 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVicinal Feature Statistics Augmentation for Federated 3D Medical Volume Segmentation
Oct 23, 2023Federated learning (FL) enables multiple client medical institutes collaboratively train a deep learning (DL) model with privacy protection. However, the performance of FL can be constrained by the limited availability of labeled data in small institutes and the heterogeneous (i.e., non-i.i.d.) data distribution across institutes. Though data augmentation has been a proven technique to boost the generalization capabilities of conventional centralized DL as a "free lunch", its application in FL is largely underexplored. Notably, constrained by costly labeling, 3D medical segmentation generally relies on data augmentation. In this work, we aim to develop a vicinal feature-level data augmentation (VFDA) scheme to efficiently alleviate the local feature shift and facilitate collaborative training for privacy-aware FL segmentation. We take both the inner- and inter-institute divergence into consideration, without the need for cross-institute transfer of raw data or their mixup. Specifically, we exploit the batch-wise feature statistics (e.g., mean and standard deviation) in each institute to abstractly represent the discrepancy of data, and model each feature statistic probabilistically via a Gaussian prototype, with the mean corresponding to the original statistic and the variance quantifying the augmentation scope. From the vicinal risk minimization perspective, novel feature statistics can be drawn from the Gaussian distribution to fulfill augmentation. The variance is explicitly derived by the data bias in each individual institute and the underlying feature statistics characterized by all participating institutes. The added-on VFDA consistently yielded marked improvements over six advanced FL methods on both 3D brain tumor and cardiac segmentation.
* 28th biennial international conference on Information Processing in Medical Imaging (IPMI 2023): Oral Paper
Multimodality in Meta-Learning: A Comprehensive Survey
Sep 28, 2021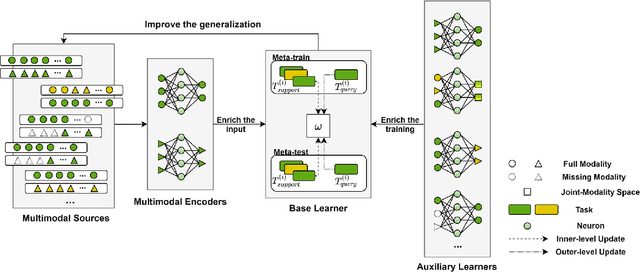

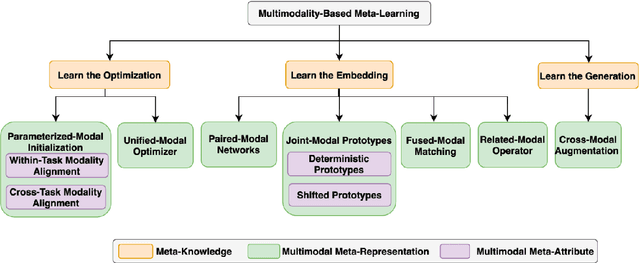
Meta-learning has gained wide popularity as a training framework that is more data-efficient than traditional machine learning methods. However, its generalization ability in complex task distributions, such as multimodal tasks, has not been thoroughly studied. Recently, some studies on multimodality-based meta-learning have emerged. This survey provides a comprehensive overview of the multimodality-based meta-learning landscape in terms of the methodologies and applications. We first formalize the definition of meta-learning and multimodality, along with the research challenges in this growing field, such as how to enrich the input in few-shot or zero-shot scenarios and how to generalize the models to new tasks. We then propose a new taxonomy to systematically discuss typical meta-learning algorithms combined with multimodal tasks. We investigate the contributions of related papers and summarize them by our taxonomy. Finally, we propose potential research directions for this promising field.