 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated interpretation of congenital heart disease from multi-view echocardiograms
Nov 30, 2023



Congenital heart disease (CHD) is the most common birth defect and the leading cause of neonate death in China. Clinical diagnosis can be based on the selected 2D key-frames from five views. Limited by the availability of multi-view data, most methods have to rely on the insufficient single view analysis. This study proposes to automatically analyze the multi-view echocardiograms with a practical end-to-end framework. We collect the five-view echocardiograms video records of 1308 subjects (including normal controls, ventricular septal defect (VSD) patients and atrial septal defect (ASD) patients) with both disease labels and standard-view key-frame labels. Depthwise separable convolution-based multi-channel networks are adopted to largely reduce the network parameters. We also approach the imbalanced class problem by augmenting the positive training samples. Our 2D key-frame model can diagnose CHD or negative samples with an accuracy of 95.4\%, and in negative, VSD or ASD classification with an accuracy of 92.3\%. To further alleviate the work of key-frame selection in real-world implementation, we propose an adaptive soft attention scheme to directly explore the raw video data. Four kinds of neural aggregation methods are systematically investigated to fuse the information of an arbitrary number of frames in a video. Moreover, with a view detection module, the system can work without the view records. Our video-based model can diagnose with an accuracy of 93.9\% (binary classification), and 92.1\% (3-class classification) in a collected 2D video testing set, which does not need key-frame selection and view annotation in testing. The detailed ablation study and the interpretability analysis are provided.
* Published in Medical Image Analysis
Vicinal Feature Statistics Augmentation for Federated 3D Medical Volume Segmentation
Oct 23, 2023Federated learning (FL) enables multiple client medical institutes collaboratively train a deep learning (DL) model with privacy protection. However, the performance of FL can be constrained by the limited availability of labeled data in small institutes and the heterogeneous (i.e., non-i.i.d.) data distribution across institutes. Though data augmentation has been a proven technique to boost the generalization capabilities of conventional centralized DL as a "free lunch", its application in FL is largely underexplored. Notably, constrained by costly labeling, 3D medical segmentation generally relies on data augmentation. In this work, we aim to develop a vicinal feature-level data augmentation (VFDA) scheme to efficiently alleviate the local feature shift and facilitate collaborative training for privacy-aware FL segmentation. We take both the inner- and inter-institute divergence into consideration, without the need for cross-institute transfer of raw data or their mixup. Specifically, we exploit the batch-wise feature statistics (e.g., mean and standard deviation) in each institute to abstractly represent the discrepancy of data, and model each feature statistic probabilistically via a Gaussian prototype, with the mean corresponding to the original statistic and the variance quantifying the augmentation scope. From the vicinal risk minimization perspective, novel feature statistics can be drawn from the Gaussian distribution to fulfill augmentation. The variance is explicitly derived by the data bias in each individual institute and the underlying feature statistics characterized by all participating institutes. The added-on VFDA consistently yielded marked improvements over six advanced FL methods on both 3D brain tumor and cardiac segmentation.
