 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning universal approximations for partial differential equations with Physics-Informed Broad Learning System
Jun 18, 2026Partial differential equations (PDEs) play a central role in modeling complex physical, biological, and engineering systems. While traditional numerical solvers are robust, they often incur prohibitive computational costs due to mesh dependencies, whereas recent Physics-Informed Neural Networks (PINNs) offer a mesh-free alternative but frequently suffer from slow convergence and optimization instability. To bridge this gap, this article proposes the Physics-Informed Broad Learning System (PIBLS), a novel backpropagation-free framework that reformulates PDE solving as a direct least-squares optimization. We improved an algorithm within this framework to handle nonlinear PDEs efficiently and provide a rigorous mathematical proof establishing the universal approximation property of PIBLS for these equations. Experiments on linear and nonlinear PDEs demonstrate that PIBLS is one to three orders of magnitude faster than conventional PINNs while achieving significantly higher solution accuracy. This framework provides a computationally efficient paradigm for scientific machine learning, offering a practical, high-speed alternative for real-time simulation and design optimization tasks.
Vicinal Feature Statistics Augmentation for Federated 3D Medical Volume Segmentation
Oct 23, 2023Federated learning (FL) enables multiple client medical institutes collaboratively train a deep learning (DL) model with privacy protection. However, the performance of FL can be constrained by the limited availability of labeled data in small institutes and the heterogeneous (i.e., non-i.i.d.) data distribution across institutes. Though data augmentation has been a proven technique to boost the generalization capabilities of conventional centralized DL as a "free lunch", its application in FL is largely underexplored. Notably, constrained by costly labeling, 3D medical segmentation generally relies on data augmentation. In this work, we aim to develop a vicinal feature-level data augmentation (VFDA) scheme to efficiently alleviate the local feature shift and facilitate collaborative training for privacy-aware FL segmentation. We take both the inner- and inter-institute divergence into consideration, without the need for cross-institute transfer of raw data or their mixup. Specifically, we exploit the batch-wise feature statistics (e.g., mean and standard deviation) in each institute to abstractly represent the discrepancy of data, and model each feature statistic probabilistically via a Gaussian prototype, with the mean corresponding to the original statistic and the variance quantifying the augmentation scope. From the vicinal risk minimization perspective, novel feature statistics can be drawn from the Gaussian distribution to fulfill augmentation. The variance is explicitly derived by the data bias in each individual institute and the underlying feature statistics characterized by all participating institutes. The added-on VFDA consistently yielded marked improvements over six advanced FL methods on both 3D brain tumor and cardiac segmentation.
* 28th biennial international conference on Information Processing in Medical Imaging (IPMI 2023): Oral Paper
Constraining Pseudo-label in Self-training Unsupervised Domain Adaptation with Energy-based Model
Aug 26, 2022Deep learning is usually data starved, and the unsupervised domain adaptation (UDA) is developed to introduce the knowledge in the labeled source domain to the unlabeled target domain. Recently, deep self-training presents a powerful means for UDA, involving an iterative process of predicting the target domain and then taking the confident predictions as hard pseudo-labels for retraining. However, the pseudo-labels are usually unreliable, thus easily leading to deviated solutions with propagated errors. In this paper, we resort to the energy-based model and constrain the training of the unlabeled target sample with an energy function minimization objective. It can be achieved via a simple additional regularization or an energy-based loss. This framework allows us to gain the benefits of the energy-based model, while retaining strong discriminative performance following a plug-and-play fashion. The convergence property and its connection with classification expectation minimization are investigated. We deliver extensive experiments on the most popular and large-scale UDA benchmarks of image classification as well as semantic segmentation to demonstrate its generality and effectiveness.
