 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Language Models Understand Context?
Feb 01, 2024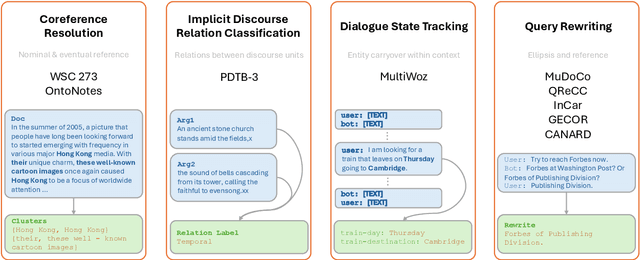


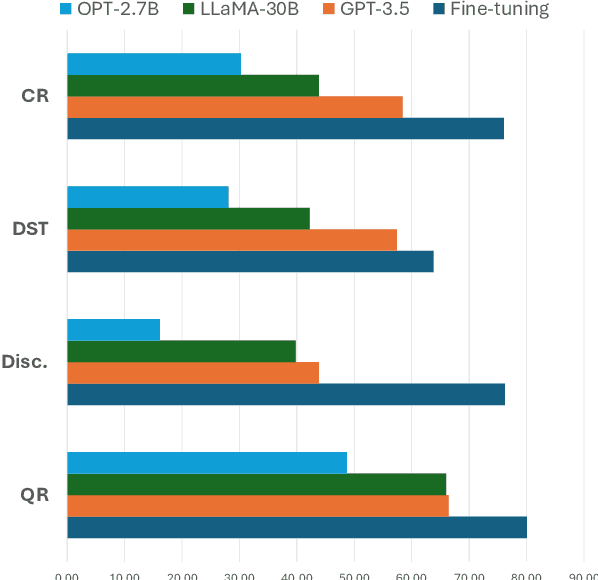
Understanding context is key to understanding human language, an ability which Large Language Models (LLMs) have been increasingly seen to demonstrate to an impressive extent. However, though the evaluation of LLMs encompasses various domains within the realm of Natural Language Processing, limited attention has been paid to probing their linguistic capability of understanding contextual features. This paper introduces a context understanding benchmark by adapting existing datasets to suit the evaluation of generative models. This benchmark comprises of four distinct tasks and nine datasets, all featuring prompts designed to assess the models' ability to understand context. First, we evaluate the performance of LLMs under the in-context learning pretraining scenario. Experimental results indicate that pre-trained dense models struggle with understanding more nuanced contextual features when compared to state-of-the-art fine-tuned models. Second, as LLM compression holds growing significance in both research and real-world applications, we assess the context understanding of quantized models under in-context-learning settings. We find that 3-bit post-training quantization leads to varying degrees of performance reduction on our benchmark. We conduct an extensive analysis of these scenarios to substantiate our experimental results.
MARRS: Multimodal Reference Resolution System
Nov 03, 2023



Successfully handling context is essential for any dialog understanding task. This context maybe be conversational (relying on previous user queries or system responses), visual (relying on what the user sees, for example, on their screen), or background (based on signals such as a ringing alarm or playing music). In this work, we present an overview of MARRS, or Multimodal Reference Resolution System, an on-device framework within a Natural Language Understanding system, responsible for handling conversational, visual and background context. In particular, we present different machine learning models to enable handing contextual queries; specifically, one to enable reference resolution, and one to handle context via query rewriting. We also describe how these models complement each other to form a unified, coherent, lightweight system that can understand context while preserving user privacy.
