 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentAda: Skill-Adaptive Data Analytics for Tailored Insight Discovery
Apr 10, 2025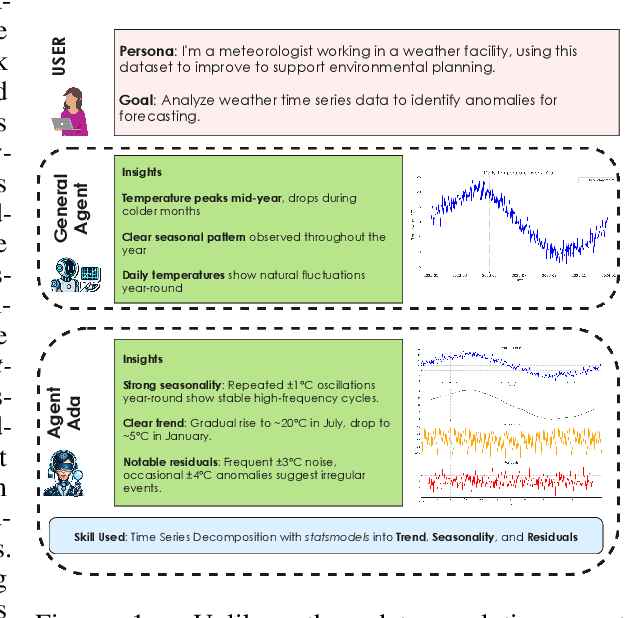

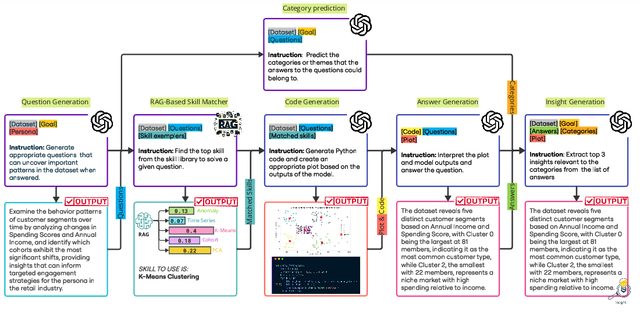
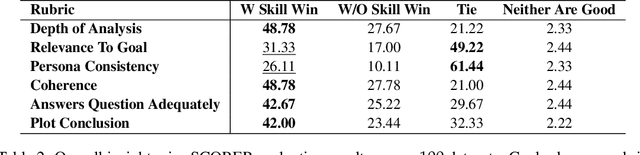
We introduce AgentAda, the first LLM-powered analytics agent that can learn and use new analytics skills to extract more specialized insights. Unlike existing methods that require users to manually decide which data analytics method to apply, AgentAda automatically identifies the skill needed from a library of analytical skills to perform the analysis. This also allows AgentAda to use skills that existing LLMs cannot perform out of the box. The library covers a range of methods, including clustering, predictive modeling, and NLP techniques like BERT, which allow AgentAda to handle complex analytics tasks based on what the user needs. AgentAda's dataset-to-insight extraction strategy consists of three key steps: (I) a question generator to generate queries relevant to the user's goal and persona, (II) a hybrid Retrieval-Augmented Generation (RAG)-based skill matcher to choose the best data analytics skill from the skill library, and (III) a code generator that produces executable code based on the retrieved skill's documentation to extract key patterns. We also introduce KaggleBench, a benchmark of curated notebooks across diverse domains, to evaluate AgentAda's performance. We conducted a human evaluation demonstrating that AgentAda provides more insightful analytics than existing tools, with 48.78% of evaluators preferring its analyses, compared to 27.67% for the unskilled agent. We also propose a novel LLM-as-a-judge approach that we show is aligned with human evaluation as a way to automate insight quality evaluation at larger scale.
