 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable and Realistic Virtual Try-on Application for Foundation Makeup with Kubelka-Munk Theory
Jul 09, 2025Augmented reality is revolutionizing beauty industry with virtual try-on (VTO) applications, which empowers users to try a wide variety of products using their phones without the hassle of physically putting on real products. A critical technical challenge in foundation VTO applications is the accurate synthesis of foundation-skin tone color blending while maintaining the scalability of the method across diverse product ranges. In this work, we propose a novel method to approximate well-established Kubelka-Munk (KM) theory for faster image synthesis while preserving foundation-skin tone color blending realism. Additionally, we build a scalable end-to-end framework for realistic foundation makeup VTO solely depending on the product information available on e-commerce sites. We validate our method using real-world makeup images, demonstrating that our framework outperforms other techniques.
Automated Material Properties Extraction For Enhanced Beauty Product Discovery and Makeup Virtual Try-on
Dec 01, 2023The multitude of makeup products available can make it challenging to find the ideal match for desired attributes. An intelligent approach for product discovery is required to enhance the makeup shopping experience to make it more convenient and satisfying. However, enabling accurate and efficient product discovery requires extracting detailed attributes like color and finish type. Our work introduces an automated pipeline that utilizes multiple customized machine learning models to extract essential material attributes from makeup product images. Our pipeline is versatile and capable of handling various makeup products. To showcase the efficacy of our pipeline, we conduct extensive experiments on eyeshadow products (both single and multi-shade ones), a challenging makeup product known for its diverse range of shapes, colors, and finish types. Furthermore, we demonstrate the applicability of our approach by successfully extending it to other makeup categories like lipstick and foundation, showcasing its adaptability and effectiveness across different beauty products. Additionally, we conduct ablation experiments to demonstrate the superiority of our machine learning pipeline over human labeling methods in terms of reliability. Our proposed method showcases its effectiveness in cross-category product discovery, specifically in recommending makeup products that perfectly match a specified outfit. Lastly, we also demonstrate the application of these material attributes in enabling virtual-try-on experiences which makes makeup shopping experience significantly more engaging.
Exact Combinatorial Optimization with Temporo-Attentional Graph Neural Networks
Nov 23, 2023Combinatorial optimization finds an optimal solution within a discrete set of variables and constraints. The field has seen tremendous progress both in research and industry. With the success of deep learning in the past decade, a recent trend in combinatorial optimization has been to improve state-of-the-art combinatorial optimization solvers by replacing key heuristic components with machine learning (ML) models. In this paper, we investigate two essential aspects of machine learning algorithms for combinatorial optimization: temporal characteristics and attention. We argue that for the task of variable selection in the branch-and-bound (B&B) algorithm, incorporating the temporal information as well as the bipartite graph attention improves the solver's performance. We support our claims with intuitions and numerical results over several standard datasets used in the literature and competitions. Code is available at: https://developer.huaweicloud.com/develop/aigallery/notebook/detail?id=047c6cf2-8463-40d7-b92f-7b2ca998e935