Recursively Conditional Gaussian for Ordinal Unsupervised Domain Adaptation
Aug 17, 2021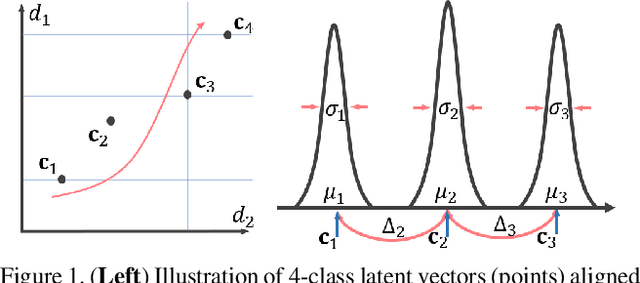
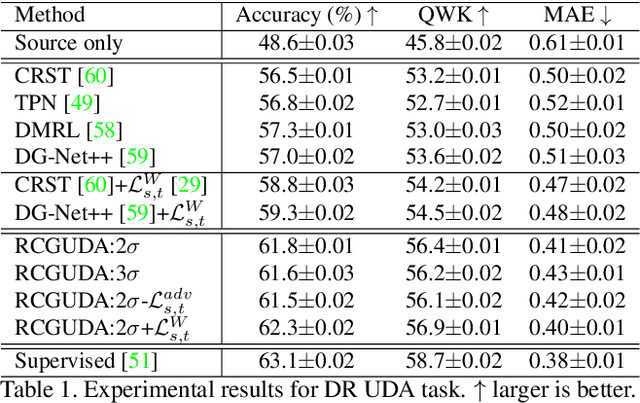
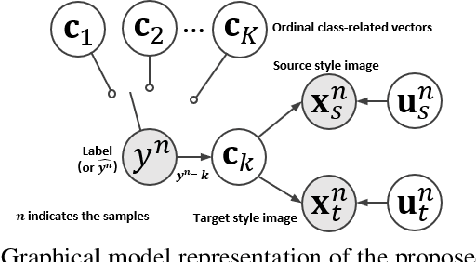
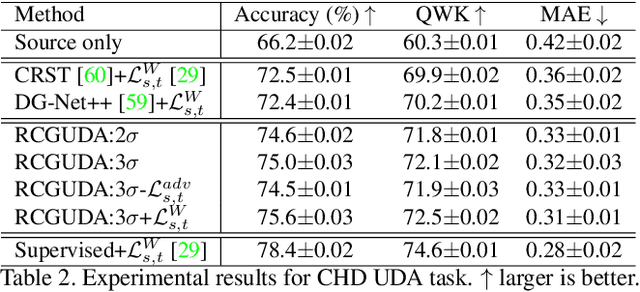
The unsupervised domain adaptation (UDA) has been widely adopted to alleviate the data scalability issue, while the existing works usually focus on classifying independently discrete labels. However, in many tasks (e.g., medical diagnosis), the labels are discrete and successively distributed. The UDA for ordinal classification requires inducing non-trivial ordinal distribution prior to the latent space. Target for this, the partially ordered set (poset) is defined for constraining the latent vector. Instead of the typically i.i.d. Gaussian latent prior, in this work, a recursively conditional Gaussian (RCG) set is adapted for ordered constraint modeling, which admits a tractable joint distribution prior. Furthermore, we are able to control the density of content vector that violates the poset constraints by a simple "three-sigma rule". We explicitly disentangle the cross-domain images into a shared ordinal prior induced ordinal content space and two separate source/target ordinal-unrelated spaces, and the self-training is worked on the shared space exclusively for ordinal-aware domain alignment. Extensive experiments on UDA medical diagnoses and facial age estimation demonstrate its effectiveness.
