 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation for Underwater Feature Extraction and Matching via GAN-synthesized Images
Apr 11, 2025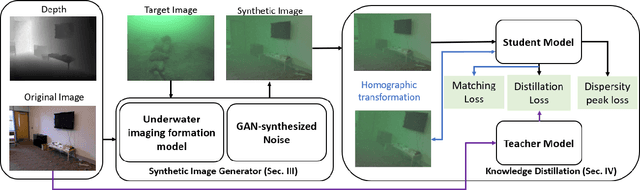
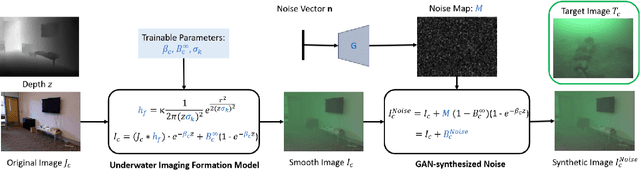
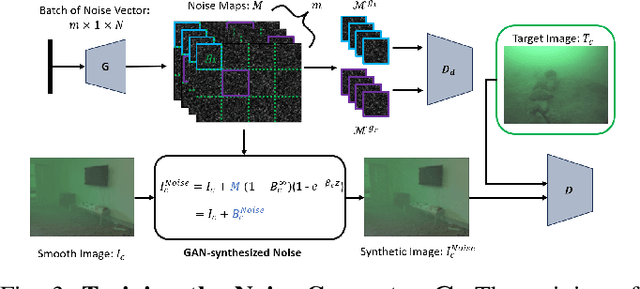

Autonomous Underwater Vehicles (AUVs) play a crucial role in underwater exploration. Vision-based methods offer cost-effective solutions for localization and mapping in the absence of conventional sensors like GPS and LIDAR. However, underwater environments present significant challenges for feature extraction and matching due to image blurring and noise caused by attenuation, scattering, and the interference of \textit{marine snow}. In this paper, we aim to improve the robustness of the feature extraction and matching in the turbid underwater environment using the cross-modal knowledge distillation method that transfers the in-air feature extraction models to underwater settings using synthetic underwater images as the medium. We first propose a novel adaptive GAN-synthesis method to estimate water parameters and underwater noise distribution, to generate environment-specific synthetic underwater images. We then introduce a general knowledge distillation framework compatible with different teacher models. The evaluation of GAN-based synthesis highlights the significance of the new components, i.e. GAN-synthesized noise and forward scattering, in the proposed model. Additionally, the downstream application of feature extraction and matching (VSLAM) on real underwater sequences validates the effectiveness of the transferred model.
Non-Asymptotic Bounds for Closed-Loop Identification of Unstable Nonlinear Stochastic Systems
Dec 05, 2024

We consider the problem of least squares parameter estimation from single-trajectory data for discrete-time, unstable, closed-loop nonlinear stochastic systems, with linearly parameterised uncertainty. Assuming a region of the state space produces informative data, and the system is sub-exponentially unstable, we establish non-asymptotic guarantees on the estimation error at times where the state trajectory evolves in this region. If the whole state space is informative, high probability guarantees on the error hold for all times. Examples are provided where our results are useful for analysis, but existing results are not.
Towards Fast and Safety-Guaranteed Trajectory Planning and Tracking for Time-Varying Systems
Dec 05, 2024When deploying autonomous systems in unknown and changing environments, it is critical that their motion planning and control algorithms are computationally efficient and can be reapplied online in real time, whilst providing theoretical safety guarantees in the presence of disturbances. The satisfaction of these objectives becomes more challenging when considering time-varying dynamics and disturbances, which arise in real-world contexts. We develop methods with the potential to address these issues by applying an offline-computed safety guaranteeing controller on a physical system, to track a virtual system that evolves through a trajectory that is replanned online, accounting for constraints updated online. The first method we propose is designed for general time-varying systems over a finite horizon. Our second method overcomes the finite horizon restriction for periodic systems. We simulate our algorithms on a case study of an autonomous underwater vehicle subject to wave disturbances.
