 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExact Combinatorial Optimization with Temporo-Attentional Graph Neural Networks
Nov 23, 2023Combinatorial optimization finds an optimal solution within a discrete set of variables and constraints. The field has seen tremendous progress both in research and industry. With the success of deep learning in the past decade, a recent trend in combinatorial optimization has been to improve state-of-the-art combinatorial optimization solvers by replacing key heuristic components with machine learning (ML) models. In this paper, we investigate two essential aspects of machine learning algorithms for combinatorial optimization: temporal characteristics and attention. We argue that for the task of variable selection in the branch-and-bound (B&B) algorithm, incorporating the temporal information as well as the bipartite graph attention improves the solver's performance. We support our claims with intuitions and numerical results over several standard datasets used in the literature and competitions. Code is available at: https://developer.huaweicloud.com/develop/aigallery/notebook/detail?id=047c6cf2-8463-40d7-b92f-7b2ca998e935
* ECML PKDD 2023
Spatial Cross-Attention Improves Self-Supervised Visual Representation Learning
Jun 07, 2022
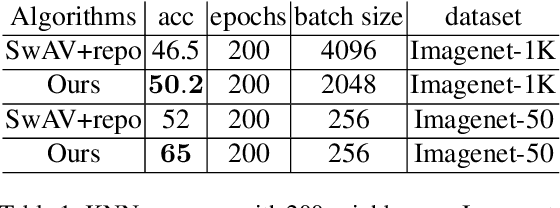


Unsupervised representation learning methods like SwAV are proved to be effective in learning visual semantics of a target dataset. The main idea behind these methods is that different views of a same image represent the same semantics. In this paper, we further introduce an add-on module to facilitate the injection of the knowledge accounting for spatial cross correlations among the samples. This in turn results in distilling intra-class information including feature level locations and cross similarities between same-class instances. The proposed add-on can be added to existing methods such as the SwAV. We can later remove the add-on module for inference without any modification of the learned weights. Through an extensive set of empirical evaluations, we verify that our method yields an improved performance in detecting the class activation maps, top-1 classification accuracy, and down-stream tasks such as object detection, with different configuration settings.
Extending Momentum Contrast with Cross Similarity Consistency Regularization
Jun 07, 2022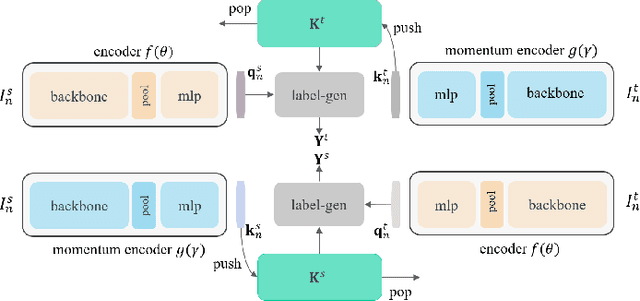
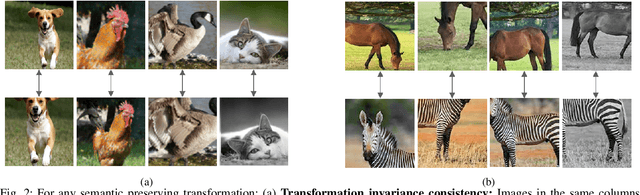
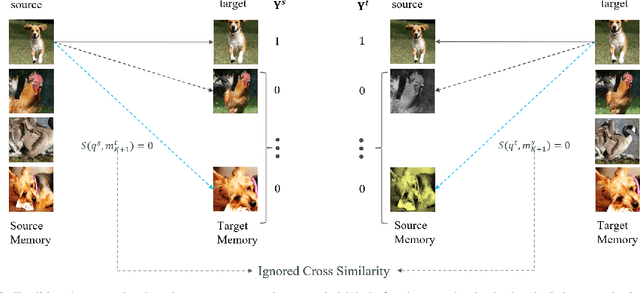
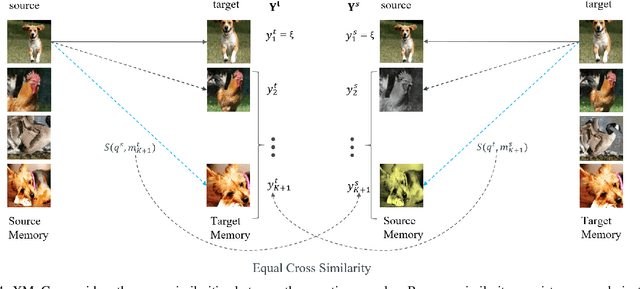
Contrastive self-supervised representation learning methods maximize the similarity between the positive pairs, and at the same time tend to minimize the similarity between the negative pairs. However, in general the interplay between the negative pairs is ignored as they do not put in place special mechanisms to treat negative pairs differently according to their specific differences and similarities. In this paper, we present Extended Momentum Contrast (XMoCo), a self-supervised representation learning method founded upon the legacy of the momentum-encoder unit proposed in the MoCo family configurations. To this end, we introduce a cross consistency regularization loss, with which we extend the transformation consistency to dissimilar images (negative pairs). Under the cross consistency regularization rule, we argue that semantic representations associated with any pair of images (positive or negative) should preserve their cross-similarity under pretext transformations. Moreover, we further regularize the training loss by enforcing a uniform distribution of similarity over the negative pairs across a batch. The proposed regularization can easily be added to existing self-supervised learning algorithms in a plug-and-play fashion. Empirically, we report a competitive performance on the standard Imagenet-1K linear head classification benchmark. In addition, by transferring the learned representations to common downstream tasks, we show that using XMoCo with the prevalently utilized augmentations can lead to improvements in the performance of such tasks. We hope the findings of this paper serve as a motivation for researchers to take into consideration the important interplay among the negative examples in self-supervised learning.