Adversarial Unsupervised Domain Adaptation with Conditional and Label Shift: Infer, Align and Iterate
Aug 02, 2021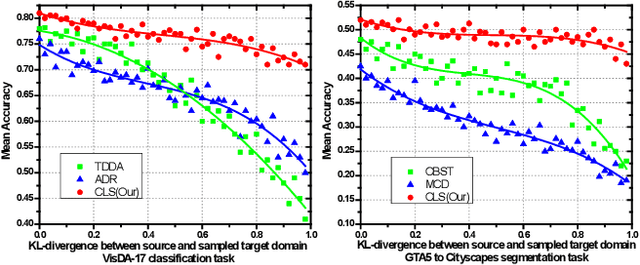
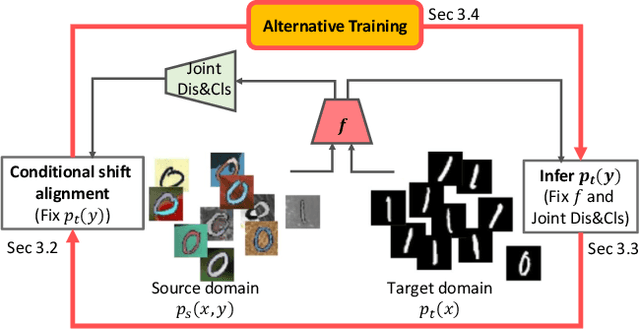
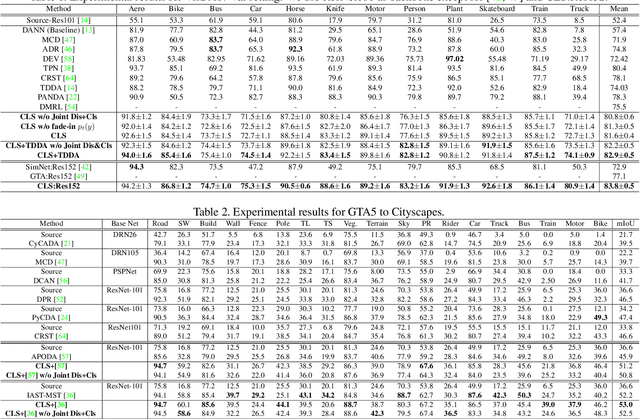
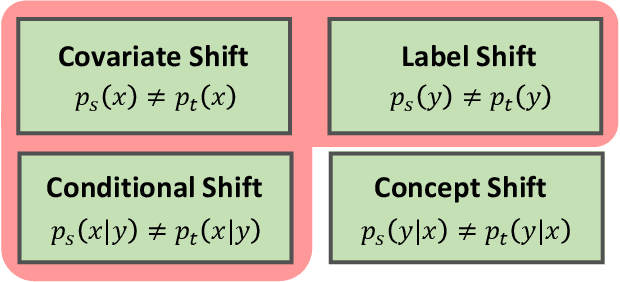
In this work, we propose an adversarial unsupervised domain adaptation (UDA) approach with the inherent conditional and label shifts, in which we aim to align the distributions w.r.t. both $p(x|y)$ and $p(y)$. Since the label is inaccessible in the target domain, the conventional adversarial UDA assumes $p(y)$ is invariant across domains, and relies on aligning $p(x)$ as an alternative to the $p(x|y)$ alignment. To address this, we provide a thorough theoretical and empirical analysis of the conventional adversarial UDA methods under both conditional and label shifts, and propose a novel and practical alternative optimization scheme for adversarial UDA. Specifically, we infer the marginal $p(y)$ and align $p(x|y)$ iteratively in the training, and precisely align the posterior $p(y|x)$ in testing. Our experimental results demonstrate its effectiveness on both classification and segmentation UDA, and partial UDA.
Embedding Semantic Hierarchy in Discrete Optimal Transport for Risk Minimization
Apr 30, 2021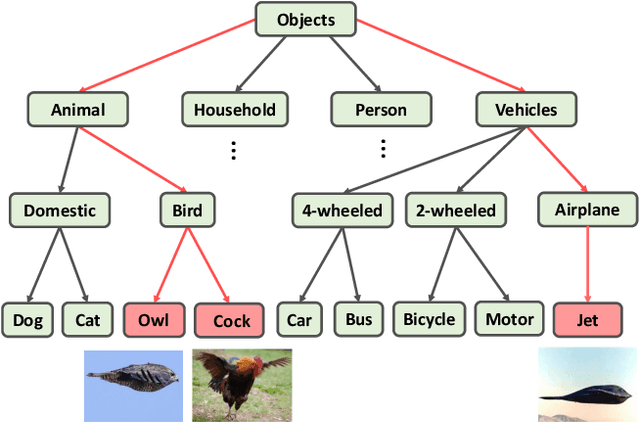
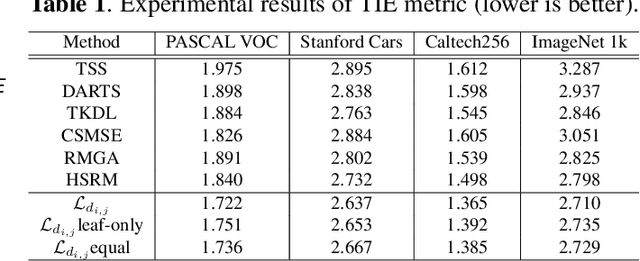
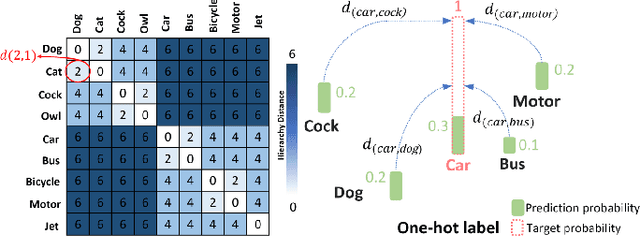
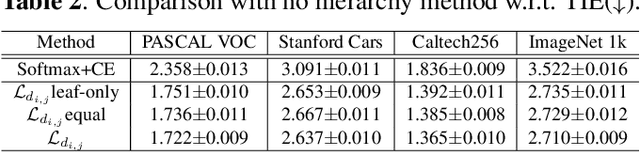