* ECML PKDD 2023
ArchBERT: Bi-Modal Understanding of Neural Architectures and Natural Languages
Oct 26, 2023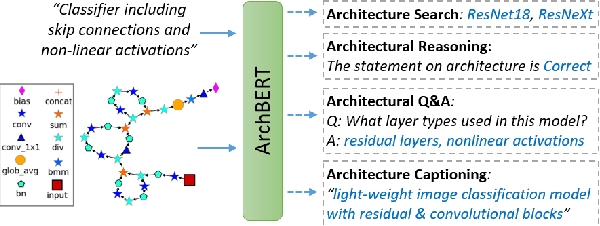


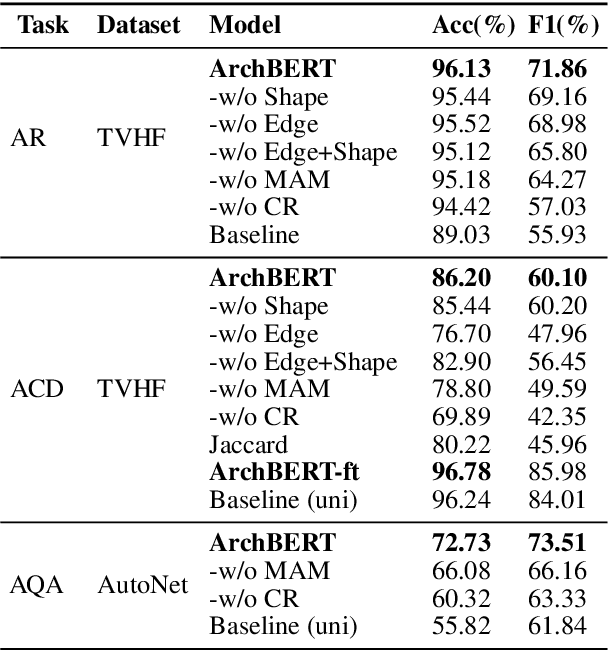
Building multi-modal language models has been a trend in the recent years, where additional modalities such as image, video, speech, etc. are jointly learned along with natural languages (i.e., textual information). Despite the success of these multi-modal language models with different modalities, there is no existing solution for neural network architectures and natural languages. Providing neural architectural information as a new modality allows us to provide fast architecture-2-text and text-2-architecture retrieval/generation services on the cloud with a single inference. Such solution is valuable in terms of helping beginner and intermediate ML users to come up with better neural architectures or AutoML approaches with a simple text query. In this paper, we propose ArchBERT, a bi-modal model for joint learning and understanding of neural architectures and natural languages, which opens up new avenues for research in this area. We also introduce a pre-training strategy named Masked Architecture Modeling (MAM) for a more generalized joint learning. Moreover, we introduce and publicly release two new bi-modal datasets for training and validating our methods. The ArchBERT's performance is verified through a set of numerical experiments on different downstream tasks such as architecture-oriented reasoning, question answering, and captioning (summarization). Datasets, codes, and demos are available supplementary materials.
Improving the Accuracy of Beauty Product Recommendations by Assessing Face Illumination Quality
Sep 07, 2023We focus on addressing the challenges in responsible beauty product recommendation, particularly when it involves comparing the product's color with a person's skin tone, such as for foundation and concealer products. To make accurate recommendations, it is crucial to infer both the product attributes and the product specific facial features such as skin conditions or tone. However, while many product photos are taken under good light conditions, face photos are taken from a wide range of conditions. The features extracted using the photos from ill-illuminated environment can be highly misleading or even be incompatible to be compared with the product attributes. Hence bad illumination condition can severely degrade quality of the recommendation. We introduce a machine learning framework for illumination assessment which classifies images into having either good or bad illumination condition. We then build an automatic user guidance tool which informs a user holding their camera if their illumination condition is good or bad. This way, the user is provided with rapid feedback and can interactively control how the photo is taken for their recommendation. Only a few studies are dedicated to this problem, mostly due to the lack of dataset that is large, labeled, and diverse both in terms of skin tones and light patterns. Lack of such dataset leads to neglecting skin tone diversity. Therefore, We begin by constructing a diverse synthetic dataset that simulates various skin tones and light patterns in addition to an existing facial image dataset. Next, we train a Convolutional Neural Network (CNN) for illumination assessment that outperforms the existing solutions using the synthetic dataset. Finally, we analyze how the our work improves the shade recommendation for various foundation products.