Task-Oriented Koopman-Based Control with Contrastive Encoder
Sep 28, 2023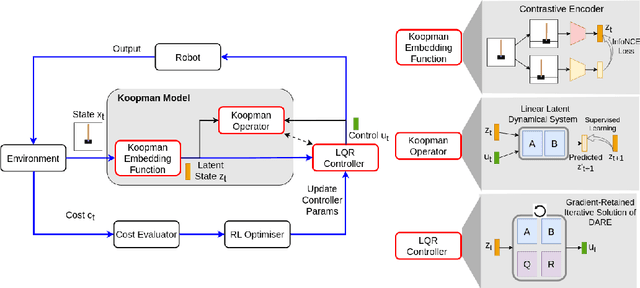
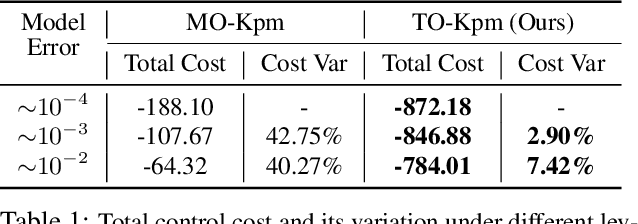
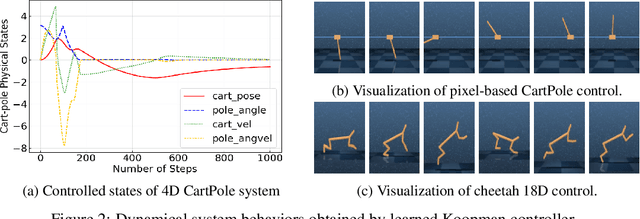
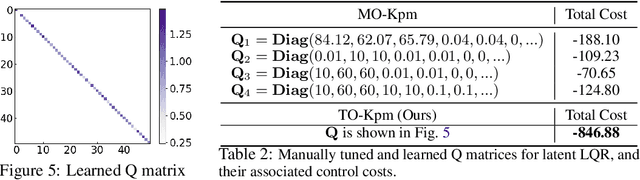
We present task-oriented Koopman-based control that utilizes end-to-end reinforcement learning and contrastive encoder to simultaneously learn the Koopman latent embedding, operator and associated linear controller within an iterative loop. By prioritizing the task cost as main objective for controller learning, we reduce the reliance of controller design on a well-identified model, which extends Koopman control beyond low-dimensional systems to high-dimensional, complex nonlinear systems, including pixel-based scenarios.
Stability Bounds for Learning-Based Adaptive Control of Discrete-Time Multi-Dimensional Stochastic Linear Systems with Input Constraints
Apr 02, 2023
We consider the problem of adaptive stabilization for discrete-time, multi-dimensional linear systems with bounded control input constraints and unbounded stochastic disturbances, where the parameters of the true system are unknown. To address this challenge, we propose a certainty-equivalent control scheme which combines online parameter estimation with saturated linear control. We establish the existence of a high probability stability bound on the closed-loop system, under additional assumptions on the system and noise processes. Finally, numerical examples are presented to illustrate our results.
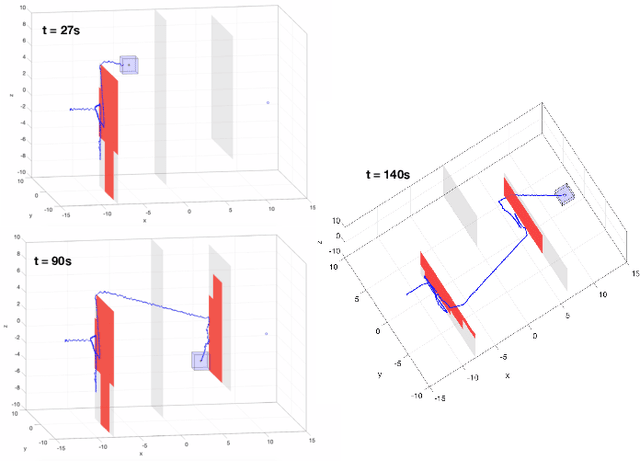
Knowledge Distillation for Feature Extraction in Underwater VSLAM
Mar 31, 2023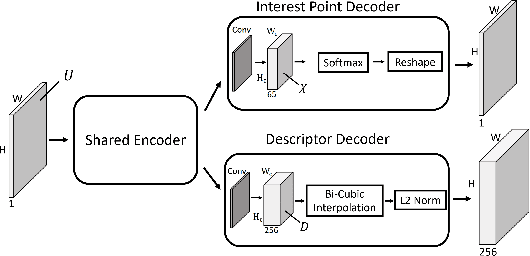
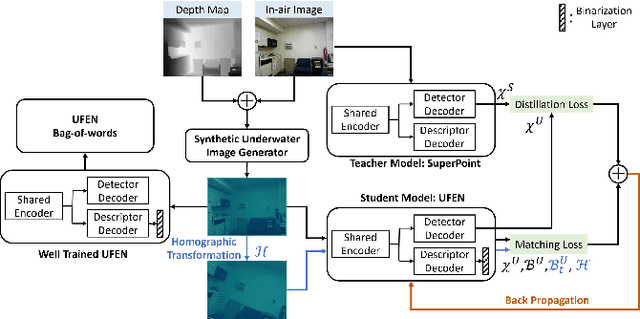
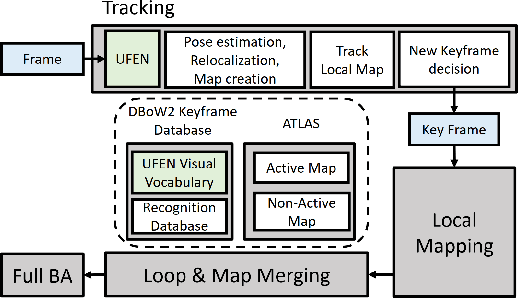
