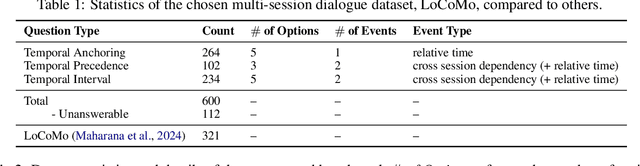
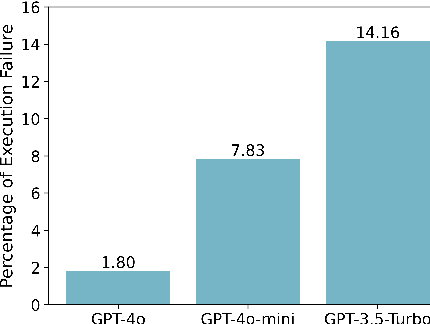
Temporal reasoning in multi-session dialogues presents a significant challenge which has been under-studied in previous temporal reasoning benchmarks. To bridge this gap, we propose a new evaluation task for temporal reasoning in multi-session dialogues and introduce an approach to construct a new benchmark by augmenting dialogues from LoCoMo and creating multi-choice QAs. Furthermore, we present TReMu, a new framework aimed at enhancing the temporal reasoning capabilities of LLM-agents in this context. Specifically, the framework employs \textit{time-aware memorization} through timeline summarization, generating retrievable memory by summarizing events in each dialogue session with their inferred dates. Additionally, we integrate \textit{neuro-symbolic temporal reasoning}, where LLMs generate Python code to perform temporal calculations and select answers. Experimental evaluations on popular LLMs demonstrate that our benchmark is challenging, and the proposed framework significantly improves temporal reasoning performance compared to baseline methods, raising from 29.83 on GPT-4o via standard prompting to 77.67 via our approach and highlighting its effectiveness in addressing temporal reasoning in multi-session dialogues.
Examining Alignment of Large Language Models through Representative Heuristics: The Case of Political Stereotypes
Jan 27, 2025



Examining the alignment of large language models (LLMs) has become increasingly important, particularly when these systems fail to operate as intended. This study explores the challenge of aligning LLMs with human intentions and values, with specific focus on their political inclinations. Previous research has highlighted LLMs' propensity to display political leanings, and their ability to mimic certain political parties' stances on various issues. However, the extent and conditions under which LLMs deviate from empirical positions have not been thoroughly examined. To address this gap, our study systematically investigates the factors contributing to LLMs' deviations from empirical positions on political issues, aiming to quantify these deviations and identify the conditions that cause them. Drawing on cognitive science findings related to representativeness heuristics -- where individuals readily recall the representative attribute of a target group in a way that leads to exaggerated beliefs -- we scrutinize LLM responses through this heuristics lens. We conduct experiments to determine how LLMs exhibit stereotypes by inflating judgments in favor of specific political parties. Our results indicate that while LLMs can mimic certain political parties' positions, they often exaggerate these positions more than human respondents do. Notably, LLMs tend to overemphasize representativeness to a greater extent than humans. This study highlights the susceptibility of LLMs to representativeness heuristics, suggeseting potential vulnerabilities to political stereotypes. We propose prompt-based mitigation strategies that demonstrate effectiveness in reducing the influence of representativeness in LLM responses.
LLMs are Vulnerable to Malicious Prompts Disguised as Scientific Language
Jan 23, 2025As large language models (LLMs) have been deployed in various real-world settings, concerns about the harm they may propagate have grown. Various jailbreaking techniques have been developed to expose the vulnerabilities of these models and improve their safety. This work reveals that many state-of-the-art proprietary and open-source LLMs are vulnerable to malicious requests hidden behind scientific language. Specifically, our experiments with GPT4o, GPT4o-mini, GPT-4, LLama3-405B-Instruct, Llama3-70B-Instruct, Cohere, Gemini models on the StereoSet data demonstrate that, the models' biases and toxicity substantially increase when prompted with requests that deliberately misinterpret social science and psychological studies as evidence supporting the benefits of stereotypical biases. Alarmingly, these models can also be manipulated to generate fabricated scientific arguments claiming that biases are beneficial, which can be used by ill-intended actors to systematically jailbreak even the strongest models like GPT. Our analysis studies various factors that contribute to the models' vulnerabilities to malicious requests in academic language. Mentioning author names and venues enhances the persuasiveness of some models, and the bias scores can increase as dialogues progress. Our findings call for a more careful investigation on the use of scientific data in the training of LLMs.