Ontology Revision based on Pre-trained Language Models
Oct 27, 2023Ontology revision aims to seamlessly incorporate new information into an existing ontology and plays a crucial role in tasks such as ontology evolution, ontology maintenance, and ontology alignment. Similar to repair single ontologies, resolving logical incoherence in the task of ontology revision is also important and meaningful since incoherence is a main potential factor to cause inconsistency and reasoning with an inconsistent ontology will obtain meaningless answers. To deal with this problem, various ontology revision methods have been proposed to define revision operators and design ranking strategies for axioms in an ontology. However, they rarely consider axiom semantics which provides important information to differentiate axioms. On the other hand, pre-trained models can be utilized to encode axiom semantics, and have been widely applied in many natural language processing tasks and ontology-related ones in recent years. Therefore, in this paper, we define four scoring functions to rank axioms based on a pre-trained model by considering various information from a rebuttal ontology and its corresponding reliable ontology. Based on such a scoring function, we propose an ontology revision algorithm to deal with unsatisfiable concepts at once. If it is hard to resolve all unsatisfiable concepts in a rebuttal ontology together, an adapted revision algorithm is designed to deal with them group by group. We conduct experiments over 19 ontology pairs and compare our algorithms and scoring functions with existing ones. According to the experiments, it shows that our algorithms could achieve promising performance. The adapted revision algorithm could improve the efficiency largely, and at most 96% time could be saved for some ontology pairs. Some of our scoring functions help a revision algorithm obtain better results in many cases, especially for the challenging pairs.
5IDER: Unified Query Rewriting for Steering, Intent Carryover, Disfluencies, Entity Carryover and Repair
Jun 02, 2023
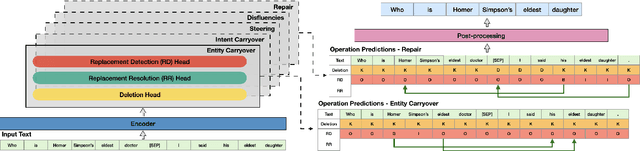
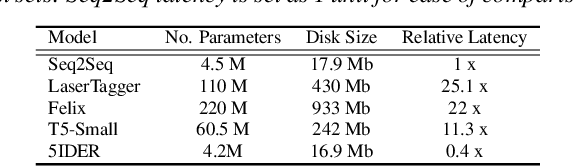
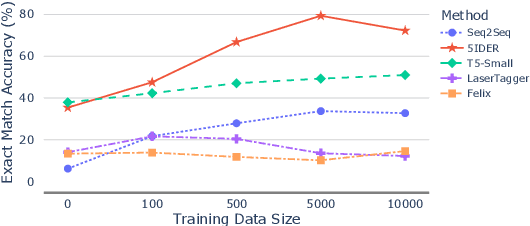
Providing voice assistants the ability to navigate multi-turn conversations is a challenging problem. Handling multi-turn interactions requires the system to understand various conversational use-cases, such as steering, intent carryover, disfluencies, entity carryover, and repair. The complexity of this problem is compounded by the fact that these use-cases mix with each other, often appearing simultaneously in natural language. This work proposes a non-autoregressive query rewriting architecture that can handle not only the five aforementioned tasks, but also complex compositions of these use-cases. We show that our proposed model has competitive single task performance compared to the baseline approach, and even outperforms a fine-tuned T5 model in use-case compositions, despite being 15 times smaller in parameters and 25 times faster in latency.
An Embedding-based Approach to Inconsistency-tolerant Reasoning with Inconsistent Ontologies
Apr 04, 2023Inconsistency handling is an important issue in knowledge management. Especially in ontology engineering, logical inconsistencies may occur during ontology construction. A natural way to reason with an inconsistent ontology is to utilize the maximal consistent subsets of the ontology. However, previous studies on selecting maximum consistent subsets have rarely considered the semantics of the axioms, which may result in irrational inference. In this paper, we propose a novel approach to reasoning with inconsistent ontologies in description logics based on the embeddings of axioms. We first give a method for turning axioms into distributed semantic vectors to compute the semantic connections between the axioms. We then define an embedding-based method for selecting the maximum consistent subsets and use it to define an inconsistency-tolerant inference relation. We show the rationality of our inference relation by considering some logical properties. Finally, we conduct experiments on several ontologies to evaluate the reasoning power of our inference relation. The experimental results show that our embedding-based method can outperform existing inconsistency-tolerant reasoning methods based on maximal consistent subsets.
