 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Robust Policies via Interpretable Hamilton-Jacobi Reachability-Guided Disturbances
Sep 29, 2024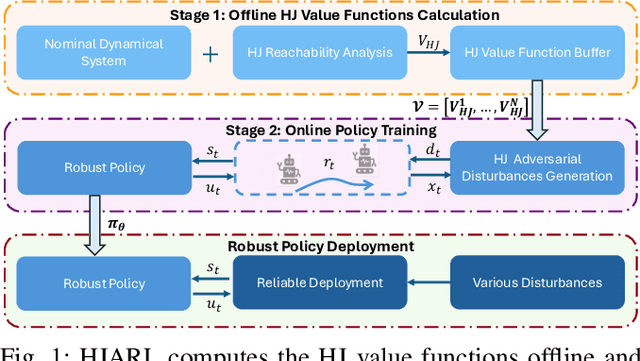
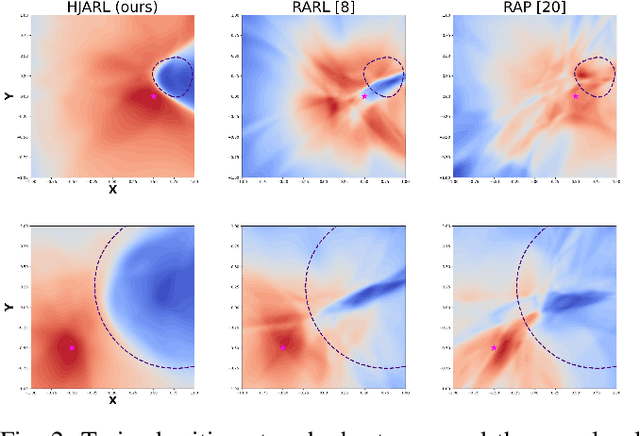
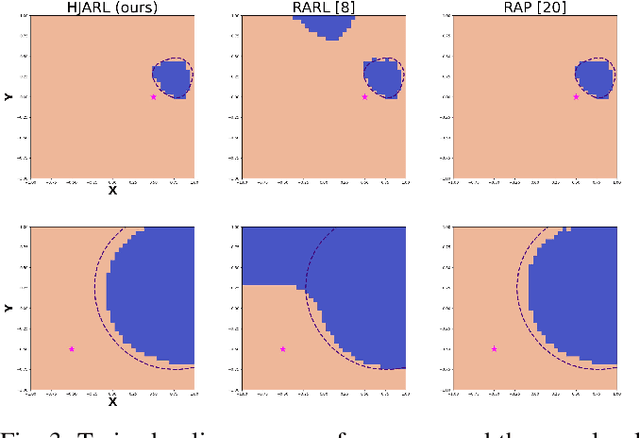

Deep Reinforcement Learning (RL) has shown remarkable success in robotics with complex and heterogeneous dynamics. However, its vulnerability to unknown disturbances and adversarial attacks remains a significant challenge. In this paper, we propose a robust policy training framework that integrates model-based control principles with adversarial RL training to improve robustness without the need for external black-box adversaries. Our approach introduces a novel Hamilton-Jacobi reachability-guided disturbance for adversarial RL training, where we use interpretable worst-case or near-worst-case disturbances as adversaries against the robust policy. We evaluated its effectiveness across three distinct tasks: a reach-avoid game in both simulation and real-world settings, and a highly dynamic quadrotor stabilization task in simulation. We validate that our learned critic network is consistent with the ground-truth HJ value function, while the policy network shows comparable performance with other learning-based methods.
Task-Oriented Koopman-Based Control with Contrastive Encoder
Sep 28, 2023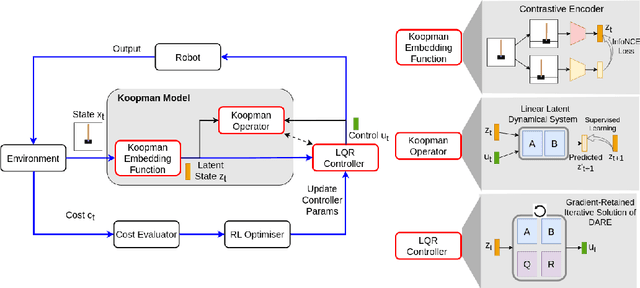
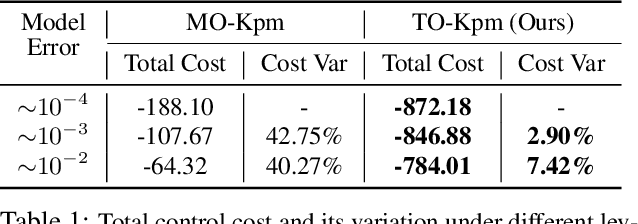
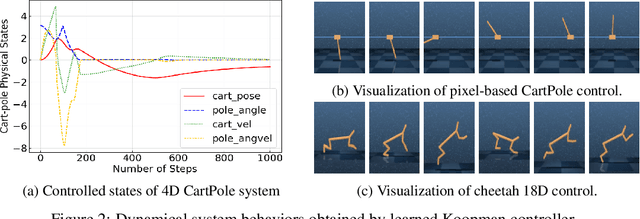
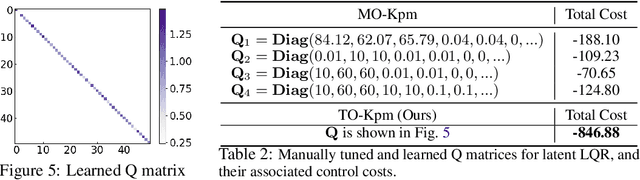
We present task-oriented Koopman-based control that utilizes end-to-end reinforcement learning and contrastive encoder to simultaneously learn the Koopman latent embedding, operator and associated linear controller within an iterative loop. By prioritizing the task cost as main objective for controller learning, we reduce the reliance of controller design on a well-identified model, which extends Koopman control beyond low-dimensional systems to high-dimensional, complex nonlinear systems, including pixel-based scenarios.