NL4Opt Competition: Formulating Optimization Problems Based on Their Natural Language Descriptions
Mar 27, 2023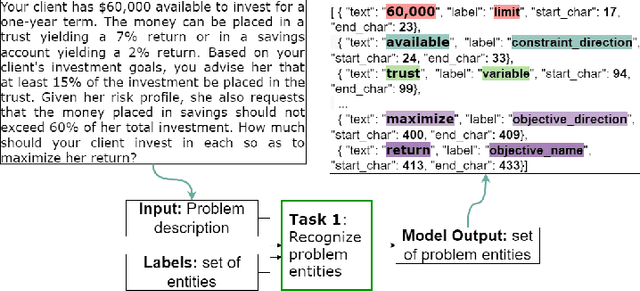

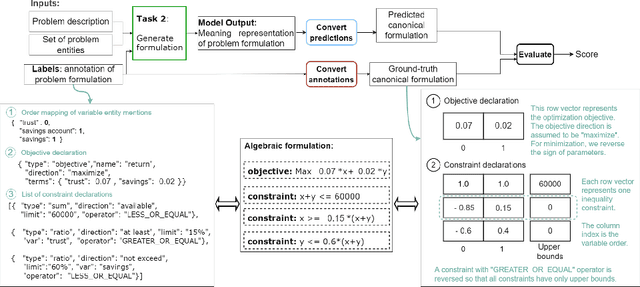
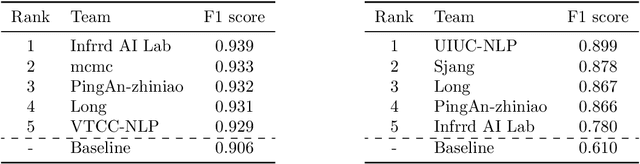
The Natural Language for Optimization (NL4Opt) Competition was created to investigate methods of extracting the meaning and formulation of an optimization problem based on its text description. Specifically, the goal of the competition is to increase the accessibility and usability of optimization solvers by allowing non-experts to interface with them using natural language. We separate this challenging goal into two sub-tasks: (1) recognize and label the semantic entities that correspond to the components of the optimization problem; (2) generate a meaning representation (i.e., a logical form) of the problem from its detected problem entities. The first task aims to reduce ambiguity by detecting and tagging the entities of the optimization problems. The second task creates an intermediate representation of the linear programming (LP) problem that is converted into a format that can be used by commercial solvers. In this report, we present the LP word problem dataset and shared tasks for the NeurIPS 2022 competition. Furthermore, we investigate and compare the performance of the ChatGPT large language model against the winning solutions. Through this competition, we hope to bring interest towards the development of novel machine learning applications and datasets for optimization modeling.
Augmenting Operations Research with Auto-Formulation of Optimization Models from Problem Descriptions
Oct 11, 2022



We describe an augmented intelligence system for simplifying and enhancing the modeling experience for operations research. Using this system, the user receives a suggested formulation of an optimization problem based on its description. To facilitate this process, we build an intuitive user interface system that enables the users to validate and edit the suggestions. We investigate controlled generation techniques to obtain an automatic suggestion of formulation. Then, we evaluate their effectiveness with a newly created dataset of linear programming problems drawn from various application domains.
SemAug: Semantically Meaningful Image Augmentations for Object Detection Through Language Grounding
Aug 15, 2022
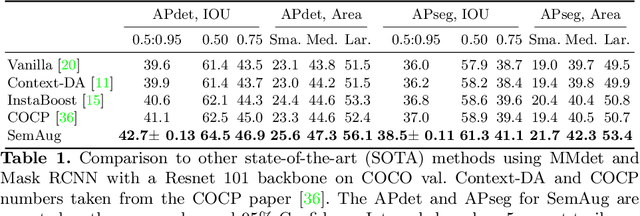

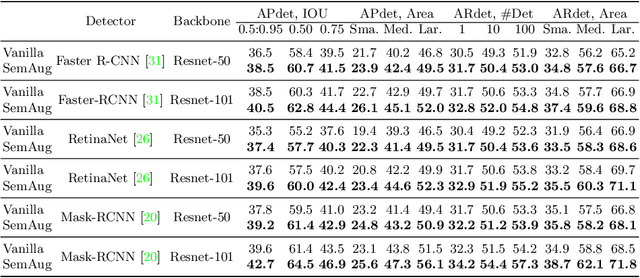
Data augmentation is an essential technique in improving the generalization of deep neural networks. The majority of existing image-domain augmentations either rely on geometric and structural transformations, or apply different kinds of photometric distortions. In this paper, we propose an effective technique for image augmentation by injecting contextually meaningful knowledge into the scenes. Our method of semantically meaningful image augmentation for object detection via language grounding, SemAug, starts by calculating semantically appropriate new objects that can be placed into relevant locations in the image (the what and where problems). Then it embeds these objects into their relevant target locations, thereby promoting diversity of object instance distribution. Our method allows for introducing new object instances and categories that may not even exist in the training set. Furthermore, it does not require the additional overhead of training a context network, so it can be easily added to existing architectures. Our comprehensive set of evaluations showed that the proposed method is very effective in improving the generalization, while the overhead is negligible. In particular, for a wide range of model architectures, our method achieved ~2-4% and ~1-2% mAP improvements for the task of object detection on the Pascal VOC and COCO datasets, respectively.