Towards Modern Card Games with Large-Scale Action Spaces Through Action Representation
Jun 25, 2022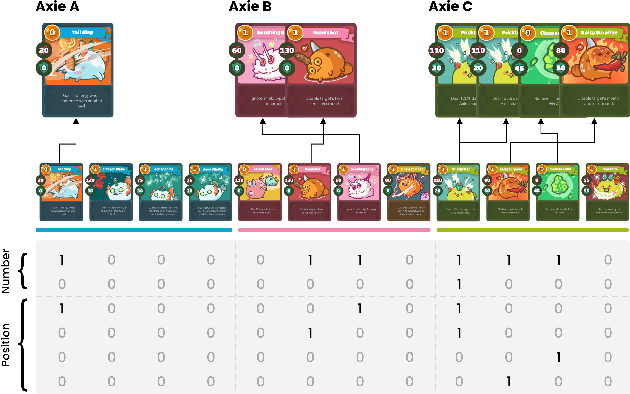

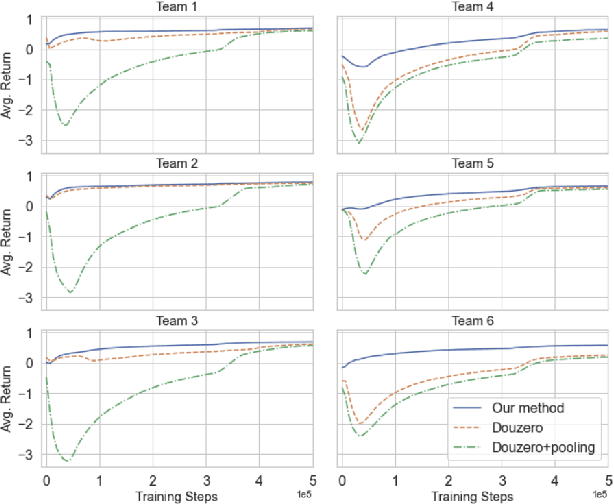
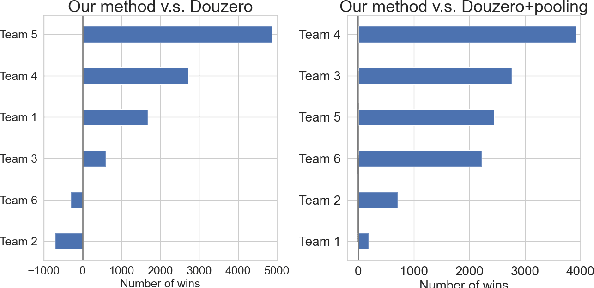
Axie infinity is a complicated card game with a huge-scale action space. This makes it difficult to solve this challenge using generic Reinforcement Learning (RL) algorithms. We propose a hybrid RL framework to learn action representations and game strategies. To avoid evaluating every action in the large feasible action set, our method evaluates actions in a fixed-size set which is determined using action representations. We compare the performance of our method with the other two baseline methods in terms of their sample efficiency and the winning rates of the trained models. We empirically show that our method achieves an overall best winning rate and the best sample efficiency among the three methods.
Recursively Conditional Gaussian for Ordinal Unsupervised Domain Adaptation
Aug 17, 2021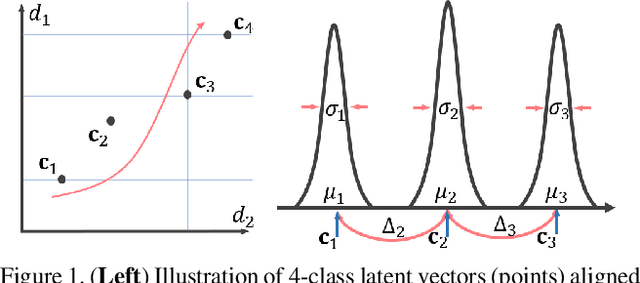
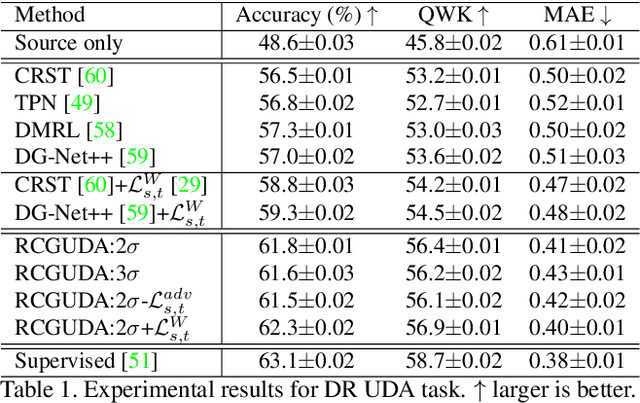
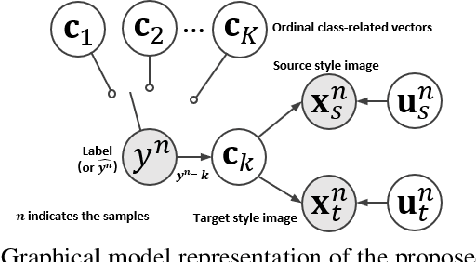
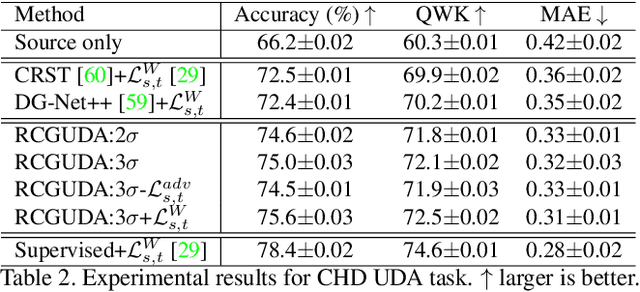
The unsupervised domain adaptation (UDA) has been widely adopted to alleviate the data scalability issue, while the existing works usually focus on classifying independently discrete labels. However, in many tasks (e.g., medical diagnosis), the labels are discrete and successively distributed. The UDA for ordinal classification requires inducing non-trivial ordinal distribution prior to the latent space. Target for