Multi-Agent Asynchronous Cooperation with Hierarchical Reinforcement Learning
Mar 29, 2022


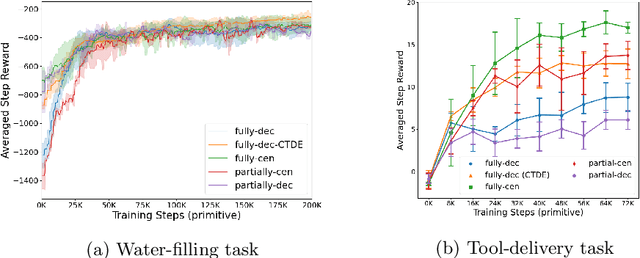
Hierarchical multi-agent reinforcement learning (MARL) has shown a significant learning efficiency by searching policy over higher-level, temporally extended actions (options). However, standard policy gradient-based MARL methods have a difficulty generalizing to option-based scenarios due to the asynchronous executions of multi-agent options. In this work, we propose a mathematical framework to enable policy gradient optimization over asynchronous multi-agent options by adjusting option-based policy distribution as well as trajectory probability. We study our method under a set of multi-agent cooperative setups with varying inter-dependency levels, and evaluate the effectiveness of our method on typical option-based multi-agent cooperation tasks.
MBVI: Model-Based Value Initialization for Reinforcement Learning
Nov 04, 2020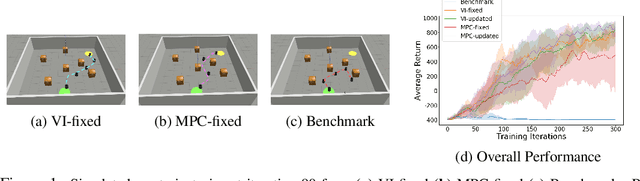
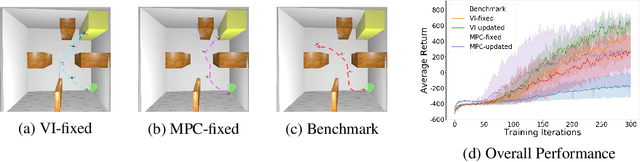
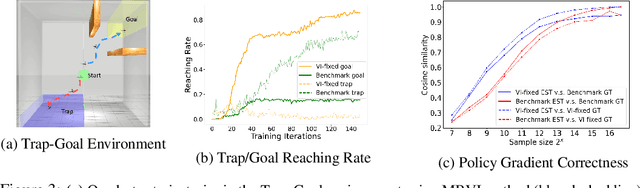
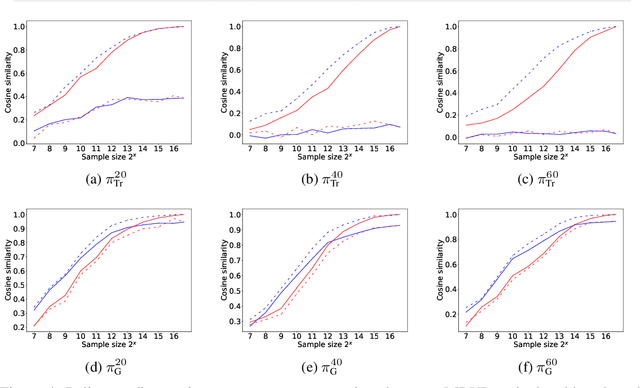
Model-free reinforcement learning (RL) is capable of learning control policies for high-dimensional, complex robotic tasks, but tends to be data inefficient. Model-based RL and optimal control have been proven to be much more data-efficient if an accurate model of the system and environment is known, but can be difficult to scale to expressive models for high-dimensional problems. In this paper, we propose a novel approach to alleviate data inefficiency of model-free RL by warm-starting the learning process using model-based solutions. We do so by initializing a high-dimensional value function via supervision from a low-dimensional value function obtained by applying model-based techniques on a low-dimensional problem featuring an approximate system model. Therefore, our approach exploits the model priors from a simplified problem space implicitly and avoids the direct use of high-dimensional, expressive models. We demonstrate our approach on two representative robotic learning tasks and observe significant improvements in performance and efficiency, and analyze our method empirically with a third task.