In recent years, learning-based feature detection and matching have outperformed manually-designed methods in in-air cases. However, it is challenging to learn the features in the underwater scenario due to the absence of annotated underwater datasets. This paper proposes a cross-modal knowledge distillation framework for training an underwater feature detection and matching network (UFEN). In particular, we use in-air RGBD data to generate synthetic underwater images based on a physical underwater imaging formation model and employ these as the medium to distil knowledge from a teacher model SuperPoint pretrained on in-air images. We embed UFEN into the ORB-SLAM3 framework to replace the ORB feature by introducing an additional binarization layer. To test the effectiveness of our method, we built a new underwater dataset with groundtruth measurements named EASI (https://github.com/Jinghe-mel/UFEN-SLAM), recorded in an indoor water tank for different turbidity levels. The experimental results on the existing dataset and our new dataset demonstrate the effectiveness of our method.
Learning-Based Adaptive Control for Stochastic Linear Systems with Input Constraints
Sep 17, 2022
We propose a certainty-equivalence scheme for adaptive control of scalar linear systems subject to additive, i.i.d. Gaussian disturbances and bounded control input constraints, without requiring prior knowledge of the bounds of the system parameters, nor the control direction. Assuming that the system is at-worst marginally stable, mean square boundedness of the closed-loop system states is proven. Lastly, numerical examples are presented to illustrate our results.
Data-driven Predictive Tracking Control based on Koopman Operators
Aug 25, 2022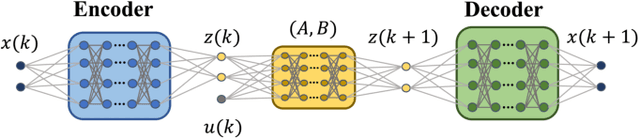
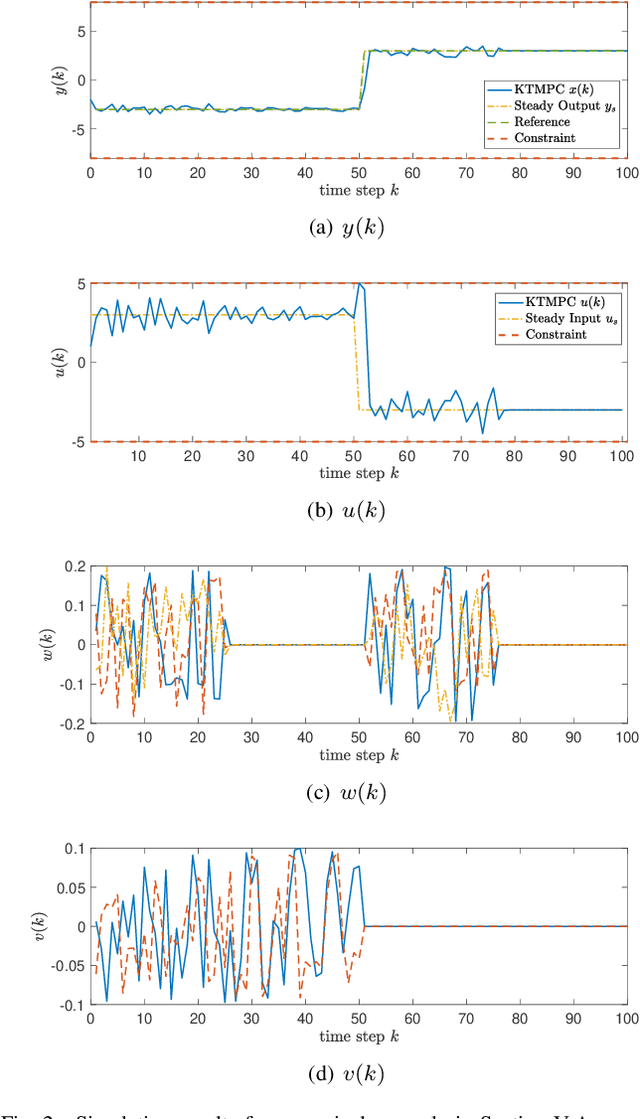
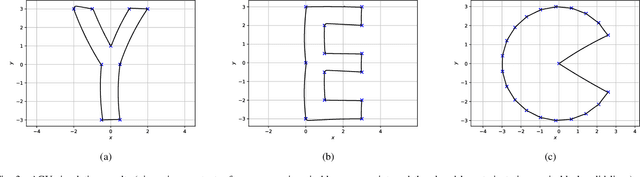
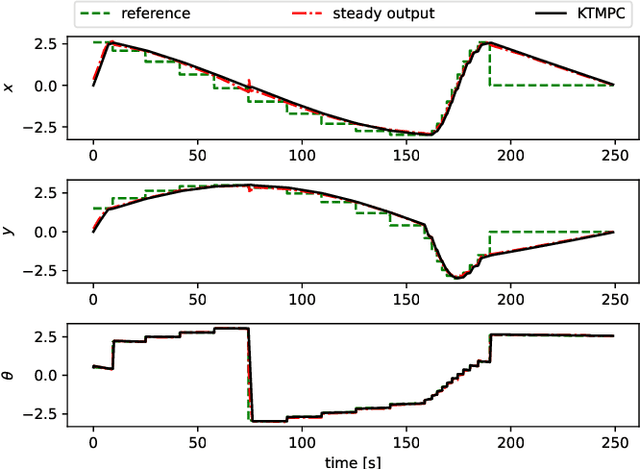
