 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Confidence Contrastive Decoding for Retrieval-Augmented Generation
Jul 01, 2026Retrieval-augmented generation (RAG) increasingly requires models to answer questions from multiple retrieved documents, where only some sources are relevant and the retrieved bundle may contain stale, noisy, or conflicting evidence. Existing contrastive decoding methods primarily focus on resolving conflicts between the model's internal memory and the retrieved context. In contrast, we study the complementary problem of intra-context conflict in multi-document RAG. To evaluate this setting, we introduce DRQA, a factual-conflict question answering benchmark derived from enterprise deep-research scenarios, where answers are grounded in synthetic enterprise-specific facts that are designed not to be recoverable from the model's internal memory. We further propose Dual-Confidence Contrastive Decoding (DCCD), a training-free decoding method that combines document-level confidence, which estimates whether a document appears sufficient for answering the question, with token-level confidence, which estimates whether that document supports a confident next-token prediction. DCCD selects positive and negative document-conditioned streams using these dual-confidence signals and scales a document-level contrast by their confidence margin. Across DRQA and standard multi-document QA benchmarks, DCCD achieves the best average performance among full-context and contrastive decoding baselines, with the largest gains on DRQA. These results highlight the importance of source-aware, confidence-gated decoding when retrieved evidence is internally conflicting.
SeKV: Resolution-Adaptive KV Cache with Hierarchical Semantic Memory for Long-Context LLM Inference
Jun 30, 2026Large language models increasingly operate over long contexts, where the KV cache becomes a dominant memory bottleneck: its size grows linearly with sequence length and must be retained throughout decoding, making full GPU caching prohibitively expensive without compression. Existing KV cache compression methods struggle to balance efficiency with faithful context preservation. Token eviction discards information, while semantic grouping fixes compression decisions at prefill time; neither can recover token-level detail from a compressed span once it becomes relevant during generation. As a solution, we propose SeKV, a resolution-adaptive semantic KV cache that organizes context into entropy-guided semantic spans and stores them across a GPU-CPU memory hierarchy without discarding information. Each span keeps a lightweight summary vector on GPU for coarse routing and a low-rank SVD basis on CPU for on-demand token-level reconstruction. A trained zoom-in mechanism selectively expands query-relevant spans during decoding, enabling precise retrieval without materializing the full KV cache on GPU. SeKV enables adaptive token-level reconstruction while keeping the base LLM fully frozen and adding fewer than 0.05% trainable parameters. Across four benchmarks, SeKV improves over the strongest semantic compression baseline by 5.9% on average while reducing GPU memory by 53.3% versus full KV caching at 128K context. Code is available on https://github.com/AmirAbaskohi/SeKV.
SproutRAG: Attention-Guided Tree Search with Progressive Embeddings for Long-Document RAG
Jun 16, 2026Retrieval-augmented generation (RAG) systems must balance retrieval granularity with contextual coherence, a challenge that existing methods address through LLM-guided chunking, single-level context expansion, or hierarchical summarization. These approaches variously depend on costly LLM calls during indexing or retrieval, limit context aggregation to a single granularity level, or introduce information loss through summarization. We present SproutRAG, an attention-guided hierarchical RAG framework that addresses this trade-off by organizing sentence-level chunks into progressively larger but semantically coherent units, using learned inter-sentence attention to construct a binary chunking tree. Unlike prior approaches that rely on external LLMs, fixed context expansion, or lossy summarization, SproutRAG learns which attention heads and layers best capture semantic document structure, enabling multi-granularity retrieval without additional LLM calls or compressed summaries. At retrieval time, SproutRAG uses hierarchical beam search to retrieve candidates at multiple granularities, capturing multi-sentence relevance beyond flat retrieval. The framework is trained end-to-end with a joint objective that improves both embeddings and tree structure. Experiments across four benchmarks spanning scientific, legal, and open-domain settings demonstrate that SproutRAG improves information efficiency (IE) by 6.1% on average over the strongest baseline. Code is available on https://github.com/AmirAbaskohi/SproutRAG.
MCompassRAG: Topic Metadata as a Semantic Compass for Paragraph-Level Retrieval
Jun 16, 2026Retrieval-augmented generation (RAG) systems depend critically on how documents are chunked and searched. Fine-grained chunks can improve retrieval precision but expand the search space, increasing latency and cost; larger chunks reduce the number of candidates but make dense similarity less reliable, as the representation for each chunk mixes multiple topics and introduces more semantic noise. This trade-off becomes especially limiting in deep research tasks, where retrieval must be both fast and precise across large, heterogeneous corpora. We introduce MCompassRAG, a metadata-guided retrieval framework that uses topic-level signals as a semantic compass for selecting relevant evidence. Instead of relying only on cosine similarity between queries and noisy chunk embeddings, MCompassRAG enriches chunk representations with topic metadata in the same embedding space and trains a lightweight retriever through LLM-teacher distillation. At inference time, MCompassRAG performs topic-aware retrieval without additional LLM calls, improving both efficiency and evidence quality. Across six complex retrieval benchmarks, MCompassRAG improves information efficiency (IE) by 8.24% on average with over 5 times lower latency than the strongest efficient RAG baselines. Code is available on https://github.com/AmirAbaskohi/MCompassRAG.
