 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding Semantic Hierarchy in Discrete Optimal Transport for Risk Minimization
Paper and Code
Apr 30, 2021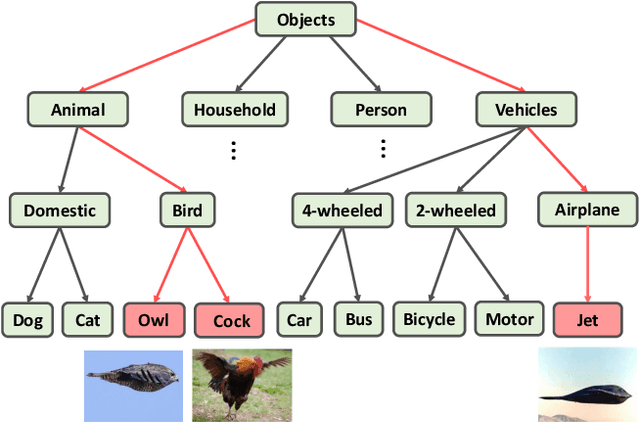
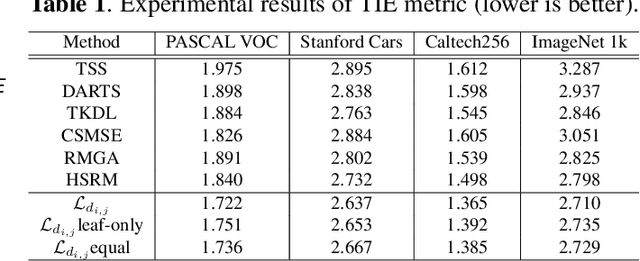
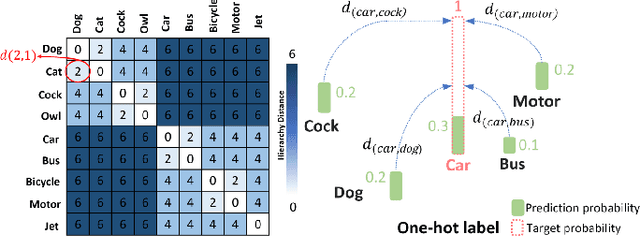
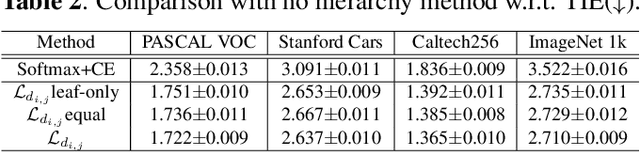
The widely-used cross-entropy (CE) loss-based deep networks achieved significant progress w.r.t. the classification accuracy. However, the CE loss can essentially ignore the risk of misclassification which is usually measured by the distance between the prediction and label in a semantic hierarchical tree. In this paper, we propose to incorporate the risk-aware inter-class correlation in a discrete optimal transport (DOT) training framework by configuring its ground distance matrix. The ground distance matrix can be pre-defined following a priori of hierarchical semantic risk. Specifically, we define the tree induced error (TIE) on a hierarchical semantic tree and extend it to its increasing function from the optimization perspective. The semantic similarity in each level of a tree is integrated with the information gain. We achieve promising results on several large scale image classification tasks with a semantic tree structure in a plug and play manner.