 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Text to Medical Image Diffusion Model with Subgroup Distribution Aligned Tuning
Jun 21, 2024The text to medical image (T2MedI) with latent diffusion model has great potential to alleviate the scarcity of medical imaging data and explore the underlying appearance distribution of lesions in a specific patient status description. However, as the text to nature image models, we show that the T2MedI model can also bias to some subgroups to overlook the minority ones in the training set. In this work, we first build a T2MedI model based on the pre-trained Imagen model, which has the fixed contrastive language-image pre-training (CLIP) text encoder, while its decoder has been fine-tuned on medical images from the Radiology Objects in COntext (ROCO) dataset. Its gender bias is analyzed qualitatively and quantitatively. Toward this issue, we propose to fine-tune the T2MedI toward the target application dataset to align their sensitive subgroups distribution probability. Specifically, the alignment loss for fine-tuning is guided by an off-the-shelf sensitivity-subgroup classifier to match the classification probability between the generated images and the expected target dataset. In addition, the image quality is maintained by a CLIP-consistency regularization term following a knowledge distillation scheme. For evaluation, we set the target dataset to be enhanced as the BraST18 dataset, and trained a brain magnetic resonance (MR) slice-based gender classifier from it. With our method, the generated MR image can markedly reduce the inconsistency with the gender proportion in the BraTS18 dataset.
Embedding Semantic Hierarchy in Discrete Optimal Transport for Risk Minimization
Apr 30, 2021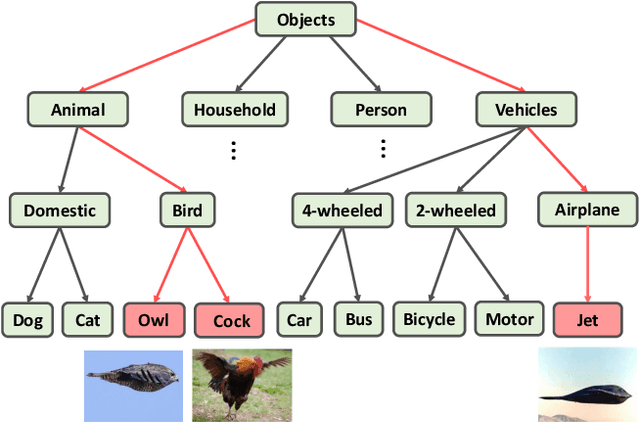
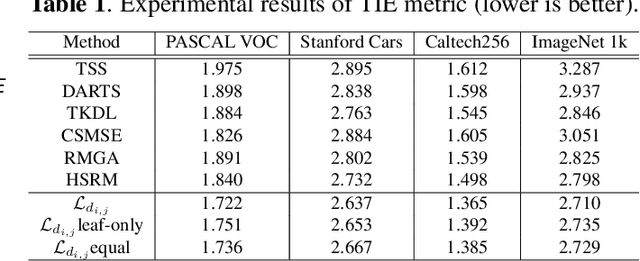
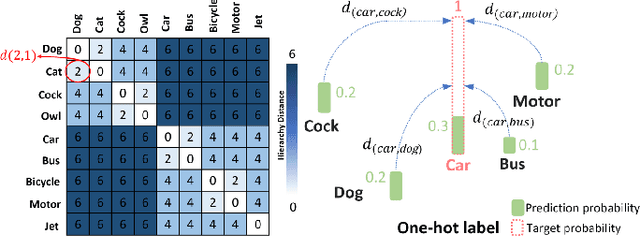
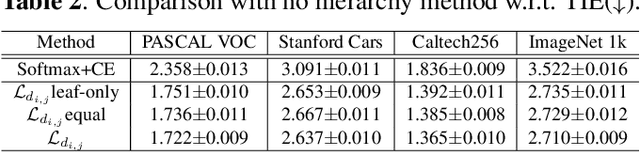
The widely-used cross-entropy (CE) loss-based deep networks achieved significant progress w.r.t. the classification accuracy. However, the CE loss can essentially ignore the risk of misclassification which is usually measured by the distance between the prediction and label in a semantic hierarchical tree. In this paper, we propose to incorporate the risk-aware inter-class correlation in a discrete optimal transport (DOT) training framework by configuring its ground distance matrix. The ground distance matrix can be pre-defined following a priori of hierarchical semantic risk. Specifically, we define the tree induced error (TIE) on a hierarchical semantic tree and extend it to its increasing function from the optimization perspective. The semantic similarity in each level of a tree is integrated with the information gain. We achieve promising results on several large scale image classification tasks with a semantic tree structure in a plug and play manner.