Learn from Real: Reality Defender's Submission to ASVspoof5 Challenge
Oct 09, 2024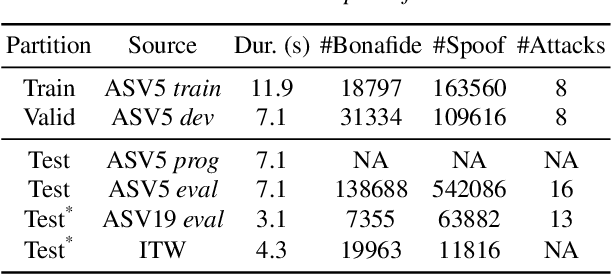
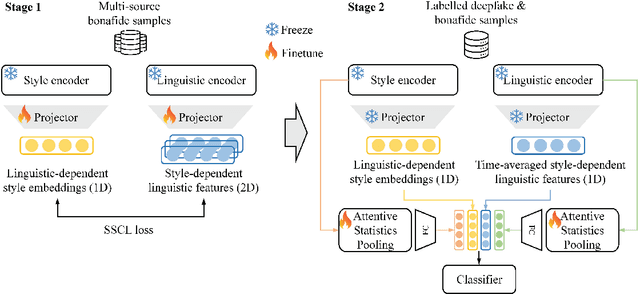
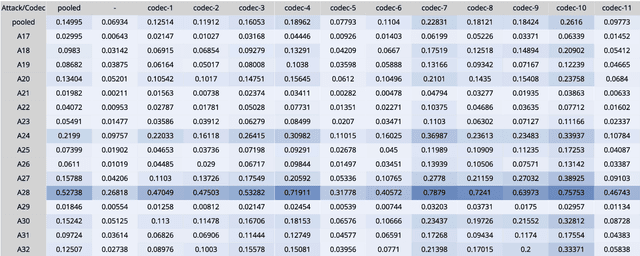
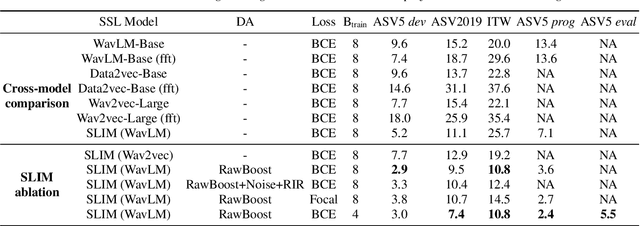
Audio deepfake detection is crucial to combat the malicious use of AI-synthesized speech. Among many efforts undertaken by the community, the ASVspoof challenge has become one of the benchmarks to evaluate the generalizability and robustness of detection models. In this paper, we present Reality Defender's submission to the ASVspoof5 challenge, highlighting a novel pretraining strategy which significantly improves generalizability while maintaining low computational cost during training. Our system SLIM learns the style-linguistics dependency embeddings from various types of bonafide speech using self-supervised contrastive learning. The learned embeddings help to discriminate spoof from bonafide speech by focusing on the relationship between the style and linguistics aspects. We evaluated our system on ASVspoof5, ASV2019, and In-the-wild. Our submission achieved minDCF of 0.1499 and EER of 5.5% on ASVspoof5 Track 1, and EER of 7.4% and 10.8% on ASV2019 and In-the-wild respectively.
Towards Attention-based Contrastive Learning for Audio Spoof Detection
Jul 03, 2024Vision transformers (ViT) have made substantial progress for classification tasks in computer vision. Recently, Gong et. al. '21, introduced attention-based modeling for several audio tasks. However, relatively unexplored is the use of a ViT for audio spoof detection task. We bridge this gap and introduce ViTs for this task. A vanilla baseline built on fine-tuning the SSAST (Gong et. al. '22) audio ViT model achieves sub-optimal equal error rates (EERs). To improve performance, we propose a novel attention-based contrastive learning framework (SSAST-CL) that uses cross-attention to aid the representation learning. Experiments show that our framework successfully disentangles the bonafide and spoof classes and helps learn better classifiers for the task. With appropriate data augmentations policy, a model trained on our framework achieves competitive performance on the ASVSpoof 2021 challenge. We provide comparisons and ablation studies to justify our claim.