Deep Reinforcement Learning for Exact Combinatorial Optimization: Learning to Branch
Jun 14, 2022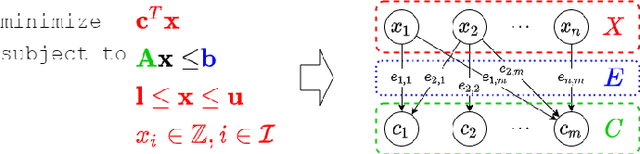
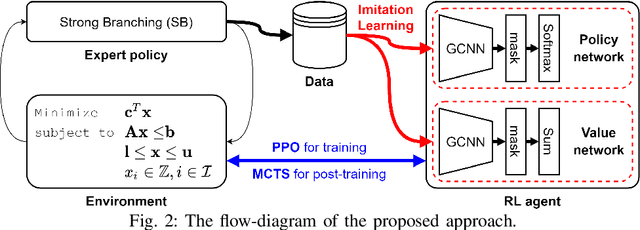

Branch-and-bound is a systematic enumerative method for combinatorial optimization, where the performance highly relies on the variable selection strategy. State-of-the-art handcrafted heuristic strategies suffer from relatively slow inference time for each selection, while the current machine learning methods require a significant amount of labeled data. We propose a new approach for solving the data labeling and inference latency issues in combinatorial optimization based on the use of the reinforcement learning (RL) paradigm. We use imitation learning to bootstrap an RL agent and then use Proximal Policy Optimization (PPO) to further explore global optimal actions. Then, a value network is used to run Monte-Carlo tree search (MCTS) to enhance the policy network. We evaluate the performance of our method on four different categories of combinatorial optimization problems and show that our approach performs strongly compared to the state-of-the-art machine learning and heuristics based methods.
AuxMix: Semi-Supervised Learning with Unconstrained Unlabeled Data
Jun 14, 2022
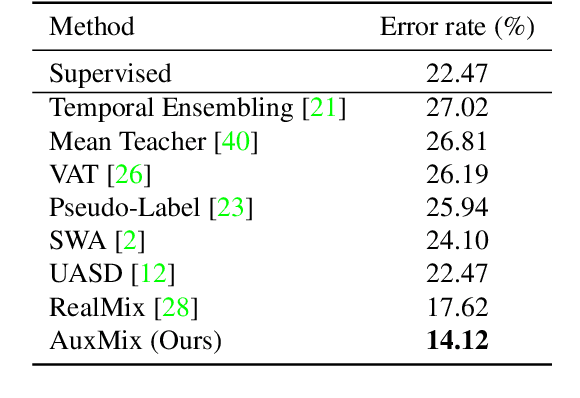

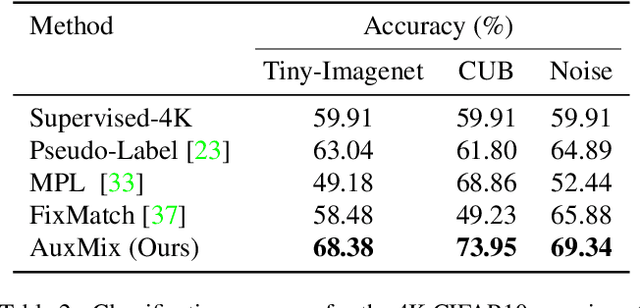
Semi-supervised learning (SSL) has seen great strides when labeled data is scarce but unlabeled data is abundant. Critically, most recent work assume that such unlabeled data is drawn from the same distribution as the labeled data. In this work, we show that state-of-the-art SSL algorithms suffer a degradation in performance in the presence of unlabeled auxiliary data that does not necessarily possess the same class distribution as the labeled set. We term this problem as Auxiliary-SSL and propose AuxMix, an algorithm that leverages self-supervised learning tasks to learn generic features in order to mask auxiliary data that are not semantically similar to the labeled set. We also propose to regularize learning by maximizing the predicted entropy for dissimilar auxiliary samples. We show an improvement of 5% over existing baselines on a ResNet-50 model when trained on CIFAR10 dataset with 4k labeled samples and all unlabeled data is drawn from the Tiny-ImageNet dataset. We report competitive results on several datasets and conduct ablation studies.