Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Modern Card Games with Large-Scale Action Spaces Through Action Representation
Jun 25, 2022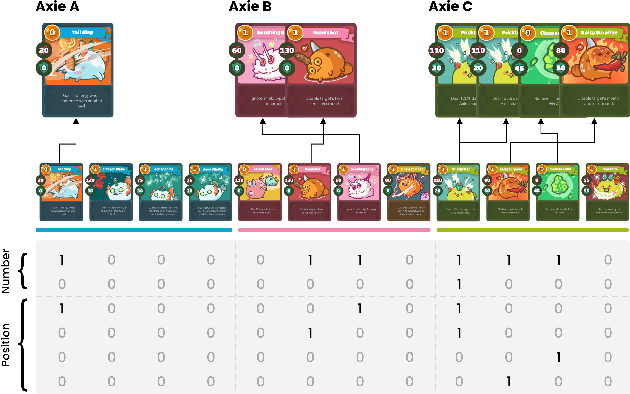

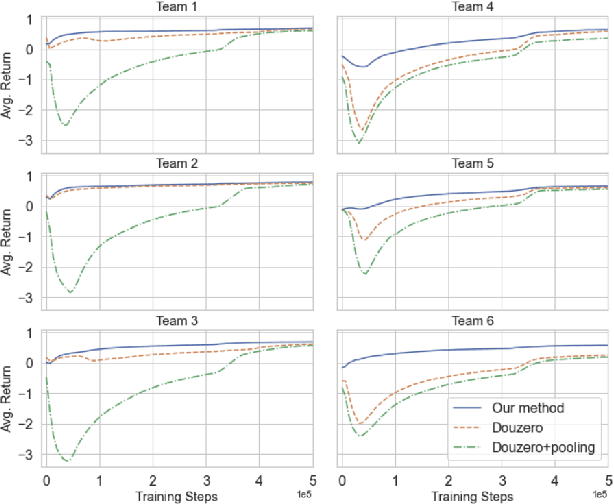
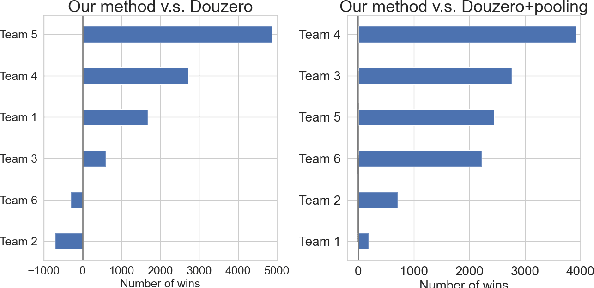
Axie infinity is a complicated card game with a huge-scale action space. This makes it difficult to solve this challenge using generic Reinforcement Learning (RL) algorithms. We propose a hybrid RL framework to learn action representations and game strategies. To avoid evaluating every action in the large feasible action set, our method evaluates actions in a fixed-size set which is determined using action representations. We compare the performance of our method with the other two baseline methods in terms of their sample efficiency and the winning rates of the trained models. We empirically show that our method achieves an overall best winning rate and the best sample efficiency among the three methods.
* Accpeted as IEEE CoG2022 proceedings paper
Via