The widely-used cross-entropy (CE) loss-based deep networks achieved significant progress w.r.t. the classification accuracy. However, the CE loss can essentially ignore the risk of misclassification which is usually measured by the distance between the prediction and label in a semantic hierarchical tree. In this paper, we propose to incorporate the risk-aware inter-class correlation in a discrete optimal transport (DOT) training framework by configuring its ground distance matrix. The ground distance matrix can be pre-defined following a priori of hierarchical semantic risk. Specifically, we define the tree induced error (TIE) on a hierarchical semantic tree and extend it to its increasing function from the optimization perspective. The semantic similarity in each level of a tree is integrated with the information gain. We achieve promising results on several large scale image classification tasks with a semantic tree structure in a plug and play manner.
Subtype-aware Unsupervised Domain Adaptation for Medical Diagnosis
Jan 11, 2021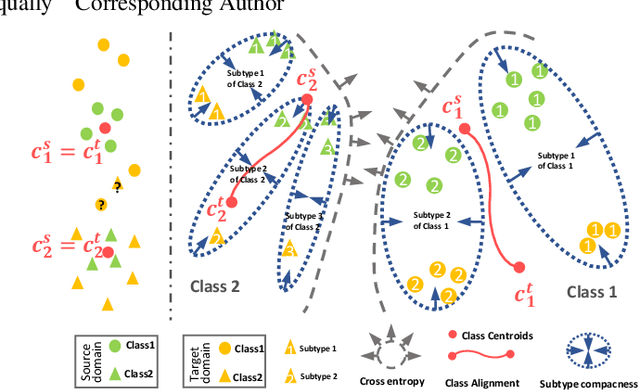
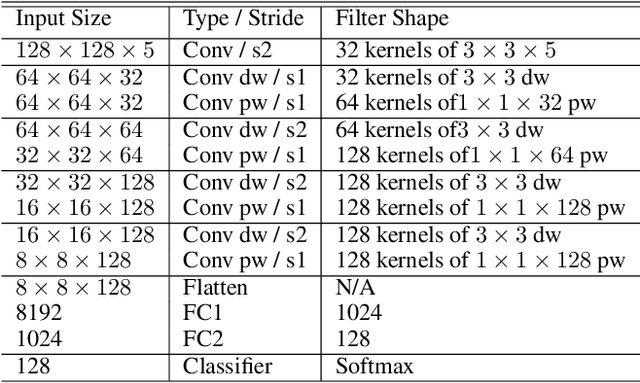
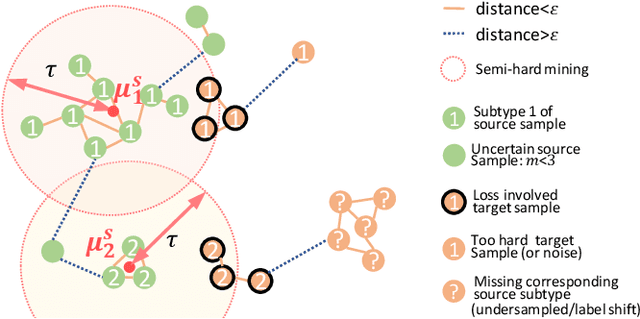
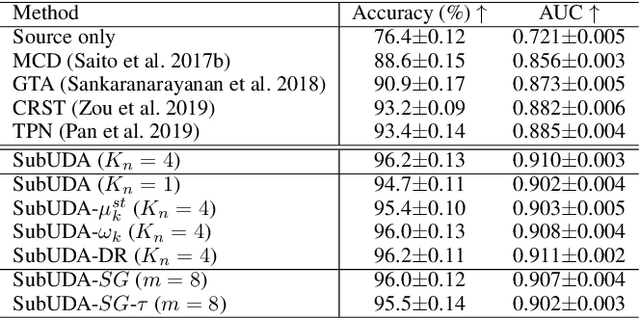
Recent advances in unsupervised domain adaptation (UDA) show that transferable prototypical learning presents a powerful means for class conditional alignment, which encourages the closeness of cross-domain class centroids. However, the cross-domain inner-class compactness and the underlying fine-grained subtype structure remained largely underexplored. In this work, we propose to adaptively carry out the fine-grained subtype-aware alignment by explicitly enforcing the class-wise separation