this, the partially ordered set (poset) is defined for constraining the latent vector. Instead of the typically i.i.d. Gaussian latent prior, in this work, a recursively conditional Gaussian (RCG) set is adapted for ordered constraint modeling, which admits a tractable joint distribution prior. Furthermore, we are able to control the density of content vector that violates the poset constraints by a simple "three-sigma rule". We explicitly disentangle the cross-domain images into a shared ordinal prior induced ordinal content space and two separate source/target ordinal-unrelated spaces, and the self-training is worked on the shared space exclusively for ordinal-aware domain alignment. Extensive experiments on UDA medical diagnoses and facial age estimation demonstrate its effectiveness.
Adversarial Unsupervised Domain Adaptation with Conditional and Label Shift: Infer, Align and Iterate
Aug 02, 2021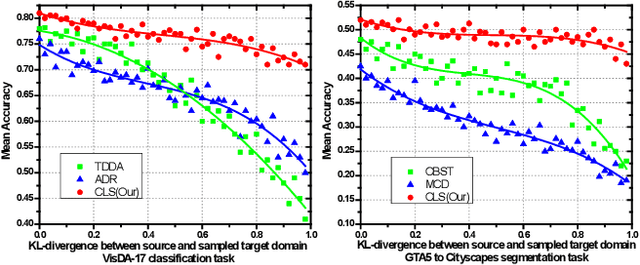
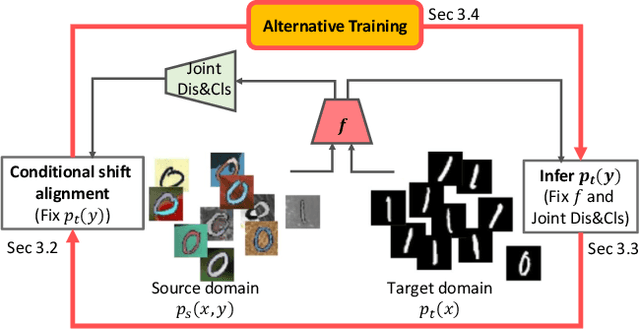
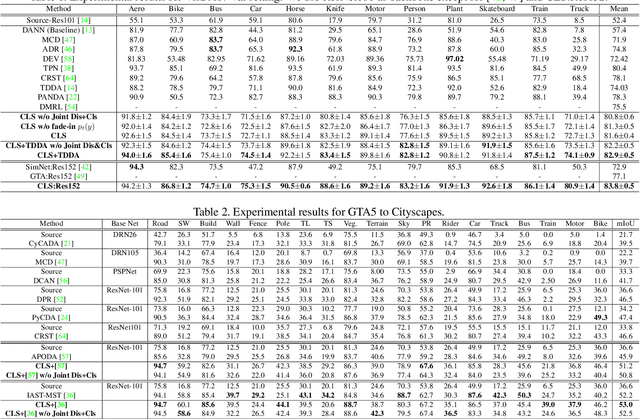
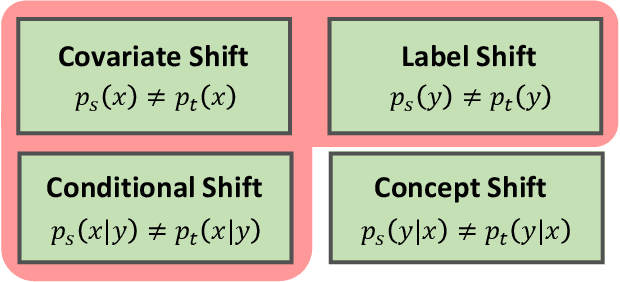
In this work, we propose an adversarial unsupervised domain adaptation (UDA) approach with the inherent conditional and label shifts, in which we aim to align the distributions w.r.t. both $p(x|y)$ and $p(y)$. Since the label is inaccessible in the target domain, the conventional adversarial UDA assumes $p(y)$ is invariant across domains, and relies on aligning $p(x)$ as an alternative to the $p(x|y)$ alignment. To address this, we provide a thorough theoretical and empirical analysis of the conventional adversarial UDA methods under