The Illusion of Multi-Agent Advantage
Jun 11, 2026Prevailing wisdom posits that Multi-Agent Systems (MAS) are superior to Single-Agent Systems (SAS), citing advantages like context protection, parallel processing and distributed decision-making. However, empirical support for this claim relies primarily on comparisons with SAS baselines using benchmarks that prioritize isolated reasoning tasks, which do not adequately assess these advantages. Focusing on automatically generated MAS that are designed for enhanced generalizability over manually-designed counterparts, we perform a rigorous, systematic evaluation against SAS, specifically Chain-of-Thought with Self-Consistency (CoT-SC). Across traditional reasoning datasets and tasks with interactive multi-step workflows (e.g., BrowseComp-Plus), we demonstrate that automatic MAS consistently underperform CoT-SC despite being up to 10x more expensive. To isolate these failures from limitations inherent to task structure, we introduce a diagnostic synthetic dataset tailored for MAS featuring explicit task decomposition, context separation and parallelization potential. We show that expert-architected MAS consistently outperforms automatically generated architectures in both raw performance and cost-efficiency on this dataset, demonstrating that existing evaluation frameworks mask critical architectural gaps and inefficiencies of complex MAS by failing to account for the marginal utility of increased computational cost. Critically, systematic deconstruction of the generated MAS architectures reveals that current automated design paradigms produce architectural bloat that prioritizes superficial complexity which does not translate into functional utility, exposing a fundamental misalignment with multi-agent principles.
UnpredictaBench: A Benchmark for Evaluating Distributional Randomness in LLMs
Jun 04, 2026We introduce UnpredictaBench, an evaluation that tests the ability of large language models (LLMs) to capture true underlying distributions. As LLMs are increasingly used as substitutes for other entities (e.g., for humans in economic simulations), the tendency of many models to collapse towards a single plausible answer means a failure to capture the unpredictability of real systems. Recent work on improving output diversity is insufficient for this setting: simulation requires samples that are calibrated to a target distribution, not merely varied outputs. UnpredictaBench isolates a simplified but fundamental version of this problem: sampling outcomes from individual target distributions, including canonical statistical distributions, distributions induced by stochastic programs, and natural-language scenarios that describe random processes. We introduce 448 such problems together with KS@N, a general-purpose evaluation metric that quantifies how well a model outputs approximate black-box target distributions via the Kolmogorov-Smirnov statistical test. This is the rate at which we fail to reject model samples of size N against ground-truth samples, with larger N indicating greater difficulty. Tested across open and proprietary models, we find a large spread in distributional capabilities. For instance, when models generate samples of size 100 (KS@100, our standard metric), scores range from near 0 to over 20%. No model is able to achieve over 40% at KS@100, showing significant headroom in distributional sampling as a capability. Although adding reasoning can somewhat increase scores, we find no immediate solution for this issue. UnpredictaBench shows that even simple distributional simulation remains challenging, making it a necessary first step toward using LLMs as stand-ins for complex systems.
VAMPS: Visual-Assisted Mathematical Problem Solving Benchmark
Jun 02, 2026Multimodal large language models are increasingly capable of complex reasoning, yet their performance often degrades when they must externalize a problem through a tool and then reason over the tool's output, specifically when they rely on visual aids. This gap is especially important because real engineering and scientific workflows often rely on visualization tools for analysis, validation, and decision-making. To study this discrepancy, we introduce VAMPS (Visual-Assisted Mathematical Problem Solving), a benchmark for graph-assisted mathematics. VAMPS contains 1,168 multimodal, bilingual multiple-choice question-answer pairs drawn from Iranian University Entrance Exam algebra and calculus problems and expanded with human-reviewed LLM-generated synthetic variants, all selected so that plotting provides a natural solution strategy by revealing intersections, extrema, asymptotes, etc. Designed for both benchmarking and diagnosis, VAMPS goes beyond prior multimodal benchmarks that primarily evaluate reasoning over fixed visual inputs by testing whether a model can benefit from constructing a useful graph and grounding its answer in the resulting visualization. Overall, we found that across a diverse set of models, direct analytical solving surprisingly outperforms tool-enabled visual solving, even on problems where plotting is a natural strategy.