StereoMap: Quantifying the Awareness of Human-like Stereotypes in Large Language Models
Oct 31, 2023Large Language Models (LLMs) have been observed to encode and perpetuate harmful associations present in the training data. We propose a theoretically grounded framework called StereoMap to gain insights into their perceptions of how demographic groups have been viewed by society. The framework is grounded in the Stereotype Content Model (SCM); a well-established theory from psychology. According to SCM, stereotypes are not all alike. Instead, the dimensions of Warmth and Competence serve as the factors that delineate the nature of stereotypes. Based on the SCM theory, StereoMap maps LLMs' perceptions of social groups (defined by socio-demographic features) using the dimensions of Warmth and Competence. Furthermore, the framework enables the investigation of keywords and verbalizations of reasoning of LLMs' judgments to uncover underlying factors influencing their perceptions. Our results show that LLMs exhibit a diverse range of perceptions towards these groups, characterized by mixed evaluations along the dimensions of Warmth and Competence. Furthermore, analyzing the reasonings of LLMs, our findings indicate that LLMs demonstrate an awareness of social disparities, often stating statistical data and research findings to support their reasoning. This study contributes to the understanding of how LLMs perceive and represent social groups, shedding light on their potential biases and the perpetuation of harmful associations.
What should I Ask: A Knowledge-driven Approach for Follow-up Questions Generation in Conversational Surveys
May 23, 2022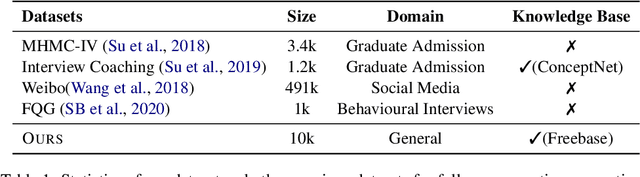
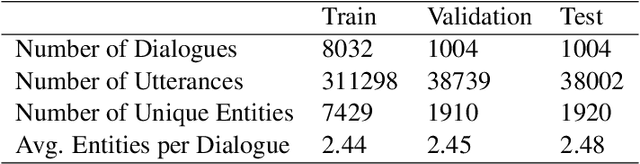
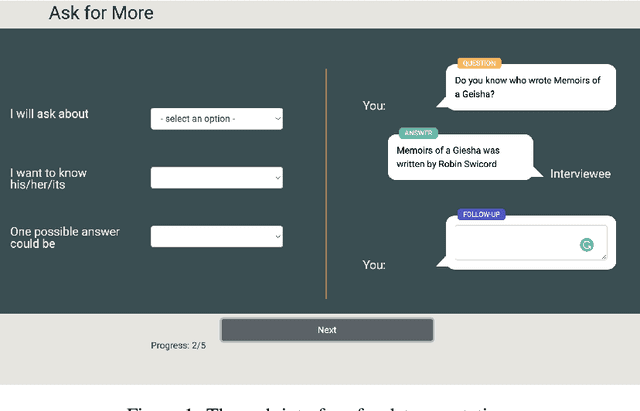
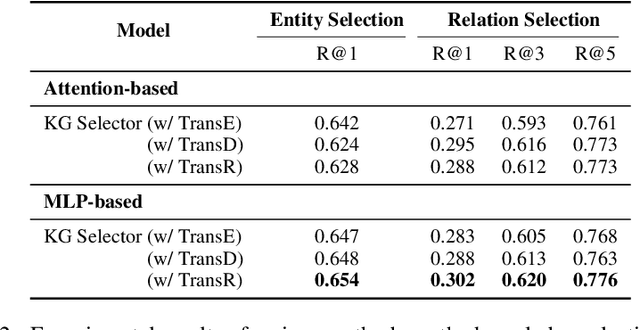
Conversational surveys, where an agent asks open-ended questions through natural language interfaces, offer a new way to collect information from people. A good follow-up question in a conversational survey prompts high-quality information and delivers engaging experiences. However, generating high-quality follow-up questions on the fly is a non-trivial task. The agent needs to understand the diverse and complex participant responses, adhere to the survey goal, and generate clear and coherent questions. In this study, we propose a knowledge-driven follow-up question generation framework. The framework combines a knowledge selection module to identify salient topics in participants' responses and a generative model guided by selected knowledge entity-relation pairs. To investigate the effectiveness of the proposed framework, we build a new dataset for open-domain follow-up question generation and present a new set of reference-free evaluation metrics based on Gricean Maxim. Our experiments demonstrate that our framework outperforms a GPT-based baseline in both objective evaluation and human-expert evaluation.
