 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Material Properties Extraction For Enhanced Beauty Product Discovery and Makeup Virtual Try-on
Dec 01, 2023The multitude of makeup products available can make it challenging to find the ideal match for desired attributes. An intelligent approach for product discovery is required to enhance the makeup shopping experience to make it more convenient and satisfying. However, enabling accurate and efficient product discovery requires extracting detailed attributes like color and finish type. Our work introduces an automated pipeline that utilizes multiple customized machine learning models to extract essential material attributes from makeup product images. Our pipeline is versatile and capable of handling various makeup products. To showcase the efficacy of our pipeline, we conduct extensive experiments on eyeshadow products (both single and multi-shade ones), a challenging makeup product known for its diverse range of shapes, colors, and finish types. Furthermore, we demonstrate the applicability of our approach by successfully extending it to other makeup categories like lipstick and foundation, showcasing its adaptability and effectiveness across different beauty products. Additionally, we conduct ablation experiments to demonstrate the superiority of our machine learning pipeline over human labeling methods in terms of reliability. Our proposed method showcases its effectiveness in cross-category product discovery, specifically in recommending makeup products that perfectly match a specified outfit. Lastly, we also demonstrate the application of these material attributes in enabling virtual-try-on experiences which makes makeup shopping experience significantly more engaging.
Echo-SyncNet: Self-supervised Cardiac View Synchronization in Echocardiography
Feb 03, 2021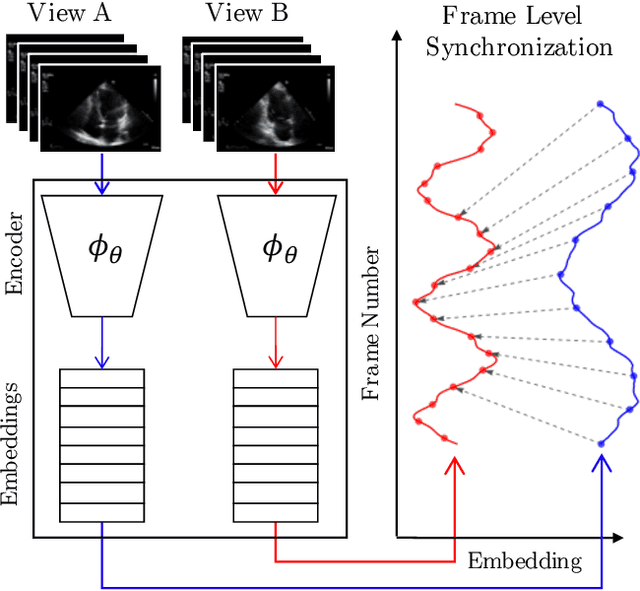
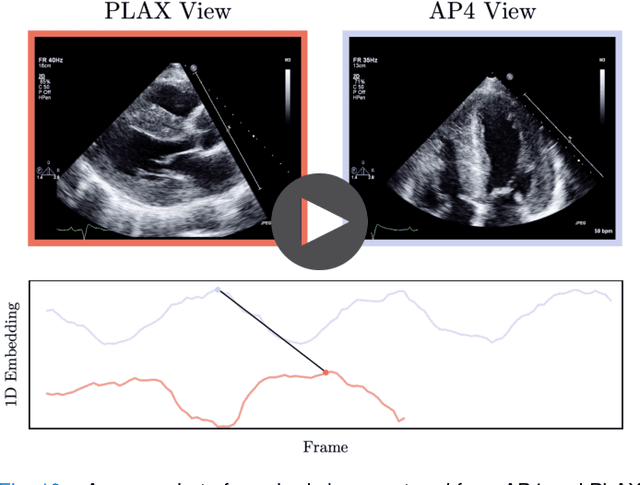
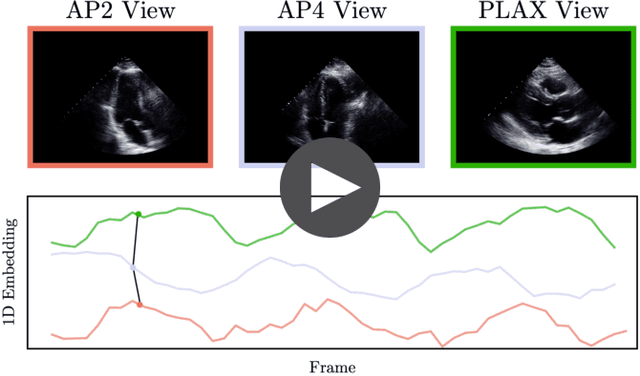
In echocardiography (echo), an electrocardiogram (ECG) is conventionally used to temporally align different cardiac views for assessing critical measurements. However, in emergencies or point-of-care situations, acquiring an ECG is often not an option, hence motivating the need for alternative temporal synchronization methods. Here, we propose Echo-SyncNet, a self-supervised learning framework to synchronize various cross-sectional 2D echo series without any external input. The proposed framework takes advantage of both intra-view and inter-view self supervisions. The former relies on spatiotemporal patterns found between the frames of a single echo cine and the latter on the interdependencies between multiple cines. The combined supervisions are used to learn a feature-rich embedding space where multiple echo cines can be temporally synchronized. We evaluate the framework with multiple experiments: 1) Using data from 998 patients, Echo-SyncNet shows promising results for synchronizing Apical 2 chamber and Apical 4 chamber cardiac views; 2) Using data from 3070 patients, our experiments reveal that the learned representations of Echo-SyncNet outperform a supervised deep learning method that is optimized for automatic detection of fine-grained cardiac phase; 3) We show the usefulness of the learned representations in a one-shot learning scenario of cardiac keyframe detection. Without any fine-tuning, keyframes in 1188 validation patient studies are identified by synchronizing them with only one labeled reference study. We do not make any prior assumption about what specific cardiac views are used for training and show that Echo-SyncNet can accurately generalize to views not present in its training set. Project repository: github.com/fatemehtd/Echo-SyncNet.