both conditional and label shifts, and propose a novel and practical alternative optimization scheme for adversarial UDA. Specifically, we infer the marginal $p(y)$ and align $p(x|y)$ iteratively in the training, and precisely align the posterior $p(y|x)$ in testing. Our experimental results demonstrate its effectiveness on both classification and segmentation UDA, and partial UDA.
Embedding Semantic Hierarchy in Discrete Optimal Transport for Risk Minimization
Apr 30, 2021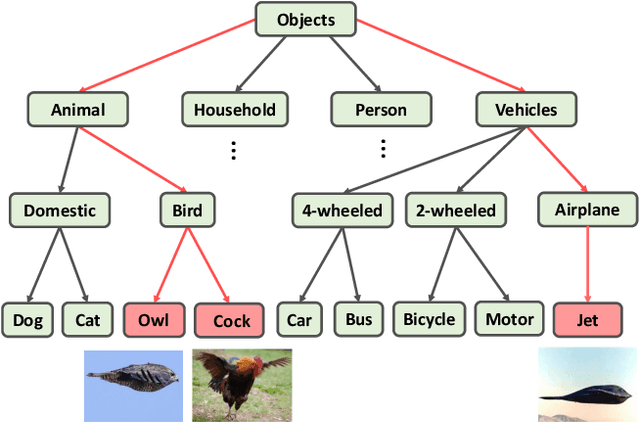
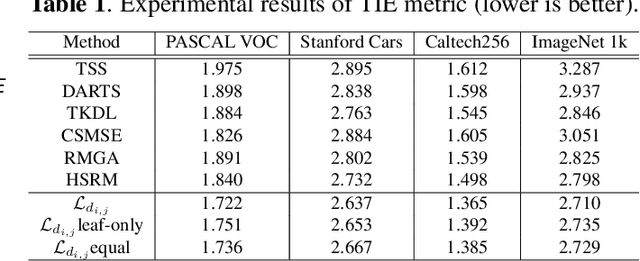
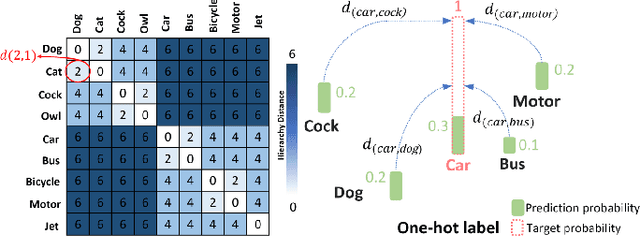
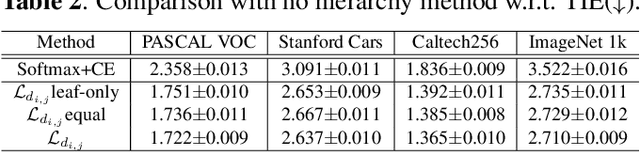
The widely-used cross-entropy (CE) loss-based deep networks achieved significant progress w.r.t. the classification accuracy. However, the CE loss can essentially ignore the risk of misclassification which is usually measured by the distance between the prediction and label in a semantic hierarchical tree. In this paper, we propose to incorporate the risk-aware inter-class correlation in a discrete optimal transport (DOT) training framework by configuring its ground distance matrix. The ground distance matrix can be pre-defined following a priori of hierarchical semantic risk. Specifically, we define the tree induced error (TIE) on a hierarchical semantic tree and extend it to its increasing function from the optimization perspective. The semantic similarity in each level of a tree is integrated with the information gain. We achieve promising results on several large scale image classification tasks with a semantic tree structure in a plug and play manner.