and subtype-wise compactness with intermediate pseudo labels. Our key insight is that the unlabeled subtypes of a class can be divergent to one another with different conditional and label shifts, while inheriting the local proximity within a subtype. The cases of with or without the prior information on subtype numbers are investigated to discover the underlying subtype structure in an online fashion. The proposed subtype-aware dynamic UDA achieves promising results on medical diagnosis tasks.
Identity-aware Facial Expression Recognition in Compressed Video
Jan 07, 2021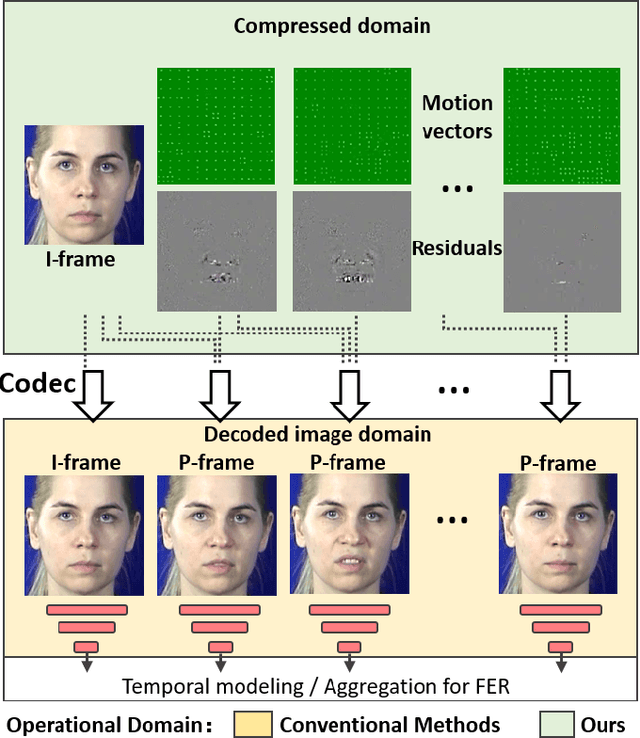
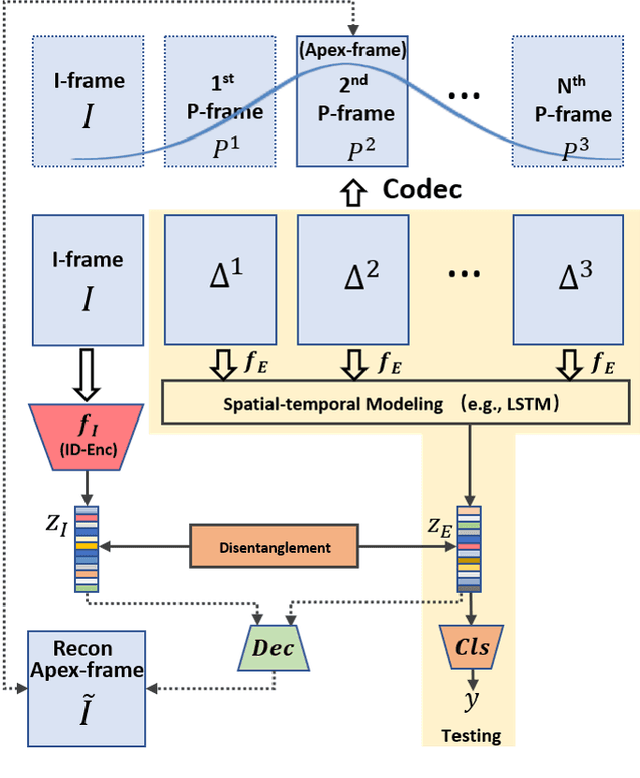
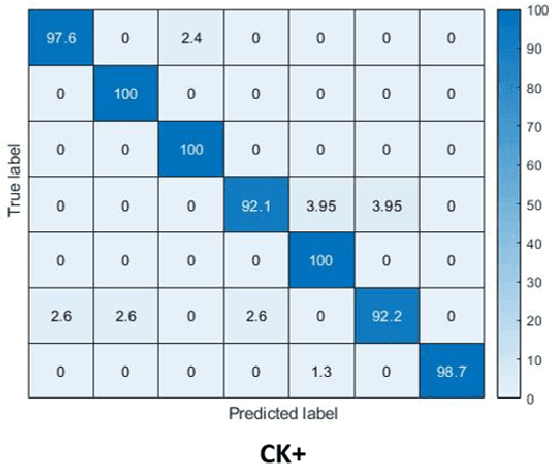

This paper targets to explore the inter-subject variations eliminated facial expression representation in the compressed video domain. Most of the previous methods process the RGB images of a sequence, while the off-the-shelf and valuable expression-related muscle movement already embedded in the compression format. In the up to two orders of magnitude compressed domain, we can explicitly infer the expression from the residual frames and possible to extract identity factors from the I frame with a pre-trained face recognition network. By enforcing the marginal independent of them, the expression feature is expected to be purer for the expression and be robust to identity shifts. We do not need the identity label or multiple expression samples from the same person for identity elimination. Moreover, when the apex frame is annotated in the dataset, the complementary