When Minor Edits Matter: LLM-Driven Prompt Attack for Medical VLM Robustness in Ultrasound
Mar 22, 2026Ultrasound is widely used in clinical practice due to its portability, cost-effectiveness, safety, and real-time imaging capabilities. However, image acquisition and interpretation remain highly operator dependent, motivating the development of robust AI-assisted analysis methods. Vision-language models (VLMs) have recently demonstrated strong multimodal reasoning capabilities and competitive performance in medical image analysis, including ultrasound. However, emerging evidence highlights significant concerns about their trustworthiness. In particular, adversarial robustness is critical because Med-VLMs operate via natural-language instructions, rendering prompt formulation a realistic and practically exploitable point of vulnerability. Small variations (typos, shorthand, underspecified requests, or ambiguous wording) can meaningfully shift model outputs. We propose a scalable adversarial evaluation framework that leverages a large language model (LLM) to generate clinically plausible adversarial prompt variants via "humanized" rewrites and minimal edits that mimic routine clinical communication. Using ultrasound multiple-choice question answering benchmarks, we systematically assess the vulnerability of SOTA Med-VLMs to these attacks, examine how attacker LLM capacity influences attack success, analyze the relationship between attack success and model confidence, and identify consistent failure patterns across models. Our results highlight realistic robustness gaps that must be addressed for safe clinical translation. Code will be released publicly following the review process.
BeDiscovER: The Benchmark of Discourse Understanding in the Era of Reasoning Language Models
Nov 17, 2025
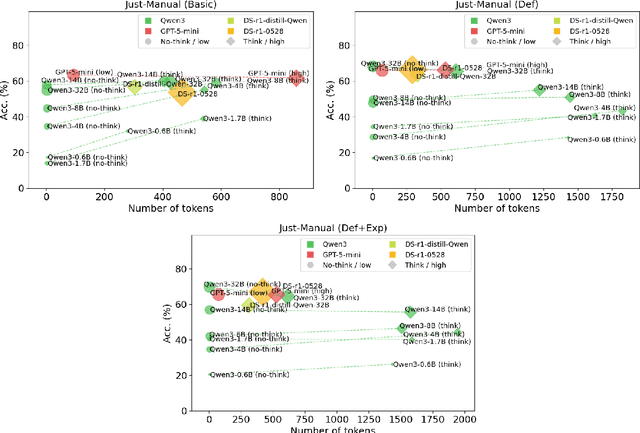
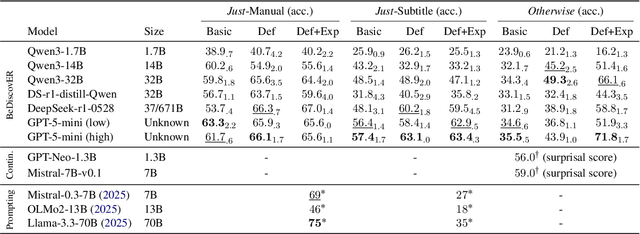
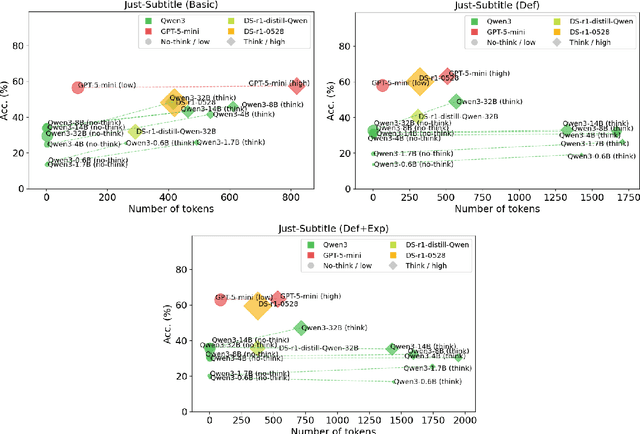
We introduce BeDiscovER (Benchmark of Discourse Understanding in the Era of Reasoning Language Models), an up-to-date, comprehensive suite for evaluating the discourse-level knowledge of modern LLMs. BeDiscovER compiles 5 publicly available discourse tasks across discourse lexicon, (multi-)sentential, and documental levels, with in total 52 individual datasets. It covers both extensively studied tasks such as discourse parsing and temporal relation extraction, as well as some novel challenges such as discourse particle disambiguation (e.g., ``just''), and also aggregates a shared task on Discourse Relation Parsing and Treebanking for multilingual and multi-framework discourse relation classification. We evaluate open-source LLMs: Qwen3 series, DeepSeek-R1, and frontier model such as GPT-5-mini on BeDiscovER, and find that state-of-the-art models exhibit strong performance in arithmetic aspect of temporal reasoning, but they struggle with full document reasoning and some subtle semantic and discourse phenomena, such as rhetorical relation recognition.
ChartGaze: Enhancing Chart Understanding in LVLMs with Eye-Tracking Guided Attention Refinement
Sep 16, 2025Charts are a crucial visual medium for communicating and representing information. While Large Vision-Language Models (LVLMs) have made progress on chart question answering (CQA), the task remains challenging, particularly when models attend to irrelevant regions of the chart. In this work, we present ChartGaze, a new eye-tracking dataset that captures human gaze patterns during chart reasoning tasks. Through a systematic comparison of human and model attention, we find that LVLMs often diverge from human gaze, leading to reduced interpretability and accuracy. To address this, we propose a gaze-guided attention refinement that aligns image-text attention with human fixations. Our approach improves both answer accuracy and attention alignment, yielding gains of up to 2.56 percentage points across multiple models. These results demonstrate the promise of incorporating human gaze to enhance both the reasoning quality and interpretability of chart-focused LVLMs.