* 28th biennial international conference on Information Processing in Medical Imaging (IPMI 2023): Oral Paper
Deep 3D-CNN for Depression Diagnosis with Facial Video Recording of Self-Rating Depression Scale Questionnaire
Jul 22, 2021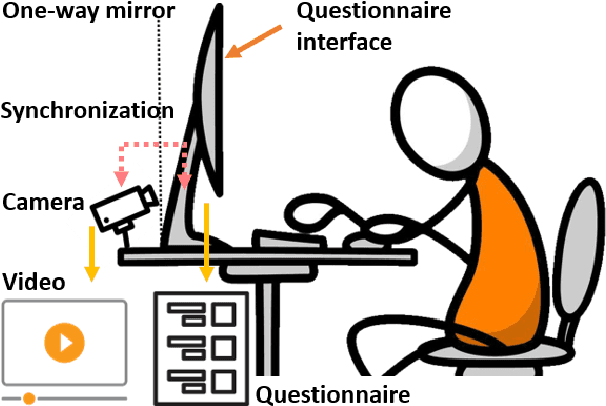
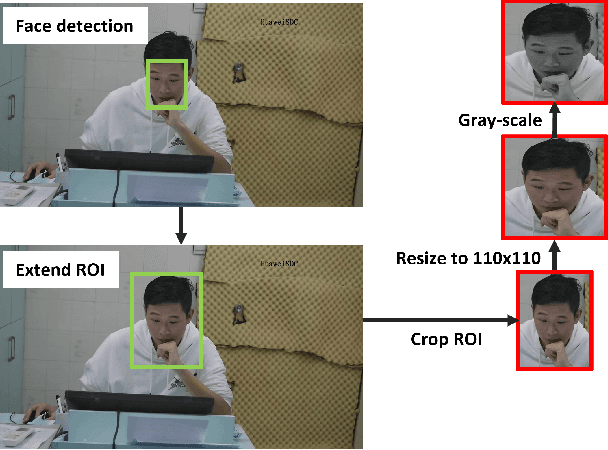
The Self-Rating Depression Scale (SDS) questionnaire is commonly utilized for effective depression preliminary screening. The uncontrolled self-administered measure, on the other hand, maybe readily influenced by insouciant or dishonest responses, yielding different findings from the clinician-administered diagnostic. Facial expression (FE) and behaviors are important in clinician-administered assessments, but they are underappreciated in self-administered evaluations. We use a new dataset of 200 participants to demonstrate the validity of self-rating questionnaires and their accompanying question-by-question video recordings in this study. We offer an end-to-end system to handle the face video recording that is conditioned on the questionnaire answers and the responding time to automatically interpret sadness from the SDS assessment and the associated video. We modified a 3D-CNN for temporal feature extraction and compared various state-of-the-art temporal modeling techniques. The superior performance of our system shows the validity of combining facial video recording with the SDS score for more accurate self-diagnose.
Interpreting Depression From Question-wise Long-term Video Recording of SDS Evaluation
Jun 25, 2021



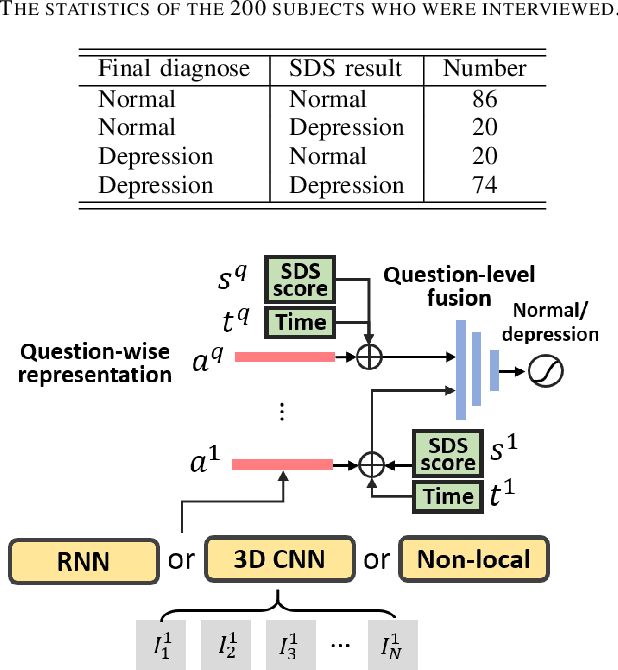
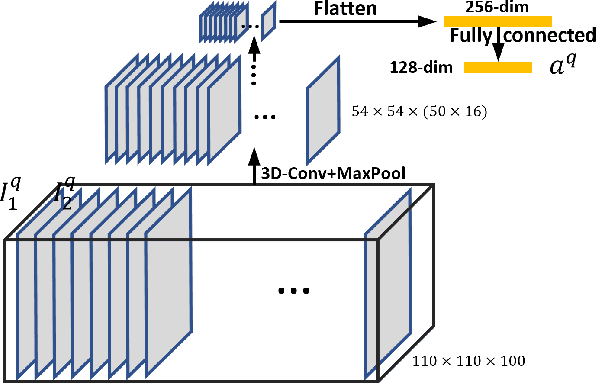
Self-Rating Depression Scale (SDS) questionnaire has frequently been used for efficient depression preliminary screening. However, the uncontrollable self-administered measure can be easily affected by insouciantly or deceptively answering, and producing the different results with the clinician-administered Hamilton Depression Rating Scale (HDRS) and the final diagnosis. Clinically, facial expression (FE) and actions play a vital role in clinician-administered evaluation, while FE and action are underexplored for self-administered evaluations. In this work, we collect a novel dataset of 200 subjects to evidence the validity of self-rating questionnaires with their corresponding question-wise video recording. To automatically interpret depression from the SDS evaluation and the paired video, we propose an end-to-end hierarchical framework for the long-term variable-length video, which is also conditioned on the questionnaire results and the answering time. Specifically, we resort to a hierarchical model which utilizes a 3D CNN for local temporal pattern exploration and a redundancy-aware self-attention (RAS) scheme for question-wise global feature aggregation. Targeting for the redundant long-term FE video processing, our RAS is able to effectively exploit the correlations of each video clip within a question set to emphasize the discriminative information and eliminate the redundancy based on feature pair-wise affinity. Then, the question-wise video feature is concatenated with the questionnaire scores for final depression detection. Our thorough evaluations also show the validity of fusing SDS evaluation and its video recording, and the superiority of our framework to the conventional state-of-the-art temporal modeling methods.