constraint can be further added to regularize the feature-level game. In testing, only the compressed residual frames are required to achieve expression prediction. Our solution can achieve comparable or better performance than the recent decoded image based methods on the typical FER benchmarks with about 3$\times$ faster inference with compressed data.
Energy-constrained Self-training for Unsupervised Domain Adaptation
Jan 01, 2021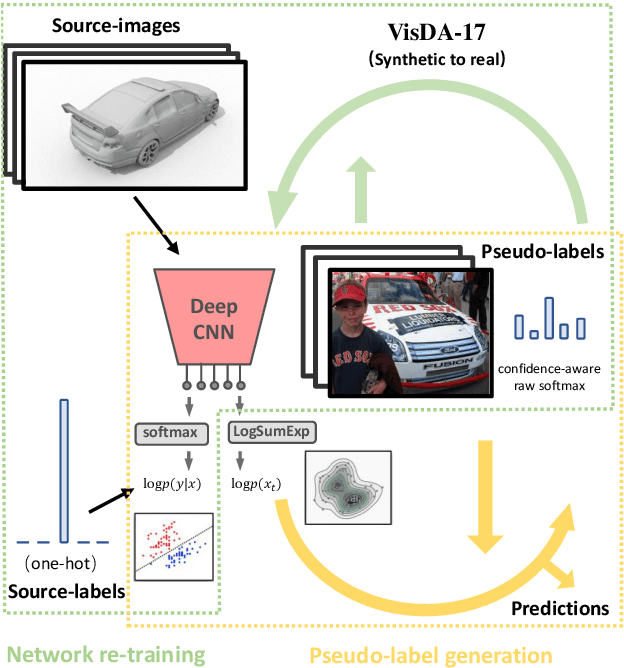

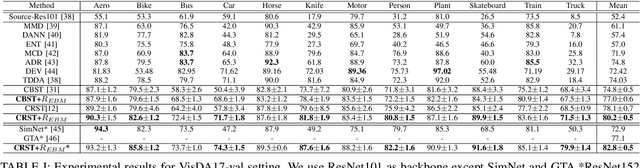
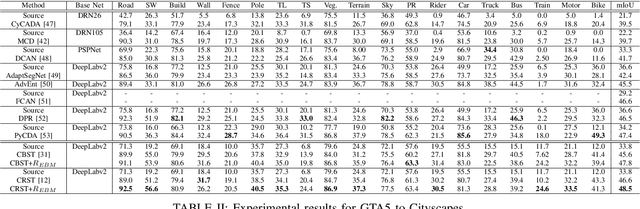
Unsupervised domain adaptation (UDA) aims to transfer the knowledge on a labeled source domain distribution to perform well on an unlabeled target domain. Recently, the deep self-training involves an iterative process of predicting on the target domain and then taking the confident predictions as hard pseudo-labels for retraining. However, the pseudo-labels are usually unreliable, and easily leading to deviated solutions with propagated errors. In this paper, we resort to the energy-based model and constrain the training of the unlabeled target sample with the energy function minimization objective. It can be applied as a simple additional regularization. In this framework, it is possible to gain the benefits of the energy-based model, while retaining strong discriminative performance following a plug-and-play fashion. We deliver extensive experiments on the most popular and large scale UDA benchmarks of image classification as well as semantic segmentation to demonstrate its generality and effectiveness.