We seek to combine the nonlinear modeling capabilities of a wide class of neural networks with the safety guarantees of model predictive control (MPC) in a rigorous and online computationally tractable framework. The class of networks considered can be captured using Koopman operators, and are integrated into a Koopman-based tracking MPC (KTMPC) for nonlinear systems to track piecewise constant references. The effect of model mismatch between original nonlinear dynamics and its trained Koopman linear model is handled by using a constraint tightening approach in the proposed tracking MPC strategy. By choosing two Lyapunov candidate functions, we prove that solution is recursively feasible and input-to-state stable to a neighborhood of both online and offline optimal reachable steady outputs in the presence of bounded modeling errors. Finally, we show the results of a numerical example and an application of autonomous ground vehicle to track given references.
Safety-guaranteed trajectory planning and control based on GP estimation for unmanned surface vessels
May 10, 2022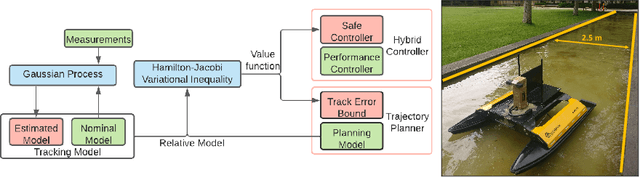
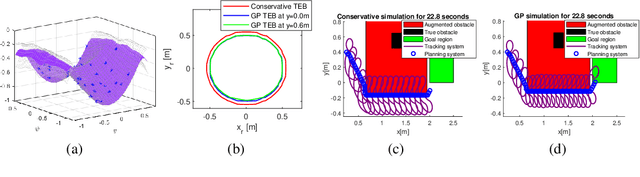
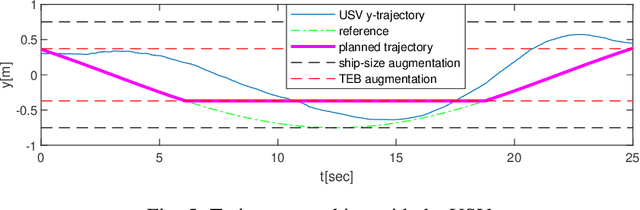
We propose a safety-guaranteed planning and control framework for unmanned surface vessels (USVs), using Gaussian processes (GPs) to learn uncertainties. The uncertainties encountered by USVs, including external disturbances and model mismatches, are potentially state-dependent, time-varying, and hard to capture with constant models. GP is a powerful learning-based tool that can be integrated with a model-based planning and control framework, which employs a Hamilton-Jacobi differential game formulation. Such a combination yields less conservative trajectories and safety-guaranteeing control strategies. We demonstrate the proposed framework in simulations and experiments on a CLEARPATH Heron USV.