Machine vision detection to daily facial fatigue with a nonlocal 3D attention network
Apr 21, 2021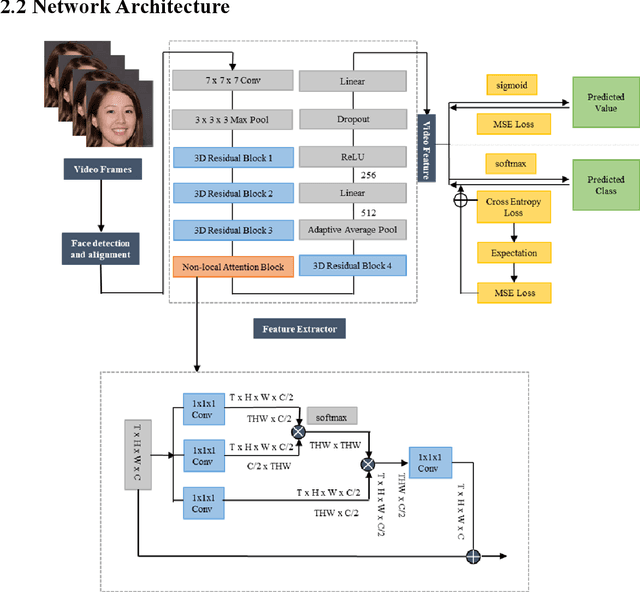
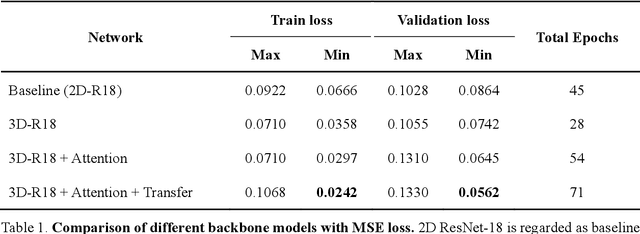
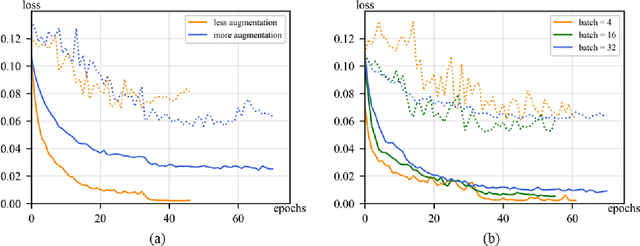
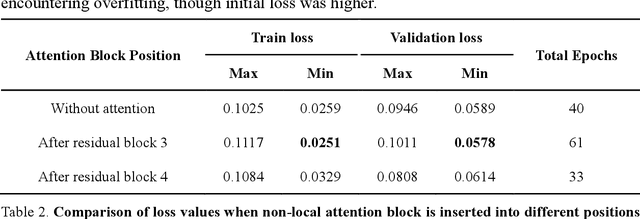
Fatigue detection is valued for people to keep mental health and prevent safety accidents. However, detecting facial fatigue, especially mild fatigue in the real world via machine vision is still a challenging issue due to lack of non-lab dataset and well-defined algorithms. In order to improve the detection capability on facial fatigue that can be used widely in daily life, this paper provided an audiovisual dataset named DLFD (daily-life fatigue dataset) which reflected people's facial fatigue state in the wild. A framework using 3D-ResNet along with non-local attention mechanism was training for extraction of local and long-range features in spatial and temporal dimensions. Then, a compacted loss function combining mean squared error and cross-entropy was designed to predict both continuous and categorical fatigue degrees. Our proposed framework has reached an average accuracy of 90.8% on validation set and 72.5% on test set for binary classification, standing a good position compared to other state-of-the-art methods. The analysis of feature map visualization revealed that our framework captured facial dynamics and attempted to build a connection with fatigue state. Our experimental results in multiple metrics proved that our framework captured some typical, micro and dynamic facial features along spatiotemporal dimensions, contributing to the mild fatigue detection in the wild.