 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn from Real: Reality Defender's Submission to ASVspoof5 Challenge
Paper and Code
Oct 09, 2024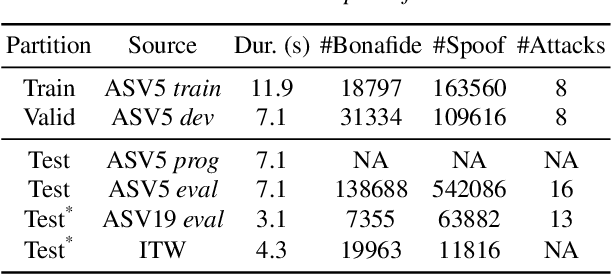
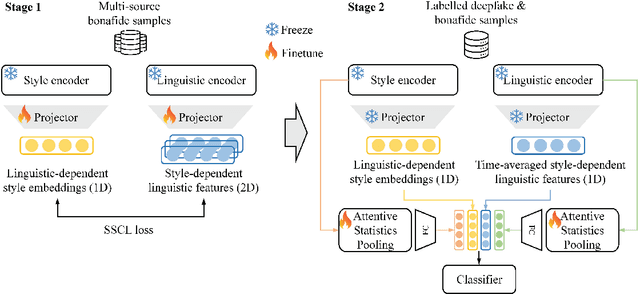
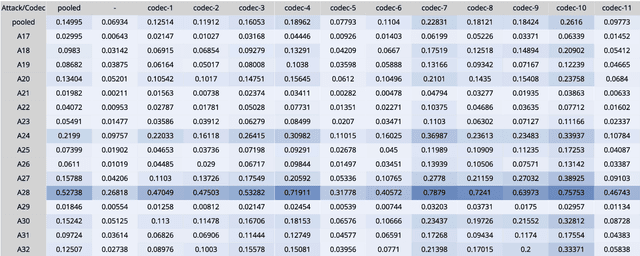
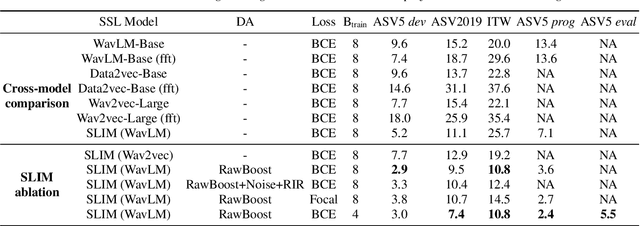
Audio deepfake detection is crucial to combat the malicious use of AI-synthesized speech. Among many efforts undertaken by the community, the ASVspoof challenge has become one of the benchmarks to evaluate the generalizability and robustness of detection models. In this paper, we present Reality Defender's submission to the ASVspoof5 challenge, highlighting a novel pretraining strategy which significantly improves generalizability while maintaining low computational cost during training. Our system SLIM learns the style-linguistics dependency embeddings from various types of bonafide speech using self-supervised contrastive learning. The learned embeddings help to discriminate spoof from bonafide speech by focusing on the relationship between the style and linguistics aspects. We evaluated our system on ASVspoof5, ASV2019, and In-the-wild. Our submission achieved minDCF of 0.1499 and EER of 5.5% on ASVspoof5 Track 1, and EER of 7.4% and 10.8% on ASV2019 and In-the-wild respectively.