 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hamilton-Jacobi Reachability-Guided Search Framework for Efficient and Safe Indoor Planar Robot Navigation
Apr 20, 2026Autonomous navigation requires planning to reach a goal safely and efficiently in complex and potentially dynamic environments. Graph search-based algorithms are widely adopted due to their generality and theoretical guarantees when equipped with admissible heuristics. However, the computational complexity of graph search grows rapidly with the dimensionality of the search space, often making real-time planning in dynamic environments intractable. In this paper, we combine offline Hamilton-Jacobi (HJ) reachability with online graph search to leverage the complementary strengths of both. Precomputed HJ value functions, used as informative heuristics and proactive safety constraints, amortize online computation of the graph search process. At the same time, graph search enables reachability-based reasoning to be incorporated into online planning, overcoming the long-standing challenge of HJ reachability requiring full knowledge of the environment. Extensive simulation studies and real-world experiments demonstrate that the proposed approach consistently outperforms baseline methods in terms of planning efficiency and navigation safety, in environments with and without human presence.
Real-time Rendering-based Surgical Instrument Tracking via Evolutionary Optimization
Mar 12, 2026Accurate and efficient tracking of surgical instruments is fundamental for Robot-Assisted Minimally Invasive Surgery. Although vision-based robot pose estimation has enabled markerless calibration without tedious physical setups, reliable tool tracking for surgical robots still remains challenging due to partial visibility and specialized articulation design of surgical instruments. Previous works in the field are usually prone to unreliable feature detections under degraded visual quality and data scarcity, whereas rendering-based methods often struggle with computational costs and suboptimal convergence. In this work, we incorporate CMA-ES, an evolutionary optimization strategy, into a versatile tracking pipeline that jointly estimates surgical instrument pose and joint configurations. Using batch rendering to efficiently evaluate multiple pose candidates in parallel, the method significantly reduces inference time and improves convergence robustness. The proposed framework further generalizes to joint angle-free and bi-manual tracking settings, making it suitable for both vision feedback control and online surgery video calibration. Extensive experiments on synthetic and real-world datasets demonstrate that the proposed method significantly outperforms prior approaches in both accuracy and runtime.
Learning Robust Policies via Interpretable Hamilton-Jacobi Reachability-Guided Disturbances
Sep 29, 2024
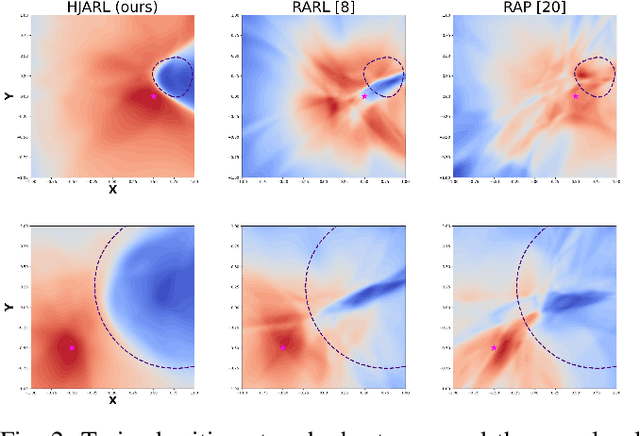
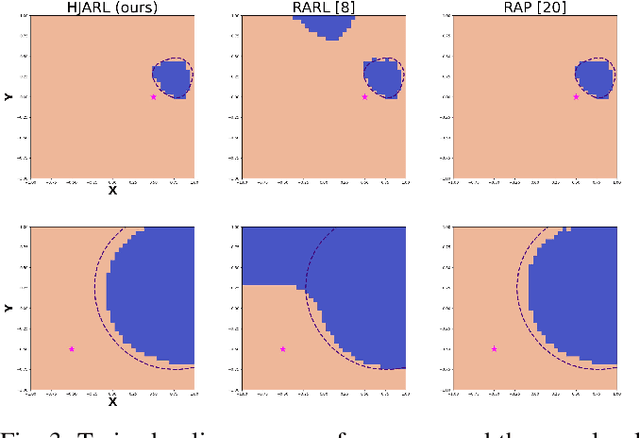

Deep Reinforcement Learning (RL) has shown remarkable success in robotics with complex and heterogeneous dynamics. However, its vulnerability to unknown disturbances and adversarial attacks remains a significant challenge. In this paper, we propose a robust policy training framework that integrates model-based control principles with adversarial RL training to improve robustness without the need for external black-box adversaries. Our approach introduces a novel Hamilton-Jacobi reachability-guided disturbance for adversarial RL training, where we use interpretable worst-case or near-worst-case disturbances as adversaries against the robust policy. We evaluated its effectiveness across three distinct tasks: a reach-avoid game in both simulation and real-world settings, and a highly dynamic quadrotor stabilization task in simulation. We validate that our learned critic network is consistent with the ground-truth HJ value function, while the policy network shows comparable performance with other learning-based methods.
Task-Oriented Koopman-Based Control with Contrastive Encoder
Sep 28, 2023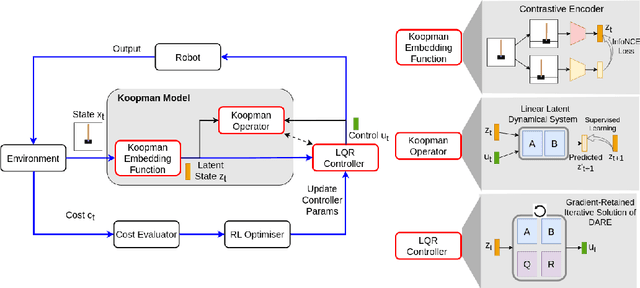
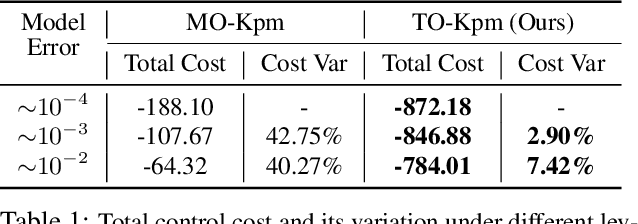
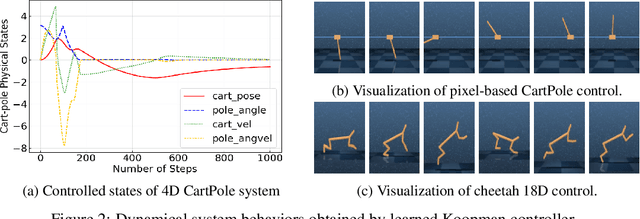
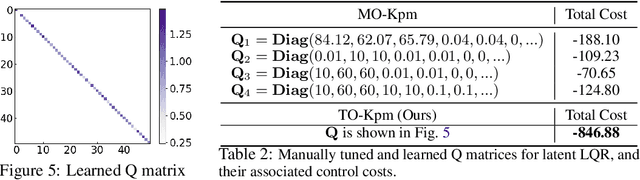
We present task-oriented Koopman-based control that utilizes end-to-end reinforcement learning and contrastive encoder to simultaneously learn the Koopman latent embedding, operator and associated linear controller within an iterative loop. By prioritizing the task cost as main objective for controller learning, we reduce the reliance of controller design on a well-identified model, which extends Koopman control beyond low-dimensional systems to high-dimensional, complex nonlinear systems, including pixel-based scenarios.