 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Music with a Self-Correcting Non-Chronological Autoregressive Model
Paper and Code
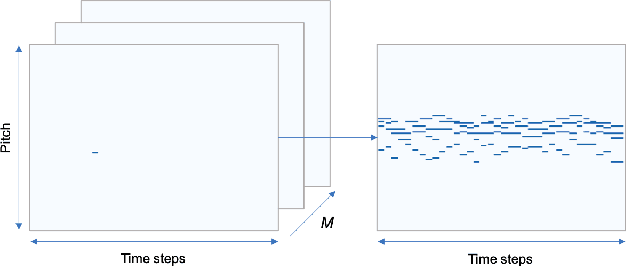

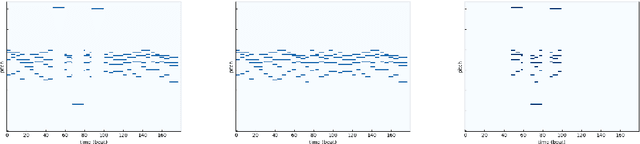
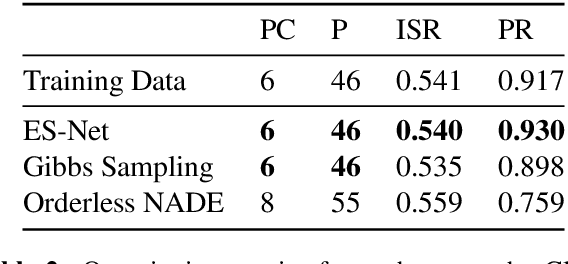
We describe a novel approach for generating music using a self-correcting, non-chronological, autoregressive model. We represent music as a sequence of edit events, each of which denotes either the addition or removal of a note---even a note previously generated by the model. During inference, we generate one edit event at a time using direct ancestral sampling. Our approach allows the model to fix previous mistakes such as incorrectly sampled notes and prevent accumulation of errors which autoregressive models are prone to have. Another benefit is a finer, note-by-note control during human and AI collaborative composition. We show through quantitative metrics and human survey evaluation that our approach generates better results than orderless NADE and Gibbs sampling approaches.