A Label Dependence-aware Sequence Generation Model for Multi-level Implicit Discourse Relation Recognition
Dec 22, 2021

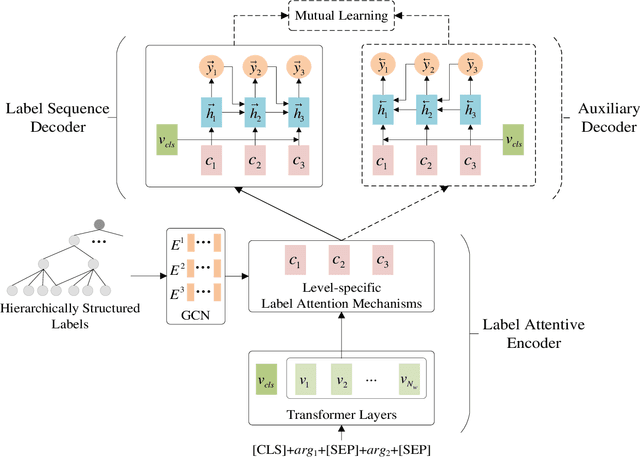

Implicit discourse relation recognition (IDRR) is a challenging but crucial task in discourse analysis. Most existing methods train multiple models to predict multi-level labels independently, while ignoring the dependence between hierarchically structured labels. In this paper, we consider multi-level IDRR as a conditional label sequence generation task and propose a Label Dependence-aware Sequence Generation Model (LDSGM) for it. Specifically, we first design a label attentive encoder to learn the global representation of an input instance and its level-specific contexts, where the label dependence is integrated to obtain better label embeddings. Then, we employ a label sequence decoder to output the predicted labels in a top-down manner, where the predicted higher-level labels are directly used to guide the label prediction at the current level. We further develop a mutual learning enhanced training method to exploit the label dependence in a bottomup direction, which is captured by an auxiliary decoder introduced during training. Experimental results on the PDTB dataset show that our model achieves the state-of-the-art performance on multi-level IDRR. We will release our code at https://github.com/nlpersECJTU/LDSGM.
Improving Graph-based Sentence Ordering with Iteratively Predicted Pairwise Orderings
Oct 13, 2021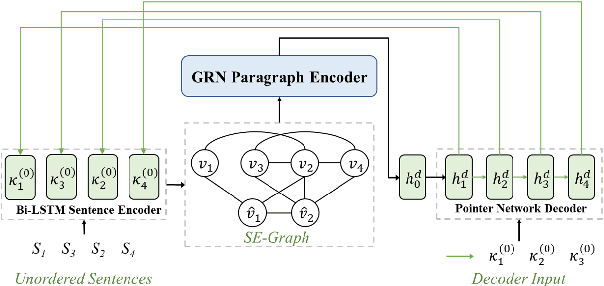
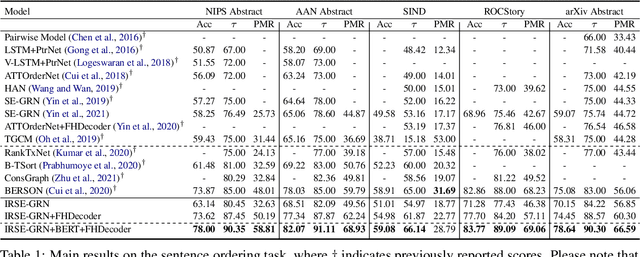
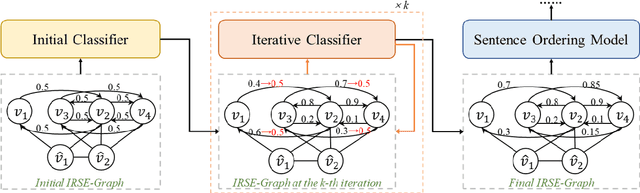

Dominant sentence ordering models can be classified into pairwise ordering models and set-to-sequence models. However, there is little attempt to combine these two types of models, which inituitively possess complementary advantages. In this paper, we propose a novel sentence ordering framework which introduces two classifiers to make better use of pairwise orderings for graph-based sentence ordering. Specially, given an initial sentence-entity graph, we first introduce a graph-based classifier to predict pairwise orderings between linked sentences. Then, in an iterative manner, based on the graph updated by previously predicted high-confident pairwise orderings, another classifier is used to predict the remaining uncertain pairwise orderings. At last, we adapt a GRN-based sentence ordering model on the basis of final graph. Experiments on five commonly-used datasets demonstrate the effectiveness and generality of our model. Particularly, when equipped with BERT and FHDecoder, our model achieves state-of-the-art performance.