Embedding Semantic Hierarchy in Discrete Optimal Transport for Risk Minimization
Apr 30, 2021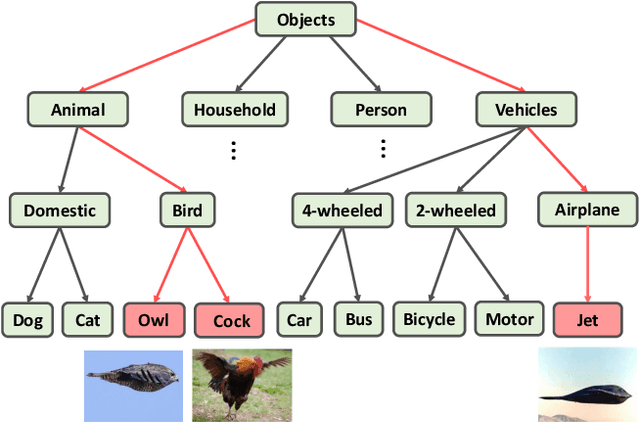
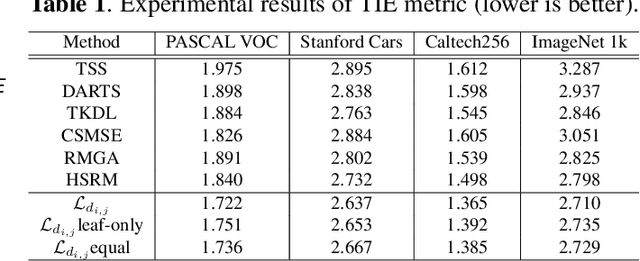
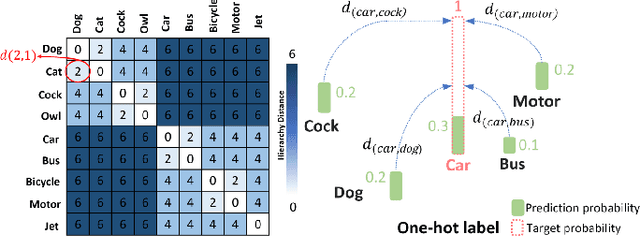
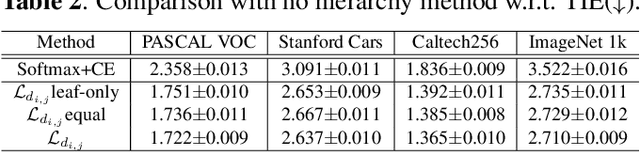
The widely-used cross-entropy (CE) loss-based deep networks achieved significant progress w.r.t. the classification accuracy. However, the CE loss can essentially ignore the risk of misclassification which is usually measured by the distance between the prediction and label in a semantic hierarchical tree. In this paper, we propose to incorporate the risk-aware inter-class correlation in a discrete optimal transport (DOT) training framework by configuring its ground distance matrix. The ground distance matrix can be pre-defined following a priori of hierarchical semantic risk. Specifically, we define the tree induced error (TIE) on a hierarchical semantic tree and extend it to its increasing function from the optimization perspective. The semantic similarity in each level of a tree is integrated with the information gain. We achieve promising results on several large scale image classification tasks with a semantic tree structure in a plug and play manner.