Reciprocal Landmark Detection and Tracking with Extremely Few Annotations
Jan 27, 2021
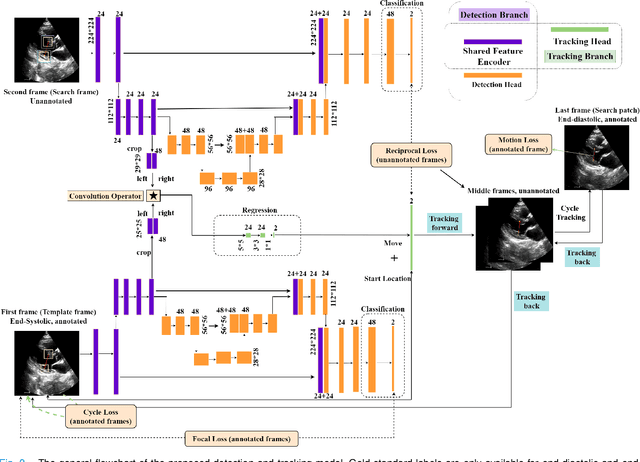
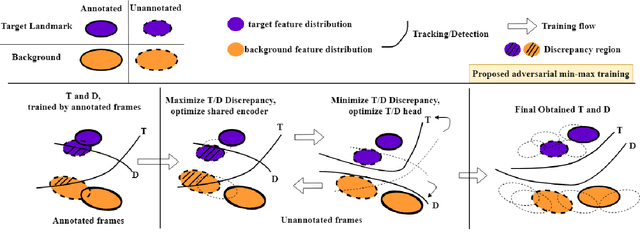
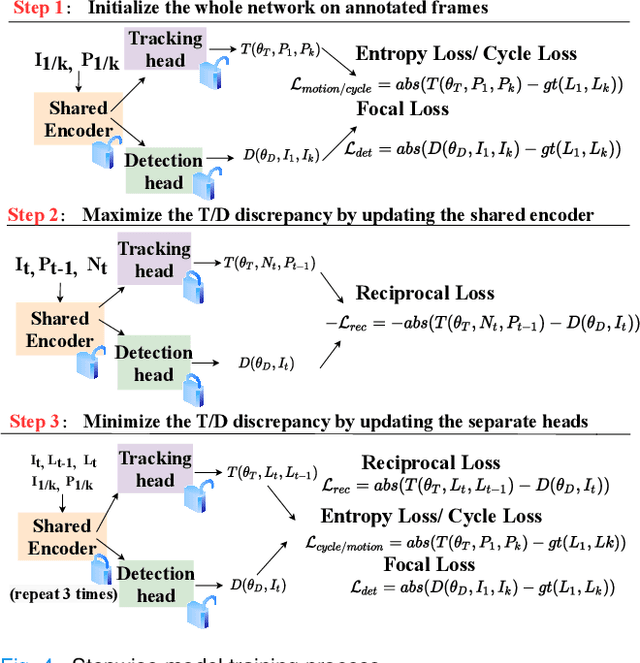
Localization of anatomical landmarks to perform two-dimensional measurements in echocardiography is part of routine clinical workflow in cardiac disease diagnosis. Automatic localization of those landmarks is highly desirable to improve workflow and reduce interobserver variability. Training a machine learning framework to perform such localization is hindered given the sparse nature of gold standard labels; only few percent of cardiac cine series frames are normally manually labeled for clinical use. In this paper, we propose a new end-to-end reciprocal detection and tracking model that is specifically designed to handle the sparse nature of echocardiography labels. The model is trained using few annotated frames across the entire cardiac cine sequence to generate consistent detection and tracking of landmarks, and an adversarial training for the model is proposed to take advantage of these annotated frames. The superiority of the proposed reciprocal model is demonstrated using a series of experiments.