 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTTR-Based Rewards for Reinforcement Learning with Implicit Model Priors
Paper and Code
Mar 23, 2019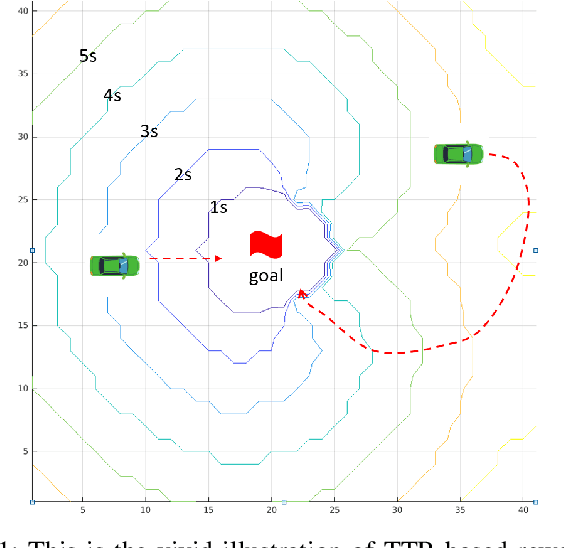
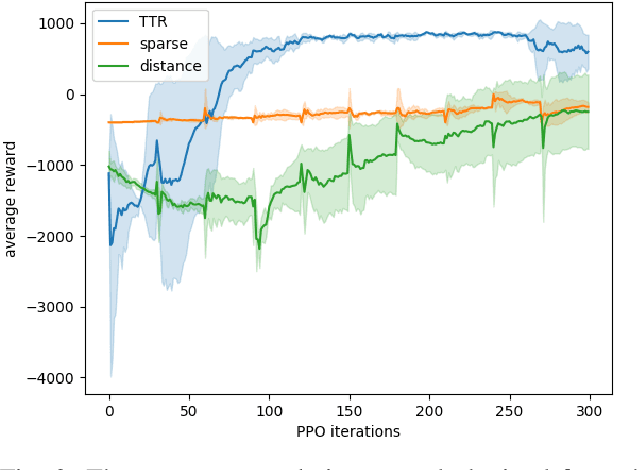
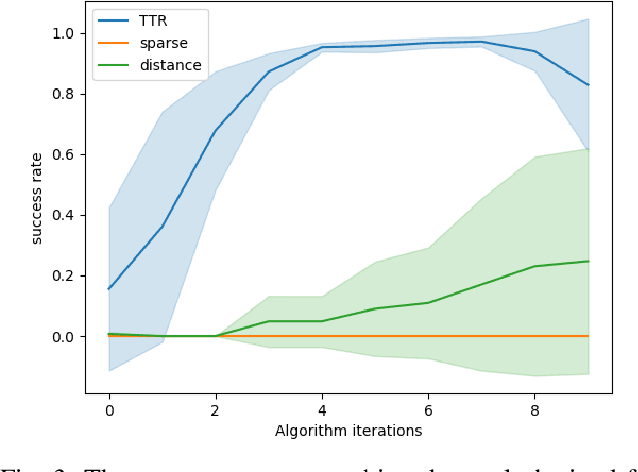
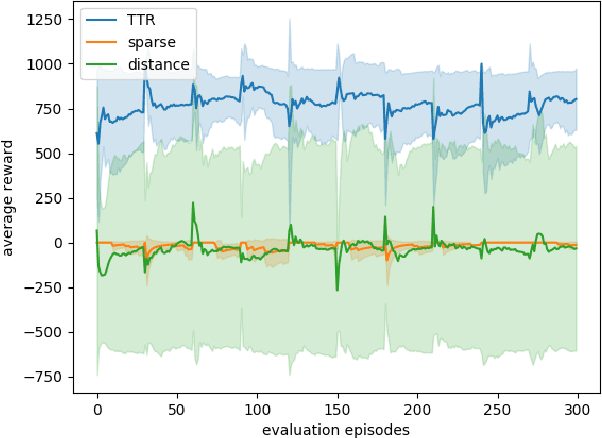
Model-free reinforcement learning (RL) provides an attractive approach for learning control policies directly in high dimensional state spaces. However, many goal-oriented tasks involving sparse rewards remain difficult to solve with state-of-the-art model-free RL algorithms, even in simulation. One of the key difficulties is that deep RL, due to its relatively poor sample complexity, often requires a prohibitive number of trials to obtain a learning signal. We propose a novel, non-sparse reward function for robotic RL tasks by leveraging physical priors in the form of a time-to-reach (TTR) function computed from an approximate system dynamics model. TTR functions come from the optimal control field and measure the minimal time required to move from any state to the goal. However, TTR functions are intractable to compute for complex systems, so we compute it in a lower-dimensional state space, and then do a simple transformation to convert it into a TTR-based reward function for the MDP in RL tasks. Our TTR-based reward function provides highly-informative rewards that account for system dynamics.