 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimMark: A Robust Sentence-Level Similarity-Based Watermarking Algorithm for Large Language Models
Feb 05, 2025



The rapid proliferation of large language models (LLMs) has created an urgent need for reliable methods to detect whether a text is generated by such models. In this paper, we propose SimMark, a posthoc watermarking algorithm that makes LLMs' outputs traceable without requiring access to the model's internal logits, enabling compatibility with a wide range of LLMs, including API-only models. By leveraging the similarity of semantic sentence embeddings and rejection sampling to impose detectable statistical patterns imperceptible to humans, and employing a soft counting mechanism, SimMark achieves robustness against paraphrasing attacks. Experimental results demonstrate that SimMark sets a new benchmark for robust watermarking of LLM-generated content, surpassing prior sentence-level watermarking techniques in robustness, sampling efficiency, and applicability across diverse domains, all while preserving the text quality.
BCAmirs at SemEval-2024 Task 4: Beyond Words: A Multimodal and Multilingual Exploration of Persuasion in Memes
Apr 03, 2024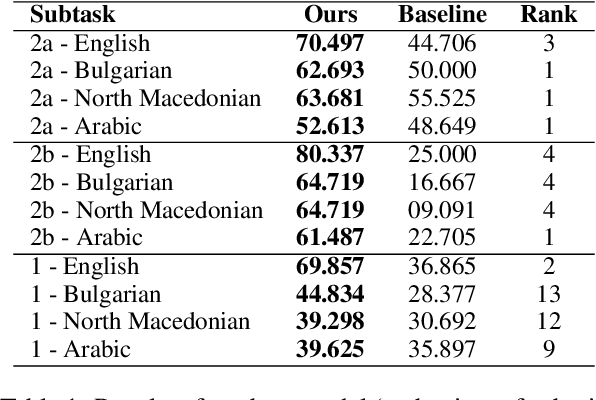

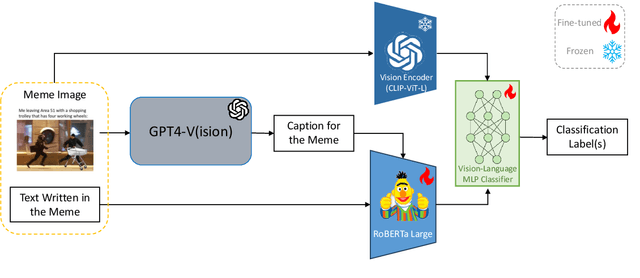
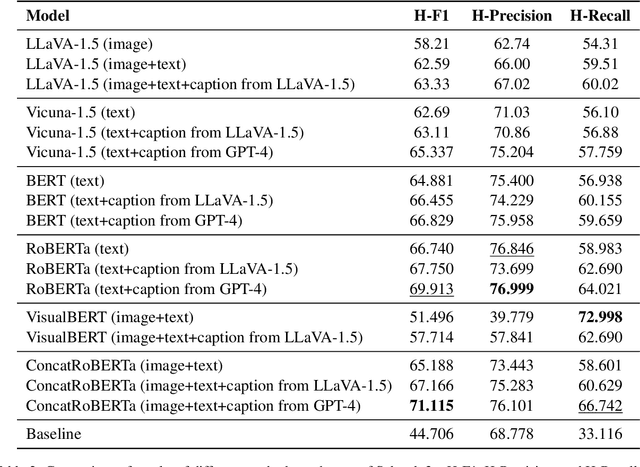
Memes, combining text and images, frequently use metaphors to convey persuasive messages, shaping public opinion. Motivated by this, our team engaged in SemEval-2024 Task 4, a hierarchical multi-label classification task designed to identify rhetorical and psychological persuasion techniques embedded within memes. To tackle this problem, we introduced a caption generation step to assess the modality gap and the impact of additional semantic information from images, which improved our result. Our best model utilizes GPT-4 generated captions alongside meme text to fine-tune RoBERTa as the text encoder and CLIP as the image encoder. It outperforms the baseline by a large margin in all 12 subtasks. In particular, it ranked in top-3 across all languages in Subtask 2a, and top-4 in Subtask 2b, demonstrating quantitatively strong performance. The improvement achieved by the introduced intermediate step is likely attributable to the metaphorical essence of images that challenges visual encoders. This highlights the potential for improving abstract visual semantics encoding.