FaSTrack: a Modular Framework for Real-Time Motion Planning and Guaranteed Safe Tracking
Mar 13, 2021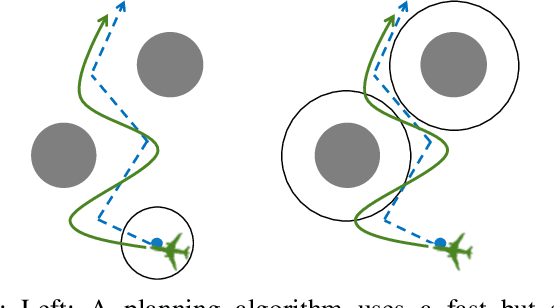
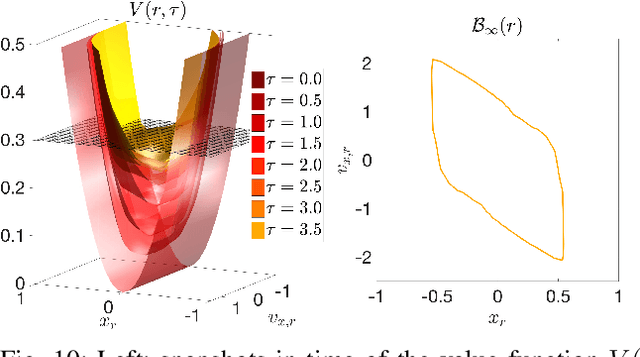
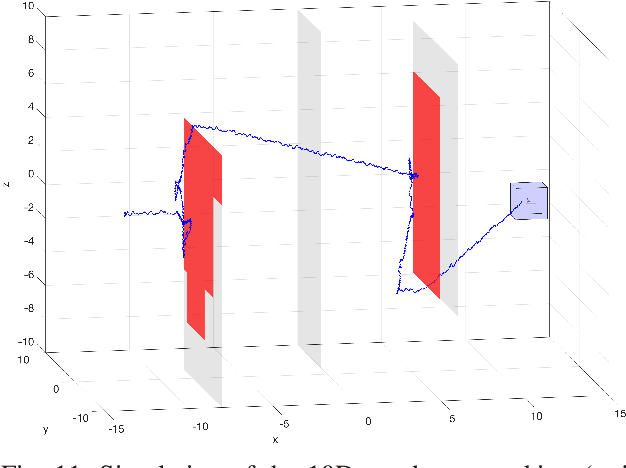
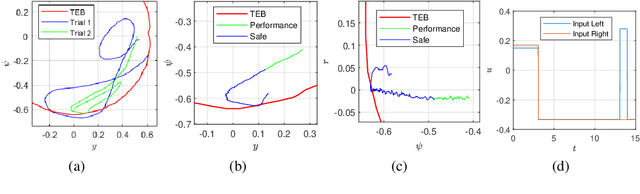
Real-time, guaranteed safe trajectory planning is vital for navigation in unknown environments. However, real-time navigation algorithms typically sacrifice robustness for computation speed. Alternatively, provably safe trajectory planning tends to be too computationally intensive for real-time replanning. We propose FaSTrack, Fast and Safe Tracking, a framework that achieves both real-time replanning and guaranteed safety. In this framework, real-time computation is achieved by allowing any trajectory planner to use a simplified \textit{planning model} of the system. The plan is tracked by the system, represented by a more realistic, higher-dimensional \textit{tracking model}. We precompute the tracking error bound (TEB) due to mismatch between the two models and due to external disturbances. We also obtain the corresponding tracking controller used to stay within the TEB. The precomputation does not require prior knowledge of the environment. We demonstrate FaSTrack using Hamilton-Jacobi reachability for precomputation and three different real-time trajectory planners with three different tracking-planning model pairs.