TTR-Based Rewards for Reinforcement Learning with Implicit Model Priors
Mar 23, 2019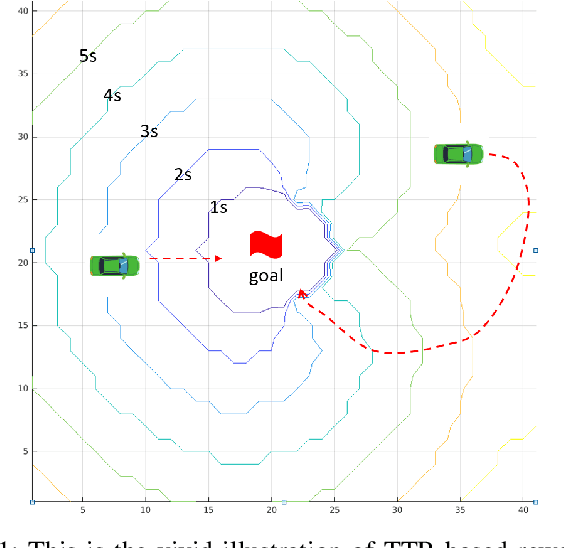
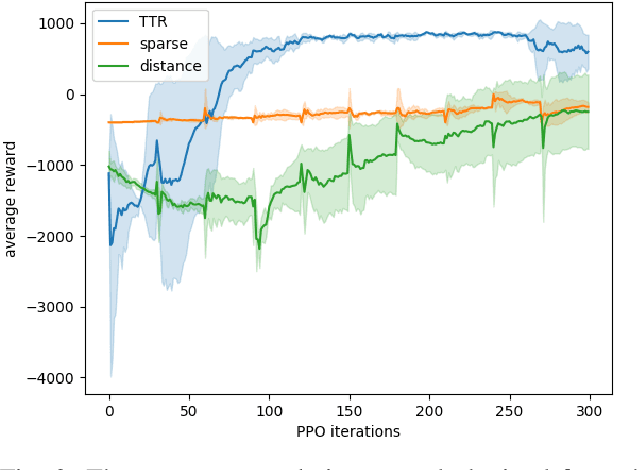
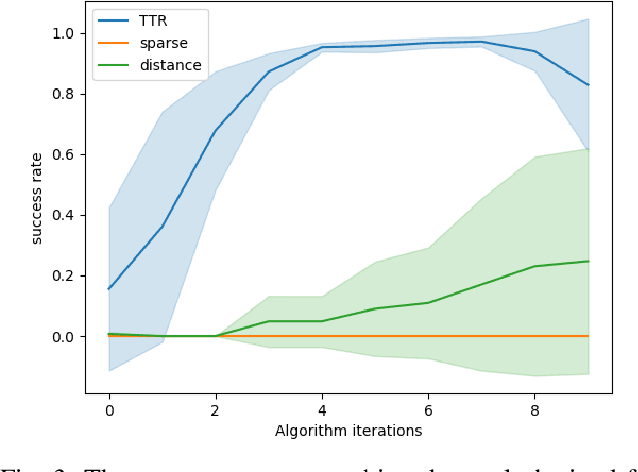
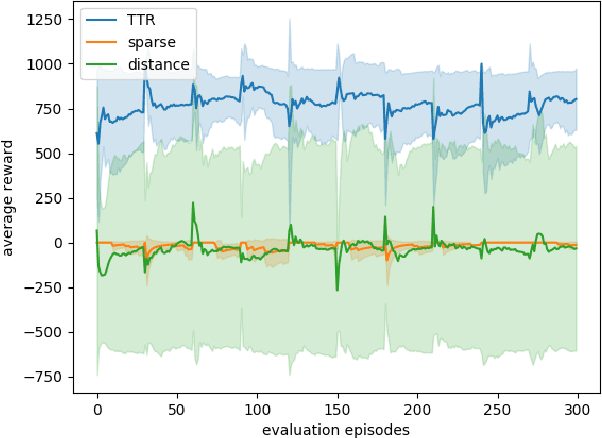
Model-free reinforcement learning (RL) provides an attractive approach for learning control policies directly in high dimensional state spaces. However, many goal-oriented tasks involving sparse rewards remain difficult to solve with state-of-the-art model-free RL algorithms, even in simulation. One of the key difficulties is that deep RL, due to its relatively poor sample complexity, often requires a prohibitive number of trials to obtain a learning signal. We propose a novel, non-sparse reward function for robotic RL tasks by leveraging physical priors in the form of a time-to-reach (TTR) function computed from an approximate system dynamics model. TTR functions come from the optimal control field and measure the minimal time required to move from any state to the goal. However, TTR functions are intractable to compute for complex systems, so we compute it in a lower-dimensional state space, and then do a simple transformation to convert it into a TTR-based reward function for the MDP in RL tasks. Our TTR-based reward function provides highly-informative rewards that account for system dynamics.