 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable and Realistic Virtual Try-on Application for Foundation Makeup with Kubelka-Munk Theory
Jul 09, 2025Augmented reality is revolutionizing beauty industry with virtual try-on (VTO) applications, which empowers users to try a wide variety of products using their phones without the hassle of physically putting on real products. A critical technical challenge in foundation VTO applications is the accurate synthesis of foundation-skin tone color blending while maintaining the scalability of the method across diverse product ranges. In this work, we propose a novel method to approximate well-established Kubelka-Munk (KM) theory for faster image synthesis while preserving foundation-skin tone color blending realism. Additionally, we build a scalable end-to-end framework for realistic foundation makeup VTO solely depending on the product information available on e-commerce sites. We validate our method using real-world makeup images, demonstrating that our framework outperforms other techniques.
Automated Material Properties Extraction For Enhanced Beauty Product Discovery and Makeup Virtual Try-on
Dec 01, 2023The multitude of makeup products available can make it challenging to find the ideal match for desired attributes. An intelligent approach for product discovery is required to enhance the makeup shopping experience to make it more convenient and satisfying. However, enabling accurate and efficient product discovery requires extracting detailed attributes like color and finish type. Our work introduces an automated pipeline that utilizes multiple customized machine learning models to extract essential material attributes from makeup product images. Our pipeline is versatile and capable of handling various makeup products. To showcase the efficacy of our pipeline, we conduct extensive experiments on eyeshadow products (both single and multi-shade ones), a challenging makeup product known for its diverse range of shapes, colors, and finish types. Furthermore, we demonstrate the applicability of our approach by successfully extending it to other makeup categories like lipstick and foundation, showcasing its adaptability and effectiveness across different beauty products. Additionally, we conduct ablation experiments to demonstrate the superiority of our machine learning pipeline over human labeling methods in terms of reliability. Our proposed method showcases its effectiveness in cross-category product discovery, specifically in recommending makeup products that perfectly match a specified outfit. Lastly, we also demonstrate the application of these material attributes in enabling virtual-try-on experiences which makes makeup shopping experience significantly more engaging.
Improving the Accuracy of Beauty Product Recommendations by Assessing Face Illumination Quality
Sep 07, 2023We focus on addressing the challenges in responsible beauty product recommendation, particularly when it involves comparing the product's color with a person's skin tone, such as for foundation and concealer products. To make accurate recommendations, it is crucial to infer both the product attributes and the product specific facial features such as skin conditions or tone. However, while many product photos are taken under good light conditions, face photos are taken from a wide range of conditions. The features extracted using the photos from ill-illuminated environment can be highly misleading or even be incompatible to be compared with the product attributes. Hence bad illumination condition can severely degrade quality of the recommendation. We introduce a machine learning framework for illumination assessment which classifies images into having either good or bad illumination condition. We then build an automatic user guidance tool which informs a user holding their camera if their illumination condition is good or bad. This way, the user is provided with rapid feedback and can interactively control how the photo is taken for their recommendation. Only a few studies are dedicated to this problem, mostly due to the lack of dataset that is large, labeled, and diverse both in terms of skin tones and light patterns. Lack of such dataset leads to neglecting skin tone diversity. Therefore, We begin by constructing a diverse synthetic dataset that simulates various skin tones and light patterns in addition to an existing facial image dataset. Next, we train a Convolutional Neural Network (CNN) for illumination assessment that outperforms the existing solutions using the synthetic dataset. Finally, we analyze how the our work improves the shade recommendation for various foundation products.
Generating Music with a Self-Correcting Non-Chronological Autoregressive Model
Aug 18, 2020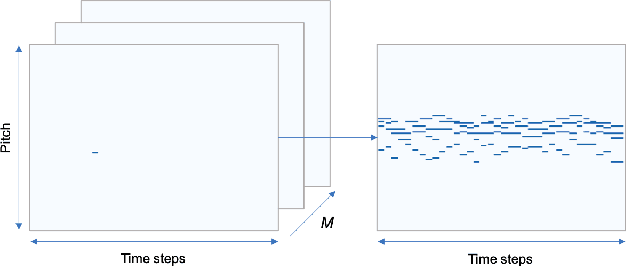

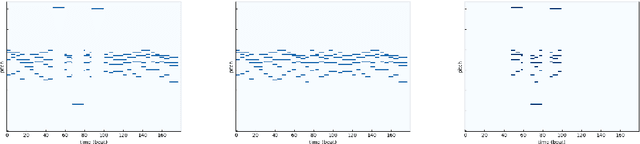
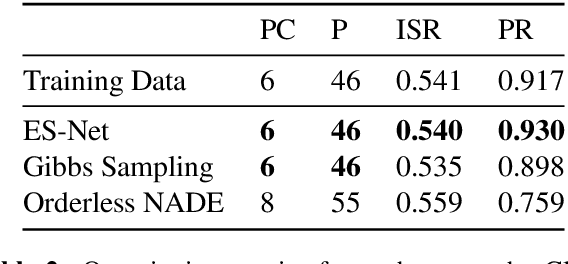
We describe a novel approach for generating music using a self-correcting, non-chronological, autoregressive model. We represent music as a sequence of edit events, each of which denotes either the addition or removal of a note---even a note previously generated by the model. During inference, we generate one edit event at a time using direct ancestral sampling. Our approach allows the model to fix previous mistakes such as incorrectly sampled notes and prevent accumulation of errors which autoregressive models are prone to have. Another benefit is a finer, note-by-note control during human and AI collaborative composition. We show through quantitative metrics and human survey evaluation that our approach generates better results than orderless NADE and Gibbs sampling approaches.