MBVI: Model-Based Value Initialization for Reinforcement Learning
Nov 04, 2020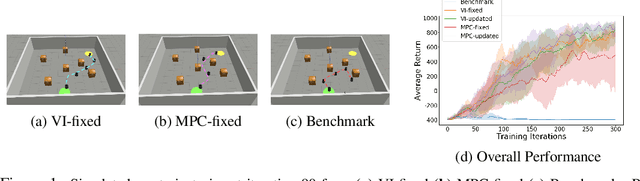
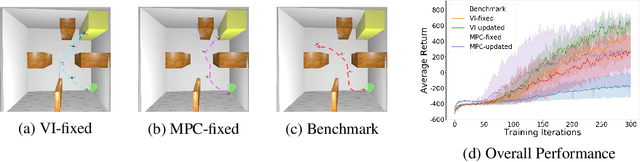
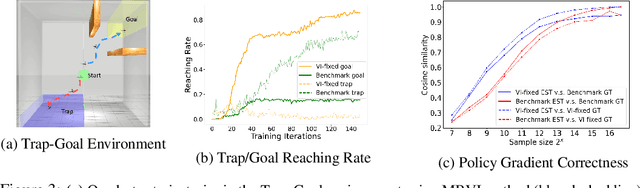
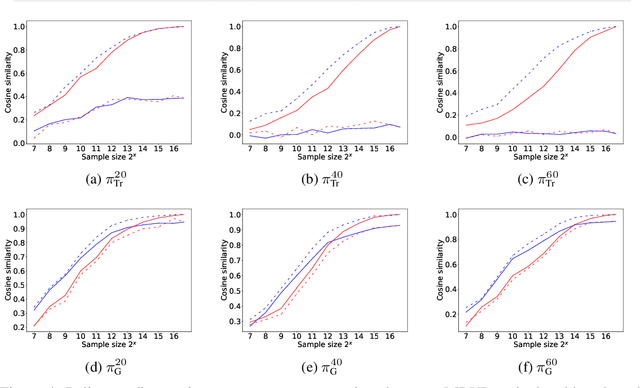
Model-free reinforcement learning (RL) is capable of learning control policies for high-dimensional, complex robotic tasks, but tends to be data inefficient. Model-based RL and optimal control have been proven to be much more data-efficient if an accurate model of the system and environment is known, but can be difficult to scale to expressive models for high-dimensional problems. In this paper, we propose a novel approach to alleviate data inefficiency of model-free RL by warm-starting the learning process using model-based solutions. We do so by initializing a high-dimensional value function via supervision from a low-dimensional value function obtained by applying model-based techniques on a low-dimensional problem featuring an approximate system model. Therefore, our approach exploits the model priors from a simplified problem space implicitly and avoids the direct use of high-dimensional, expressive models. We demonstrate our approach on two representative robotic learning tasks and observe significant improvements in performance and efficiency, and analyze our method empirically with a third task.