Importance-Aware Semantic Segmentation in Self-Driving with Discrete Wasserstein Training
Oct 21, 2020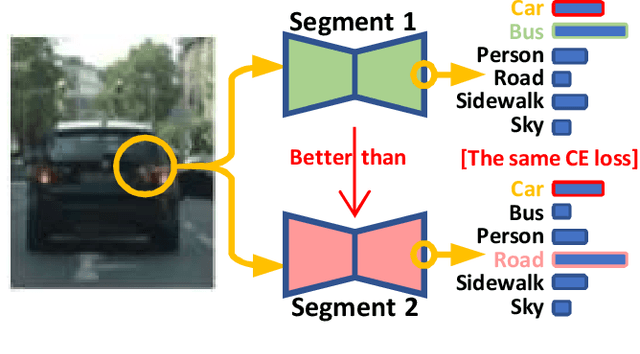
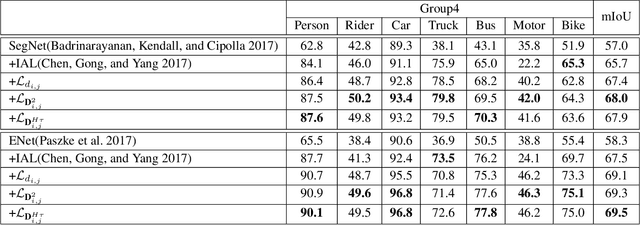
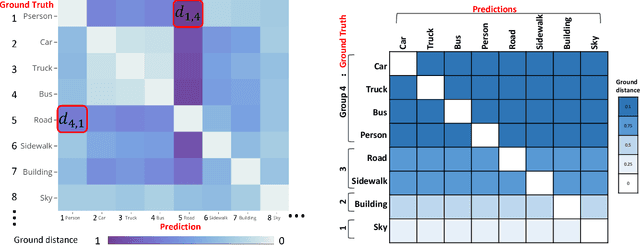
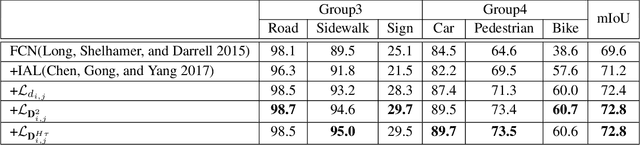
Semantic segmentation (SS) is an important perception manner for self-driving cars and robotics, which classifies each pixel into a pre-determined class. The widely-used cross entropy (CE) loss-based deep networks has achieved significant progress w.r.t. the mean Intersection-over Union (mIoU). However, the cross entropy loss can not take the different importance of each class in an self-driving system into account. For example, pedestrians in the image should be much more important than the surrounding buildings when make a decisions in the driving, so their segmentation results are expected to be as accurate as possible. In this paper, we propose to incorporate the importance-aware inter-class correlation in a Wasserstein training framework by configuring its ground distance matrix. The ground distance matrix can be pre-defined following a priori in a specific task, and the previous importance-ignored methods can be the particular cases. From an optimization perspective, we also extend our ground metric to a linear, convex or concave increasing function $w.r.t.$ pre-defined ground distance. We evaluate our method on CamVid and Cityscapes datasets with different backbones (SegNet, ENet, FCN and Deeplab) in a plug and play fashion. In our extenssive experiments, Wasserstein loss demonstrates superior segmentation performance on the predefined critical classes for safe-driving.